第五章:MapReduce
文档摘要
第五章 分布式并行编程模型MapReduce 王洲烽,shenhao 5.0 洋葱辣椒酱与MapReduce   本部分为先导内容,知乎上的作者“灯火阑珊”分享的一个关于一个程序员是如何给妻子讲解什么是MapReduce的例子,可以更好地理解MapReduce,这里分享给大家!!!文章很长请耐心的看,各位小伙伴不用担心,至少这一部分是轻松愉快的,哈哈哈哈,用于引入分布式并行编程模型MapReduce!!! 小故事讲完啦,相信大家对MapReduce都有了个初步的了解,下面正式进入MapReduce的学习!!!大家冲冲冲,这部分知识是满满的干货。 5.1 概述 5.1.
第五章 分布式并行编程模型MapReduce
王洲烽,shenhao
5.0 洋葱辣椒酱与MapReduce
本部分为先导内容,知乎上的作者“灯火阑珊”分享的一个关于一个程序员是如何给妻子讲解什么是MapReduce的例子,可以更好地理解MapReduce,这里分享给大家!!!文章很长请耐心的看,各位小伙伴不用担心,至少这一部分是轻松愉快的,哈哈哈哈,用于引入分布式并行编程模型MapReduce!!!
我问妻子:“你真的想要弄懂什么是MapReduce?”她很坚定的回答说“是的。” 因此,我问道:你是如何准备洋葱辣椒酱的?(以下并非准确食谱,请勿在家尝试) 妻子: 我会取一个洋葱,把它切碎,然后拌入盐和水,最后放进混合研磨机里研磨。这样就能得到洋葱辣椒酱了。 妻子: 但这和MapReduce有什么关系? 我: 你等一下。让我来编一个完整的情节,这样你肯定可以在15分钟内弄懂MapReduce。 妻子: 好吧。

我:现在,假设你想用薄荷、洋葱、番茄、辣椒、大蒜弄一瓶混合辣椒酱。你会怎么做呢? 妻子: 我会取薄荷叶一撮,洋葱一个,番茄一个,辣椒一根,大蒜一根,切碎后加入适量的盐和水,再放入混合研磨机里研磨,这样你就可以得到一瓶混合辣椒酱了。 我: 没错,让我们把MapReduce的概念应用到食谱上。Map和Reduce其实是两种操作,我来给你详细讲解下。 Map(映射): 把洋葱、番茄、辣椒和大蒜切碎,是各自作用在这些物体上的一个Map操作。所以你给Map一个洋葱,Map就会把洋葱切碎。 同样的,你把辣椒,大蒜和番茄一一地拿给Map,你也会得到各种碎块。 所以,当你在切像洋葱这样的蔬菜时,你执行就是一个Map操作。 Map操作适用于每一种蔬菜,它会相应地生产出一种或多种碎块,在我们的例子中生产的是蔬菜块。在Map操作中可能会出现有个洋葱坏掉了的情况,你只要把坏洋葱丢了就行了。所以,如果出现坏洋葱了,Map操作就会过滤掉坏洋葱而不会生产出任何的坏洋葱块。 Reduce(化简):在这一阶段,你将各种蔬菜碎都放入研磨机里进行研磨,你就可以得到一瓶辣椒酱了。这意味要制成一瓶辣椒酱,你得研磨所有的原料。因此,研磨机通常将map操作的蔬菜碎聚集在了一起。 妻子: 所以,这就是MapReduce? 我: 你可以说是,也可以说不是。 其实这只是MapReduce的一部分,MapReduce的强大在于分布式计算。

妻子: 分布式计算? 那是什么?请给我解释下吧。 我: 没问题。 我: 假设你参加了一个辣椒酱比赛,并且你的食谱赢得了最佳辣椒酱奖。得奖之后,辣椒酱食谱大受欢迎,于是你想要开始出售自制品牌的辣椒酱。假设你每天需要生产10000瓶辣椒酱,你会怎么办呢? 妻子: 我会找一个能为我大量提供原料的供应商。 我:是的,就是那样的。那你能否独自完成制作呢?也就是说,独自将原料都切碎?仅仅一部研磨机又是否能满足需要?而且现在,我们还需要供应不同种类的辣椒酱,像洋葱辣椒酱、青椒辣椒酱、番茄辣椒酱等等。 妻子: 当然不能了,我会雇佣更多的工人来切蔬菜。我还需要更多的研磨机,这样我就可以更快地生产辣椒酱了。 我:没错,所以现在你就不得不分配工作了,你将需要几个人一起切蔬菜。每个人都要处理满满一袋的蔬菜,而每一个人都相当于在执行一个简单的Map操作。每一个人都将不断地从袋子里拿出蔬菜来,并且每次只对一种蔬菜进行处理,也就是将它们切碎,直到袋子空了为止。 这样,当所有的工人都切完以后,工作台(每个人工作的地方)上就有了洋葱块、番茄块和蒜蓉等等。 妻子:但是我怎么会制造出不同种类的番茄酱呢? 我:现在你会看到MapReduce遗漏的阶段——搅拌阶段。MapReduce将所有输出的蔬菜碎都搅拌在了一起,这些蔬菜碎都是在以key为基础的map操作下产生的。搅拌将自动完成,你可以假设key是一种原料的名字,就像洋葱一样。所以全部的洋葱keys都会搅拌在一起,并转移到研磨洋葱的研磨器里。这样,你就能得到洋葱辣椒酱了。同样地,所有的番茄也会被转移到标记着番茄的研磨器里,并制造出番茄辣椒酱。
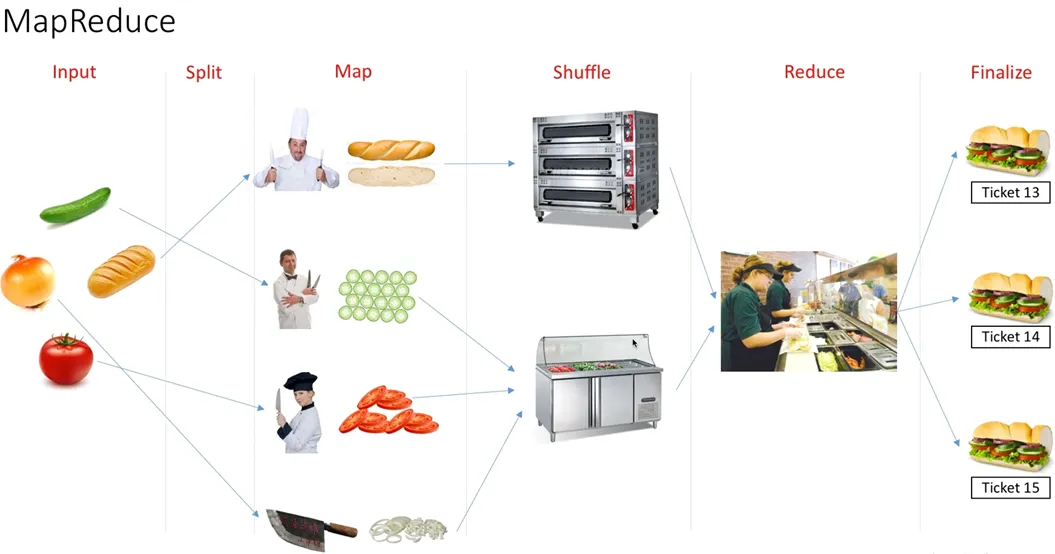
小故事讲完啦,相信大家对MapReduce都有了个初步的了解,下面正式进入MapReduce的学习!!!大家冲冲冲,这部分知识是满满的干货。

5.1 概述
5.1.1 分布式并行编程
在过去的很长一段时间里,CPU的性能都会遵循**“摩尔定律”,大约每隔18**个月性能翻一番。这意味着,不需要对程序做任何改变,仅仅通过使用更高级的CPU,程序就可以享受免费的性能提升。但是,大规模集成电路的制作工艺已经达到一个极限,从2005年开始摩尔定律逐渐失效。为了提升程序的运行性能,就不能再把希望过多地寄托在性能更高的CPU身上,于是,人们开始借助于分布式并行编程来提高程序的性能。分布式程序运行在大规模计算机集群上,集群中包括大量廉价服务器,可以并行执行大规模数据处理任务,从而获得海量的计算能力。
提升数据处理计算的能力刻不容缓!!!
分布式并行编程与传统的程序开发方式有很大的区别。传统的程序都是以单指令、单数据流的方式顺序执行,虽然这种方式比较符合人类的思维习惯,但是,这种程序的性能受到单台机器性能的限制,可扩展性较差。分布式并行程序可以运行在由大量计算机构成的集群上,从而可以充分利用集群的并行处理能力,同时,通过向集群中增加新的计算节点,就可以很容易实现集群计算能力的扩充。
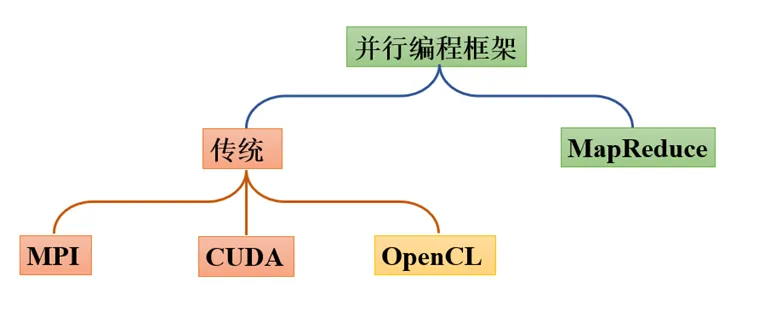
谷歌公司最先提出了分布式并行编程模型MapReduce,Hadoop MapReduce是它的开源实现。谷歌的MapReduce运行在分布式文件系统GFS上,与谷歌类似,Hadoop MapReduce运行在分布式文件系统HDFS上。相对而言,Hadoop MapReduce要比谷歌MapReduce的使用门槛低很多,程序员即使没有任何分布式程序开发经验,也可以很轻松地开发出分布式程序并部署到计算机集群中。
5.1.2 MapReduce模型简介
MapReduce将复杂的、运行于大规模集群上的并行计算过程高度抽象到了两个函数:Map和Reduce,这两个函数及其核心思想都源自函数式编程语言。
MapReduce设计的一个理念就是**“计算向数据靠拢”,而不是“数据向计算靠拢",因为数据需要大量的网络传输开销**,尤其是在大规模数据环境下,这种开销尤为惊人,所以,移动计算要比移动数据更加经济。在这种理念下,只要有可能,一个集群中的MapReduce框架就会将Map程序就近地在HDFS数据所在的节点运行,即将计算节点和存储节点放在一起运行,从而减少了节点间的数据移动开销。

MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave,Master上运行JobTracker,Slave上运行 TaskTracker。用户提交的每个计算作业,会被划分成若干个任务。
JobTracker负责作业和任务的调度,监控它们的执行,并重新调度已经失败的任务。TaskTracker负责执行由JobTracker指派的任务。
MapReduce是Hadoop中一个批量计算的框架,在整个MapReduce作业的过程中,包括从数据的输入、数据的处理、数据的输出这些部分,而其中数据的处理部分就由map、reduce、combiner等操作组成。在一个MapReduce的作业中必定会涉及到如下一些组件:
- 客户端:提交MapReduce作业
- yarn资源管理器:负责集群上计算资源的协调
- yarn节点管理器:负责启动和监控集群中机器上的计算容器(container)
- MapReduce的
application master:负责协调运行MapReduce的作业 - HDFS:分布式文件系统,负责与其他实体共享作业文件
5.1.3 Map和Reduce函数
MapReduce模型的核心是Map函数和Reduce函数,二者都是由应用程序开发者负责具体实现的。
Map函数和Reduce函数都是以<key, value>作为输入,按一定的映射规则转换成另一个或一批<key, value>进行输出。
| 函数 | 输入 | 输出 | 说明 |
|---|---|---|---|
| Map | <k1,v1> 如:<行号,”a b c”> |
List(<k2,v2>) 如:<“a”,1> |
1、将小数据集进一步解析成一批<key,value>对,输入Map函数中进行处理 2、每一个输入的<k1,v1>会输出一批<k2,v2>。<k2,v2>是计算的中间结果 |
| Reduce | <k2,List(v2)> 如:<“a”,<1,1,1>> |
<k3,v3> 如:<“a”,3> |
输入的中间结果<k2,List(v2)>中的List(v2)表示是一批属于同一个k2的value |
这里看起来好枯燥╮(╯▽╰)╭ , 举个栗子方便理解,啦啦啦啦啦啦!
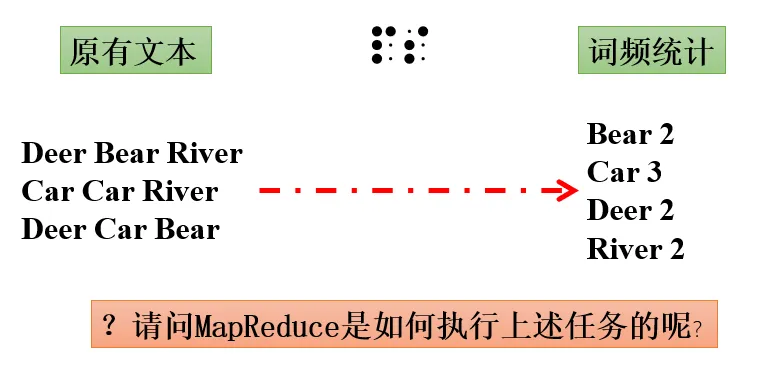
这里再给出一个简单WordCount实例
比如,我们想编写一个MapReduce程序,用于统计一个文本文件中每个单词出现的次数,具体思路如下:
- 对于
Map函数的输入<k1,v1>而言,其具体输入数据就是<某一行文本在文件中的偏移位置,该行文本的内容>。用户可以自己编写Map函数处理过程,把文件中的一行读取后解析出每个单词,输出一批中间结果<单词,出现次数>; - 然后,把这些中间结果作为
Reduce函数的输入,Reduce函数的具体处理过程也是由用户自己编写的,用户可以将相同单词的出现次数进行累加,输出每个单词出现的总次数。
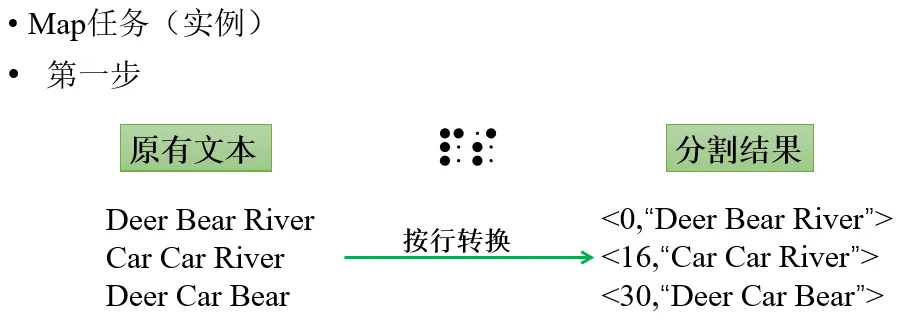
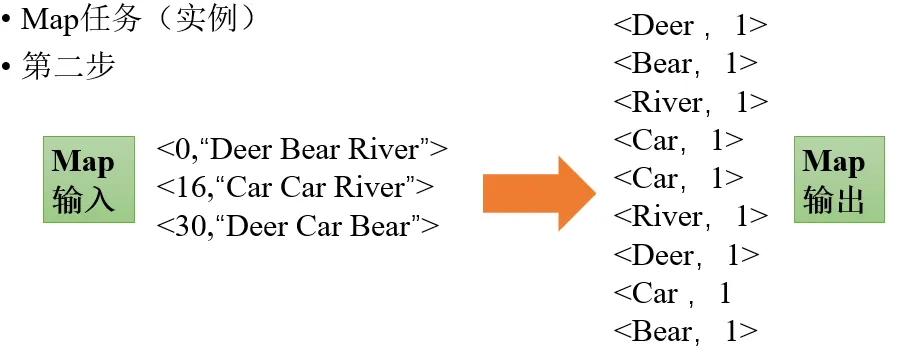
5.2 MapReduce的工作流程
ps:编者警告,以下内容十分硬核,建议买杯咖啡慎入,希望大家能坚持学下去,加油加油!!
5.2.1 工作流程概述
大规模数据集的处理包括分布式存储和分布式计算两个核心环节。谷歌公司用分布式文件系统GFS实现分布式数据存储,用MapReduce实现分布式计算,而Hadoop则使用分布式文件系统HDFS实现分布式数据存储,用Hadoop MapReduce实现分布式计算。MapReduce的输入和输出都需要借助于分布式文件系统进行存储,这些文件被分布存储到集群中的多个节点上。
MapReduce的核心思想可以用**“分而治之”**来描述,即把一个大的数据集拆分成多个小数据块在多台机器上并行处理,也就是说,一个大的MapReduce作业的处理流程如下:
首先会被拆分成许多个Map任务在多台机器上并行执行,每个Map任务通常运行在数据存储的节点上,这样,计算和数据就可以放在一起运行,不需要额外的数据传输开销。当Map任务结束后,会生成以<key,value>形式表示的许多中间结果。
然后,这些中间结果会被分发到多个Reduce任务在多台机器上并行执行,具有相同key的<key,value>会被发送到同一个Reduce任务那里,Reduce任务会对中间结果进行汇总计算得到最后结果,并输出到分布式文件系统中。

不同的Map任务之间不会进行通信,不同的Reduce任务之间也不会发生任何信息交换;用户不能显式地从一台机器向另一台继机器发送消息,所有的数据交换都是通过MapReduce框架自身去实现的。
在MapReduce的整个执行过程中,Map任务的输入文件、Reduce任务的处理结果都是保存在分布式文件系统中的,而Map任务处理得到的中间结果则保存在本地存储(如磁盘)中。
5.2.2 MapReduce的各个执行阶段
下面是一个MapReduce算法的执行过程:
- MapReduce框架使用
InputFormat模块做Map前的预处理,比如,验证输入的格式是否符合输入定义;然后,将输入文件切分为逻辑上的多个InputSplit,InputSplit是MapReduce对文件进行处理和运算的输入单位,只是一个逻辑概念,每个InputSplit并没有对文件进行实际切割,只是记录了要处理的数据的位置和长度。 - 因为
InputSplit是逻辑切分而非物理切分,所以,还需要通过RecordReader(RR)并根据InputSplit中的信息来处理InputSplit中的具体记录,加载数据并转换为适合Map任务读取的键值对,输入给Map任务。 Map任务会根据用户自定义的映射规则,输出一系列的<key,value>作为中间结果。- 为了让
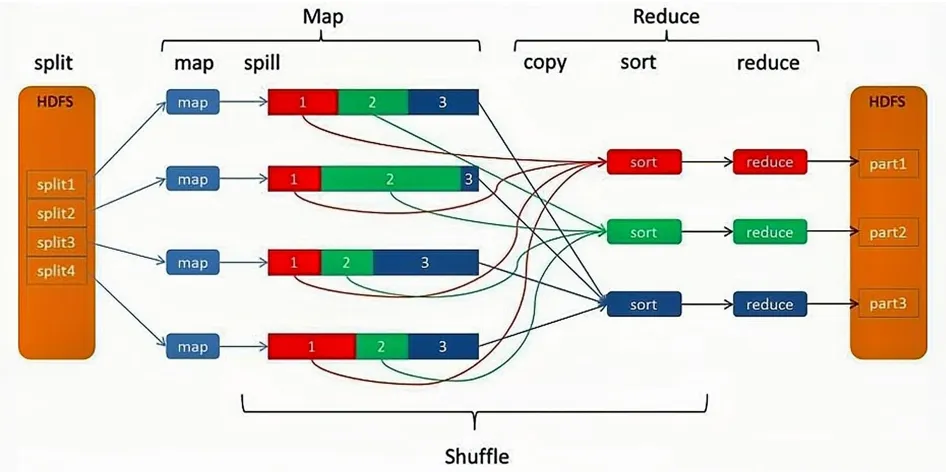
Reduce可以并行处理Map的结果,需要对Map的输出进行一定的分区、排序(Sort)、合并(Combine)和归并(Merge)等操作,得到<key,value-list>形式的中间结果,再交给对应的Reduce程序进行处理,这个过程称为Shuffle。 Reduce以一系列<key,value-list>中间结果作为输入,执行用户定义的逻辑,输出结果给OutputFormat模块。OutputFormat模块会验证输出目录是否已经存在,以及输出结果类型是否符合配置文件中的配置类型,如果都满足,就输出Reduce的结果到分布式文件系统。

坚持坚持,这才刚开始,学习使我快乐!!

5.2.3 Shuffle过程详解
5.2.3.1 Shuffle过程简介
Shuffle过程是MapReduce整个工作流程的核心环节,理解Shuffle过程的基本原理,对于理解MapReduce流程至关重要。
所谓Shuffle,是指针对Map输出结果进行分区、排序和合并等处理,并交给Reduce的过程。因此,Shuffle过程分为Map端的操作和Reduce端的操作。
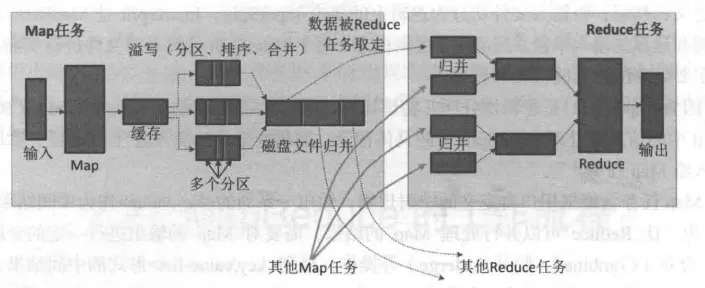
- 在
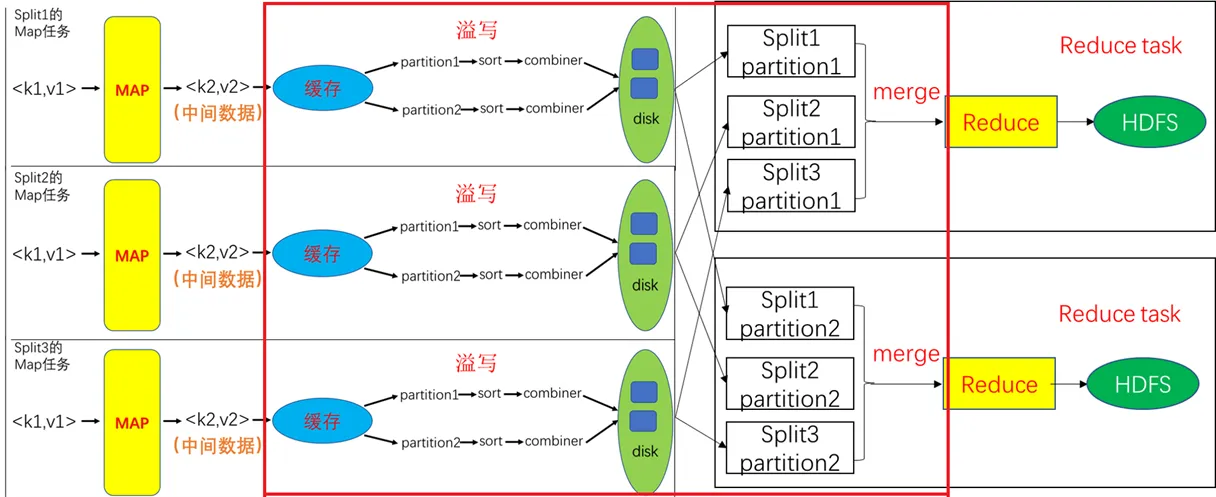
Map端的Shuffle过程。Map的输出结果首先被写入缓存,当缓存满时,就启动溢写操作,把缓存中的数据写入磁盘文件,并清空缓存。当启动溢写操作时,首先需要把缓存中的数据进行分区,然后对每个分区的数据进行排序(Sort)和合并(Combine),之后再写入磁盘文件。每次溢写操作会生成一个新的磁盘文件,随着Map任务的执行,磁盘中就会生成多个溢写文件。在Map任务全部结束之前,这些溢写文件会被归并(Merge)成一个大的磁盘文件,然后,通知相应的Reduce任务来领取属于自己需要处理的数据。
- 在
Reduce端的Shuffle过程。Reduce任务从Map端的不同Map机器领回属于自己需要处理的那部分数据,然后,对数据进行归并(Merge)后交给Reduce处理。
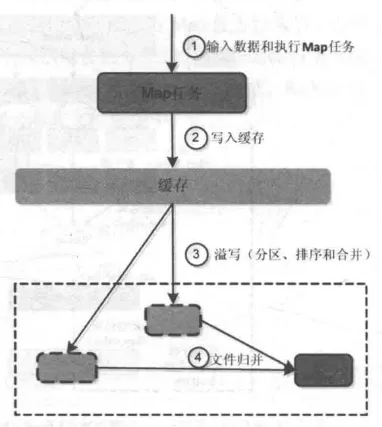
5.2.3.2 Map端的Shuffle过程
Map端的Shuffle过程包括4个步骤:
-
输入数据和执行
Map任务
Map任务的输入数据一般保存在分布式文件系统(如GFS或HDFS)的文件块中,这些文件块的格式是任意的,可以是文档,也可以是二进制格式的。Map任务接受<key,value>作为输入后,按一定的映射规则转换成一批<key,value>进行输出。 -
写入缓存
每个Map任务都会被分配一个缓存,Map的输出结果不是立即写入磁盘,而是首先写入缓存。在缓存中积累一定数量的Map输出结果以后,再一次性批量写入磁盘,这样可以大大减少对磁盘I/O的影响。因为,磁盘包含机械部件,它是通过磁头移动和盘片的转动来寻址定位数据的,每次寻址的开销很大,如果每个Map输出结果都直接写入磁盘,会引入很多次寻址开销,而一次性批量写入,就只需要一次寻址,连续写入,大大降低了开销。需要注意的是,在写入缓存之前,key与value值都会被序列化成字节数组。 -
溢写(分区、排序和合并)
提供给MapReduce的缓存的容量是有限的,默认大小是100MB。随着Map任务的执行,缓存中Map结果的数量会不断增加,很快就会占满整个缓存,这时,就必须启动溢写(Spill)操作,把缓存中的内容一次性写入磁盘,并清空缓存。溢写的过程通常是由另外一个单独的后台线程来完成的,不会影响Map结果往缓存写入。但是,为了保证Map结果能够不停地持续写入缓存,不受溢写过程的影响,就必须让缓存中一直有可用的空间,不能等到全部占满才启动溢写过程,所以,一般会设置一个溢写比例,如0.8,也就是说,当100MB大小的缓存被填满80MB数据时,就启动溢写过程,把已经写入的80MB数据写入磁盘,剩余20MB空间供Map结果继续写入。
但是,在溢写到磁盘之前,缓存中的数据首先会被分区(Partition)。缓存中的数据是<key,value>形式的键值对,这些键值对最终需要交给不同的Reduce任务进行并行处理。MapReduce通过Partitioner接口对这些键值对进行分区,默认采用的分区方式是采用Hash函数对key进行哈希后,再用Reduce任务的数量进行取模,可以表示成hash(key) mod R。其中,R表示Reduce任务的数量,这样,就可以把Map输出结果均匀地分配给这R个Reduce任务去并行处理了。当然,MapReduce也允许用户通过重载Partitioner接口来自定义分区方式。
对于每个分区内的所有键值对,后台线程会根据key对它们进行内存排序(Sort),排序是MapReduce的默认操作。排序结束后,还包含一个可选的合并(Combine)操作。如果用户事先没有定义Combiner函数,就不用进行合并操作。如果用户事先定义了Combiner函数,则这个时候会执行合并操作,从而减少需要溢写到磁盘的数据量。
所谓**“合并”,是指将那些具有相同key的<key,value>的value加起来,比如,有两个键值对<"xmu",1>和<"xmu",1>,经过合并操作以后就可以得到一个键值对<"xmu",2>,减少了键值对的数量。这里需要注意,Map端的这种合并操作,其实和Reduce的功能相似,但是,由于这个操作发生在Map端,所以,我们只能称之为“合并”,从而有别于Reduce。不过,并非所有场合都可以使用Combiner,因为,Combiner的输出是Reduce任务的输入,Combiner绝不能改变Reduce任务最终的计算结果,一般而言,累加、最大值等场景可以使用合并操作。
经过分区、排序以及可能发生的合并操作之后,这些缓存中的键值对就可以被写入磁盘,并清空缓存。每次溢写操作都会在磁盘中生成一个新的溢写文件,写入溢写文件中的所有键值对,都是经过分区和排序**的。 -
文件归并
每次溢写操作都会在磁盘中生成一个新的溢写文件,随着MapReduce任务的进行,磁盘中的溢写文件数量会越来越多。当然,如果Map输出结果很少,磁盘上只会存在一个溢写文件,但是,通常都会存在多个溢写文件。最终,在Map任务全部结束之前,系统会对所有溢写文件中的数据进行归并(Merge),生成一个大的溢写文件,这个大的溢写文件中的所有键值对,也是经过分区和排序的。
所谓归并(Merge),是指对于具有相同key的键值对,会被归并成一个新的键值对。具体而言,对于若干个具有相同key的键值对<k1,v1>、<k1,v2>......,会被归并成一个新的键值对<k1,<V1,V2,...vn>>。
另外,进行文件归并时,如果磁盘中已经生成的溢写文件的数量超过参数min.num.spills.for.combine的值时(默认值是3,用户可以修改这个值)。那么,就可以再次运行Combiner,对数据进行合并操作,从而减少写入磁盘的数据量。但是,如果磁盘中只有一两个溢写文件时,执行合并操作就会“得不偿失”,因为执行合并操作本身也需要代价,因此,不会运行Combiner。
经过上述4个步骤以后,Map端的Shuffle过程全部完成,最终生成的一个大文件会被存放在本地磁盘。这个大文件中的数据是被分区的,不同的分区会被发送到不同的Reduce任务进行并行处理。
注意:JobTracker会一直监测Map任务的执行,当监测到一个Map任务完成后,就会立即通知相关的Reduce任务来“领取”数据,然后开始Reduce端的Shuffle过程。
如果把这段知识肝完,请自称为肝帝 ╮(╯▽╰)╭
5.2.3.3 Reduce端的Shuffle过程
相对于Map端而言,Reduce端的Shuffle过程非常简单,只需要从Map端读取结果,然后执行归并操作,最后输送给Reduce任务进行处理,具体执行流程如下:
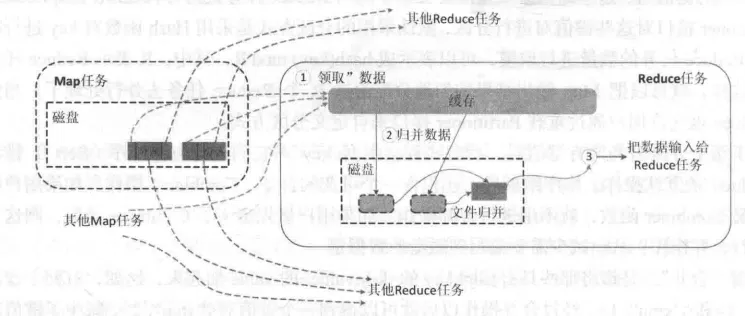
-
“领取”数据
Map端的Shuffle过程结束后,所有Map输出结果都保存在Map机器的本地磁盘上,Reduce任务需要把这些数据“领取”(Fetch)回来,存放到自己所在机器的本地磁盘上。因此,在每个Reduce任务真正开始之前,它大部分时间都在从Map端把属于自己处理那些分区的数据“领取”过来。
每个Reduce任务会不断地通过RPC(Remote Procedure Call)向JobTracker询问Map任务是否已经完成;JobTracker监测到一个Map任务完成后,就会通知相关的Reduce任务来“领取”数据;一旦一个Reduce任务收到JobTracker通知,它就会到该Map任务所在机器上把属于自己处理的分区数据领取到本地磁盘中。一般系统中会存在多个Map机器,因此,Reduce任务会使用多个线程同时从多个Map机器领回数据。 -
归并数据
从Map端领回的数据,会首先被存放在Reduce任务所在机器的缓存中,如果缓存被占满,就会像Map端一样被溢写到磁盘中。由于在Shuffle阶段,Reduce任务还没有真正开始执行,因此,这时可以把内存的大部分空间分配给Shuffle过程作为缓存。需要注意的是,系统中一般存在多个Map机器,所以,Reduce任务会从多个Map机器领回属于自己处理的那些分区的数据,因此,缓存中的数据是来自不同的Map机器的,一般会存在很多可以合并(Combine)的键值对。
当溢写过程启动时,具有相同key的键值对会被归并(Merge),如果用户定义了Combiner,则归并后的数据还可以执行合并操作,减少写入磁盘的数据量。每个溢写过程结束后,都会在磁盘中生成一个溢写文件,因此,磁盘上会存在多个溢写文件。最终,当所有的Map端数据都已经被领回时,和Map端类似,多个溢写文件会被归并成一个大文件,归并的时候还会对键值对进行排序,从而使得最终大文件中的键值对都是有序的。当然,在数据很少的情形下,缓存就可以存储所有数据,就不需要把数据溢写到磁盘,而是直接在内存中执行归并操作,然后直接输出给Reduce任务。
需要说明的是,把磁盘上的多个溢写文件归并成一个大文件,可能需要执行多轮归并操作。每轮归并操作可以归并的文件数量是由参数io.sort.factor的值来控制的(默认值是10,可以修改)。
假设磁盘中生成了50个溢写文件,每轮可以归并10个溢写文件,则需要经过5轮归并,得到5个归并后的大文件。 -
把数据输入
Reduce任务
磁盘中经过多轮归并后得到的若干个大文件,不会继续归并成一个新的大文件,而是直接输入给Reduce任务,这样可以减少磁盘读写开销。由此,整个Shuffle过程顺利结束。接下来,Reduce任务会执行Reduce函数中定义的各种映射,输出最终结果,并保存到分布式文件系统中。

emmmmmmm,笔者吐槽,以上内容实在是太太太太太硬核了,估计今天吃完饭憋得上厕所都难受,大家都是打工人,自然感同身受。没事没事没事,下面
WordCount的例子就有很多生动形象的图啦,很好理解的!!!大家坚持住,看完睡个好觉,红红火火恍恍惚惚哈哈哈。

5.3 以WordCount为例理解MapReduce
首先,需要检查WordCount程序任务是否可以采用MapReduce来实现。在前文我们曾经提到,适合用MapReduce来处理的数据集,需要满足一个前提条件:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。在WordCount程序任务中,不同单词之间的频数不存在相关性,彼此独立,可以把不同的单词分发给不同的机器进行并行处理,因此,可以采用MapReduce来实现词频统计任务。
其次,确定MapReduce程序的设计思路。思路很简单,把文件内容解析成许多个单词,然后把所有相同的单词聚集到一起。最后,计算出每个单词出现的次数进行输出。
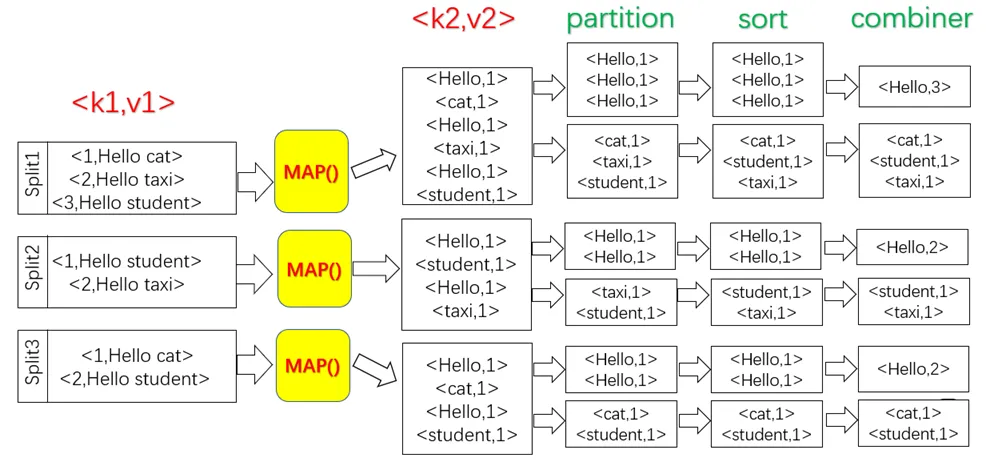
最后,确定MapReduce程序的执行过程。把一个大文件切分成许多个分片,每个分片输入给不同机器上的Map任务,并行执行完成“从文件中解析出所有单词”的任务。Map的输入采用Hadoop默认的<key, value>输入方式,即文件的行号作为key,文件的一行作为valueMap的输出以单词作为key,1作为value,即<单词,1>,表示单词出现了1次。
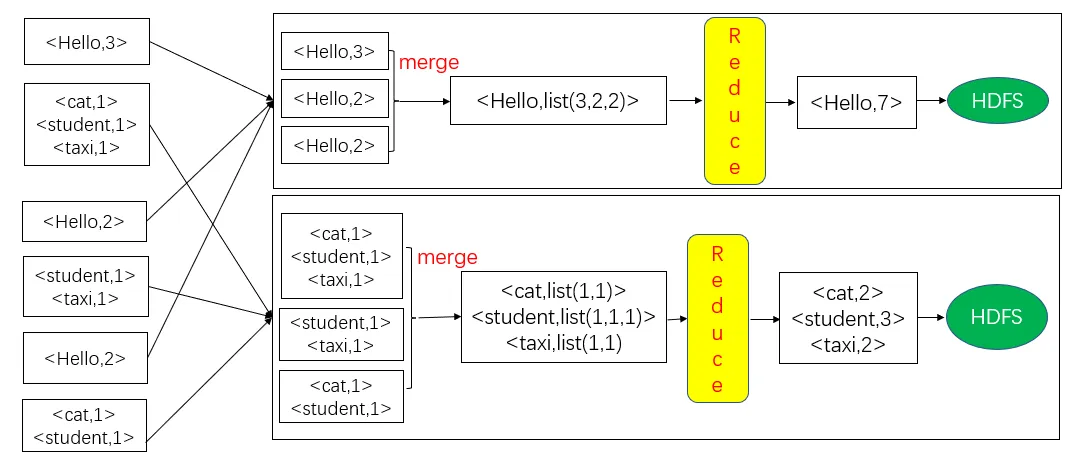
Map阶段完成后,会输出一系列<单词,1>这种形式的中间结果,然后,Shuffle阶段会对这些中间结果进行排序、分区,得到<key, value-list>的形式(比如<hadoop,<1,1,1,1,1>>),分发给不同的Reduce任务。Reduce任务接收到所有分配给自己的中间结果(一系列键值对)以后,就开始执行汇总计算工作,计算得到每个单词的频数并把结果输出到分布式文件系统。
好嘞好嘞,全是字的部分终于结束了,下面到了理解图部分,希望帮助大家理解吧,编者尽力去简单化啦。大家冲冲冲,胜利就在前面,看完这些图就能掌握MapReduce啦!!!
5.3.1 首先放一张WordCount实现过程图来控场

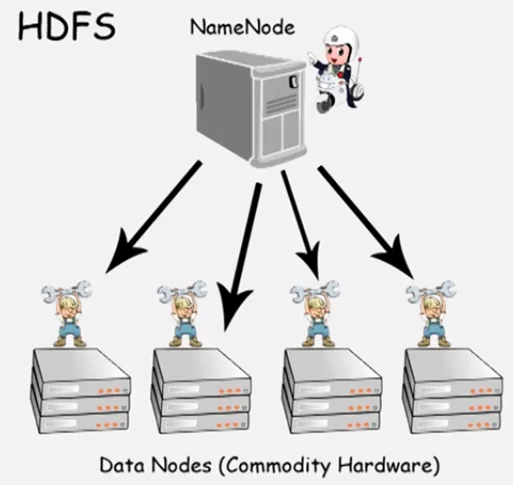
那么问题来了,MapReduce是如何对这些大批量的数据进行处理计算的呢?
答案当然是我们的old friend——HDFS
看到这里,不知道朋友们有没有回想起HDFS的知识呢? 还记得NameNode和DataNode吗?
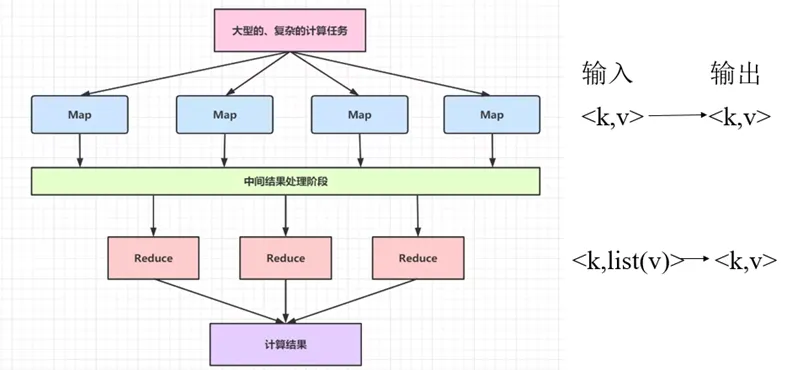
5.3.2 简易版MapReduce工作流程
5.3.3 数据分片
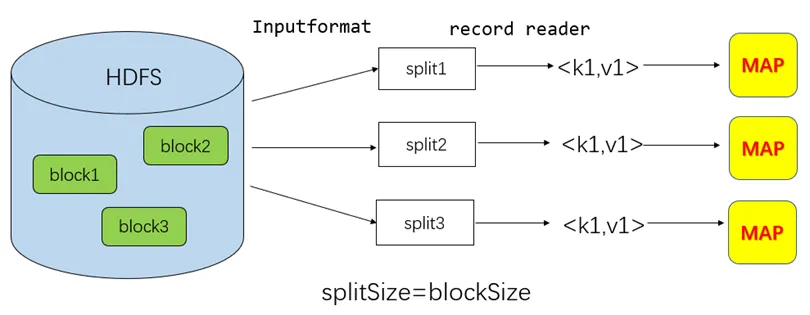
MapReduce的工作流程:
Inputformat的作用:加载、读取HDFS中的文件,对输入进行格式验证;将大文件切分成许多分片split,但此切分仅是逻辑上的切分,即逻辑定义每个split的起点和长度,并非真正意义的物理切分。record reader:记录阅读器,根据split的位置和长度,从HDFS中的各个块读取相关分片,读取成<k,v>的形式。
5.3.4 WordCount详细讲解
WordCount的数据分片
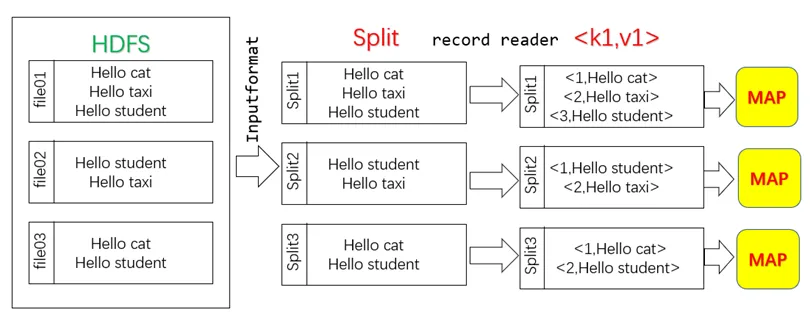
split的Map流程
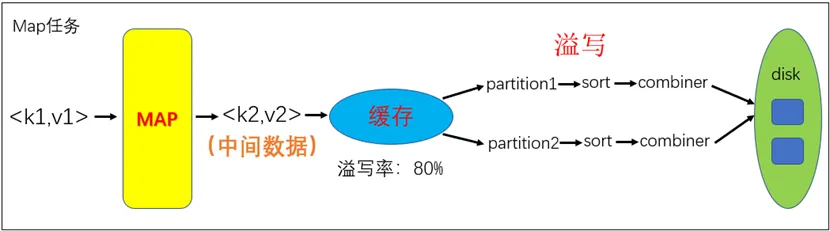
Reduce流程
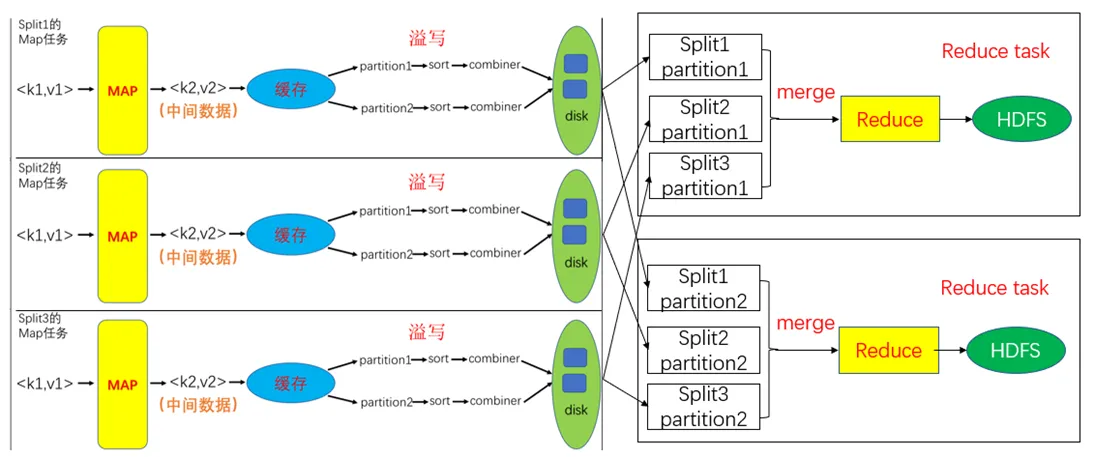
WordCount的Map流程
WordCount的Reduce流程
Shuffle过程
5.3.5 详细版MapReduce工作流程
5.3.6 MapReduce的体系结构
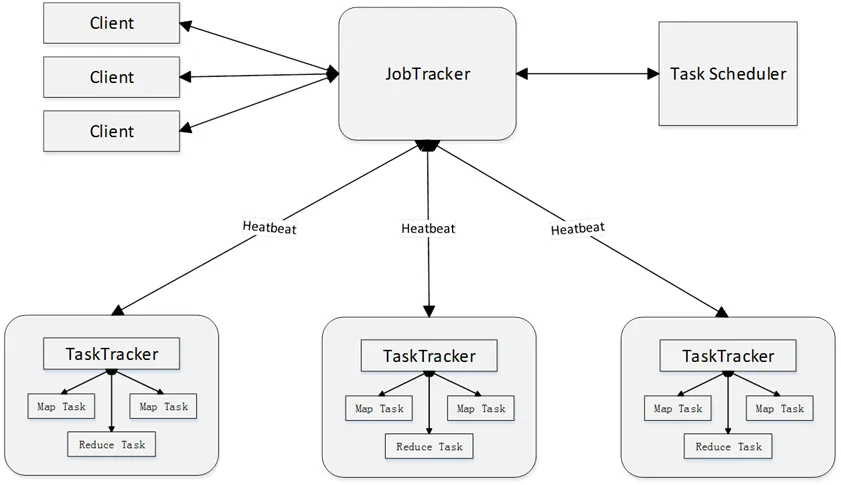
5.3.6.1 Client(客户端)
- 主要功能:负责提交作业,查看作业状态
- 提交作业:用户编写的MapReduce程序通过
Client提交到JobTracker端。 - 查看作业状态:用户可通过
Client提供的一些接口查看作业运行状态。
5.3.6.2 JobTracker(作业跟踪器)
- 主要功能:负责资源监控、作业调度
- 资源监控:
JobTracker监控所有TaskTracker与Job的健康状况,一旦发现节点失效(通信失败或节点故障),就将相应的任务转移到其他节点。 - 作业调度:
JobTracker会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而任务调度器会选择合适的(比较空闲)节点资源来执行任务。
5.3.6.3 TaskScheduler(任务调度器)
- 执行具体的相关任务,一般接收
JobTracker发送过来的命令。 - 把一些自己的资源使用情况,以及任务的运行进度通过心跳的方式,也就是
heartbeat发送给JobTracker。
5.3.6.4 TaskTracker(任务跟踪器)
TaskTracker会周期性地通过“心跳”,将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker发送过来的命令,并执行相应的操作(如启动新任务、杀死任务等)。TaskTracker使用slot等量划分本节点上的资源量(CPU、内存等)。一个Task获取到一个slot后才有机会运行,而Hadoop调度器(TaskScheduler)的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot分为Map slot和Reduce slot两种,分别供MapTask和Reduce Task使用。
终于结束了,笔者表示也编累了呜呜呜,希望大家能够理解这部分知识,好好运用MapReduce这项神器。
ps:能够认真学完的朋友们都是超人,勇敢坚持战胜困难的人生才更美丽!!!!

5.4 实验一:Mapreduce实例——WordCount
5.4.1 实验环境
1.Linux Ubuntu 22.04
2.hadoop3.3.1
3.eclipse4.7.0
5.4.2 实验内容
在安装了Hadoop和eclipse的Linux系统服务器上,完成WordCount实验。
5.4.3 实验步骤
1.在Eclipse中创建项目
首先,启动Eclipse,启动以后会弹出如下图所示界面,提示设置工作空间(workspace)。
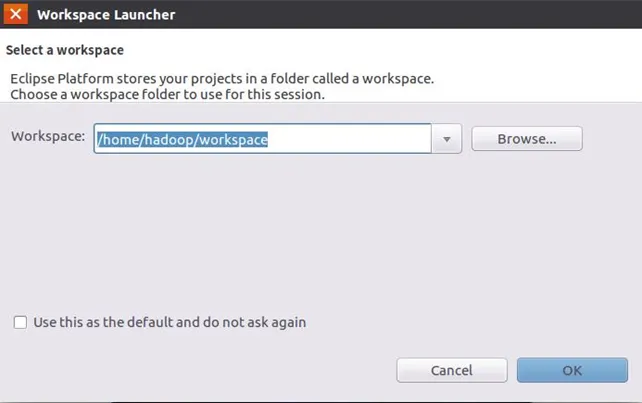
可以直接采用默认的设置“/home/hadoop/workspace”,点击“OK”按钮。 Eclipse启动以后,呈现的界面如下图所示。

选择“File–>New–>Java Project”菜单,开始创建一个Java工程,弹出如下图所示界面。
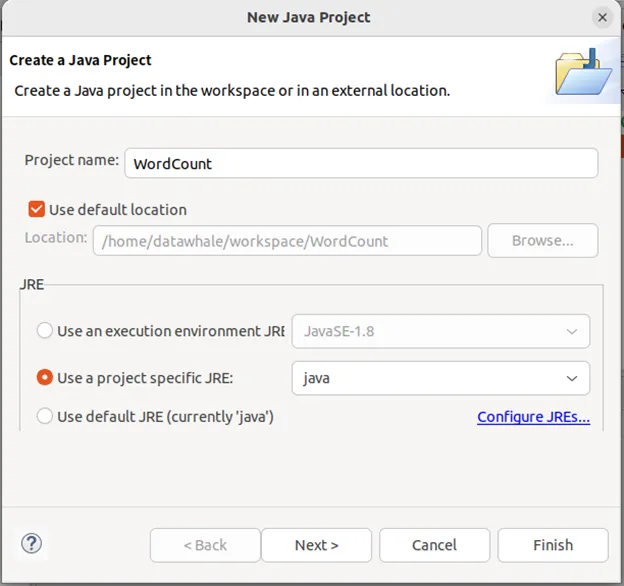
在“Project name”后面输入工程名称“WordCount”,选中“Use default location”,让这个Java工程的所有文件都保存到“/home/hadoop/workspace/WordCount”目录下。在“JRE”这个选项卡中,选择当前已经安装好的JDK:java。然后,点击界面底部的“Next>”按钮。
2.为项目添加需要用到的JAR包

在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了与Hadoop相关的Java API。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮,弹出如下图所示界面。
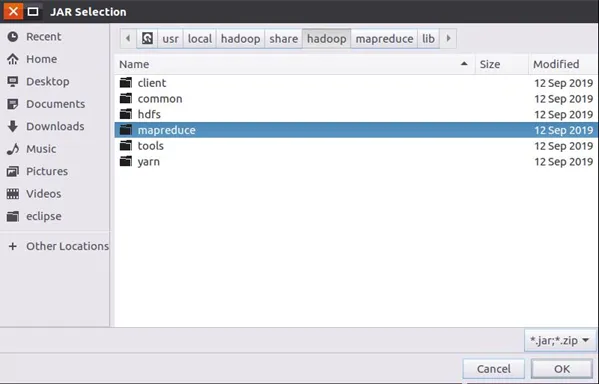
为了编写一个MapReduce程序,一般需要向Java工程中添加以下JAR包:
1、“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar 2、“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包 3、“/usr/local/hadoop/share/hadoop/mapreduce”目录下的所有JAR包 4、“/usr/local/hadoop/share/hadoop/mapreduce/lib”目录下的所有JAR包
全部添加完毕以后,就可以点击界面右下角的“Finish”按钮,完成Java工程WordCount的创建。具体如下图所示。

3.编写Java应用程序
下面编写一个Java应用程序,即WordCount.java。在Eclipse工作界面左侧的“Package Explorer”面板中(如下图所示),找到刚才创建好的工程名称“WordCount”,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择“New–>Class”菜单,再选择“New–>Class”菜单以后会出现如下图所示界面。
在该界面中,只需要在“Name”后面输入新建的Java类文件的名称,这里采用名称“WordCount”,其他都可以采用默认设置。然后,点击界面右下角“Finish”按钮,出现如下图所示界面。

可以看出,Eclipse自动创建了一个名为“WordCount.java”的源代码文件,清空该文件里面的代码,然后在该文件中输入完整的词频统计程序代码,具体如下:
import java.io.IOException; import java.util.Iterator; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public WordCount() { } public static void master(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs(); if(otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); } Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(WordCount.TokenizerMapper.class); job.setCombinerClass(WordCount.IntSumReducer.class); job.setReducerClass(WordCount.IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); for(int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true)?0:1); } public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private static final IntWritable one = new IntWritable(1); private Text word = new Text(); public TokenizerMapper() { } public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while(itr.hasMoreTokens()) { this.word.set(itr.nextToken()); context.write(this.word, one); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public IntSumReducer() { } public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; IntWritable val; for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) { val = (IntWritable)i$.next(); } this.result.set(sum); context.write(key, this.result); } } }
4.编译打包程序
现在编译上面编写的代码。可以直接点击Eclipse工作界面上部的运行程序的快捷按钮,当把鼠标移动到该按钮上时,在弹出的菜单中选择“Run as”,继续在弹出来的菜单中选择“Java Application”,如下图所示。
然后,会弹出如下图所示界面。
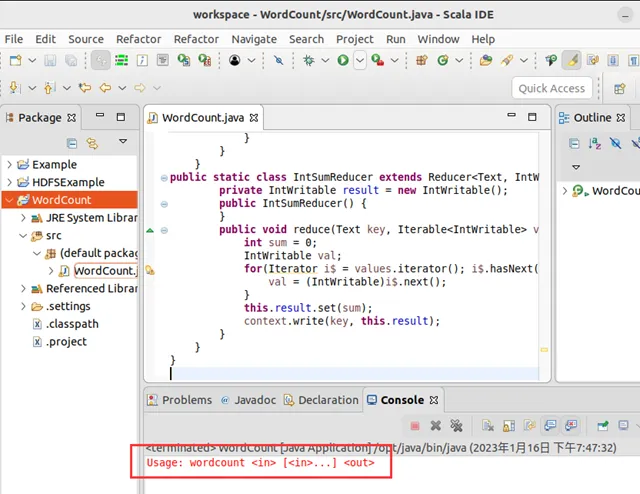
点击界面右下角的“OK”按钮,开始运行程序。程序运行结束后,会在底部的“Console”面板中显示运行结果信息(如下图所示)。
下面把Java应用程序打包生成JAR包,部署到Hadoop平台上运行。现在可以把词频统计程序放在“/opt/hadoop/myapp”目录下。如果该目录不存在,可以使用如下命令创建:
cd /opt/hadoop mkdir myapp
首先,请在Eclipse工作界面左侧的“Package Explorer”面板中,在工程名称“WordCount”上点击鼠标右键,在弹出的菜单中选择“Export”,然后,会弹出如下图所示界面。
在该界面中,选择“Runnable JAR file”,然后,点击“Next>”按钮,弹出如下图所示界面。

在该界面中,“Launch configuration”用于设置生成的JAR包被部署启动时运行的主类,需要在下拉列表中选择刚才配置的类“WordCount-WordCount”。在“Export destination”中需要设置JAR包要输出保存到哪个目录,这里设置为“/usr/local/hadoop/myapp/WordCount.jar”。在“Library handling”下面选择“Extract required libraries into generated JAR”。然后,点击“Finish”按钮,会出现如下图所示界面。
可以忽略该界面的信息,直接点击界面右下角的“OK”按钮,启动打包过程。打包过程结束后,会出现一个警告信息界面,如下图所示。

可以忽略该界面的信息,直接点击界面右下角的“OK”按钮。至此,已经顺利把WordCount工程打包生成了WordCount.jar。

5.运行程序
在运行程序之前,需要启动Hadoop,命令如下:
cd /opt/hadoop/sbin ./start-all.sh
在启动Hadoop之后,需要首先删除HDFS中与当前Linux用户datawhale对应的input和output目录(即HDFS中的“/user/datawhale/input”和“/user/datawhale/output”目录),这样确保后面程序运行不会出现问题,具体命令如下:
cd /opt/hadoop ./bin/hdfs dfs -rm -r /input ./bin/hdfs dfs -rm -r /output


然后,再在HDFS中新建与当前Linux用户datawhale对应的input目录,即“/user/ datawhale /input”目录,具体命令如下:
./bin/hdfs dfs -mkdir /input
然后,把之前在第7.1节中在Linux本地文件系统中新建的两个文件wordfile1.txt和wordfile2.txt(假设这两个文件位于“/opt/hadoop/mytext”目录下,并且里面包含了一些英文语句),上传到HDFS中的“/user/datawhale/input”目录下,命令如下:
./bin/hdfs dfs -put /opt/hadoop/mytext/wordfile1.txt /input ./bin/hdfs dfs -put /opt/hadoop/mytext/wordfile2.txt /input

如果HDFS中已经存在“/user/hadoop/output”,则使用如下命令删除:
./bin/hdfs dfs -rm -r /user/hadoop/output
现在,就可以在Linux系统中,使用hadoop jar命令运行程序,命令如下:
./bin/hadoop jar ./myapp/WordCount.jar /input output
上面命令执行以后,当运行顺利结束时,屏幕上会显示类似如下的信息:
词频统计结果已经被写入了HDFS的“/user/datawhale/output”目录中,可以执行如下命令查看词频统计结果:
./bin/hdfs dfs -cat /output/*
上面命令执行后,会在屏幕上显示如下词频统计结果:

至此,词频统计程序顺利运行结束。需要注意的是,如果要再次运行WordCount.jar,需要首先删除HDFS中的output文件,否则会报错。
6.问题与讨论
1、理解Hadoop中MapReduce模块的处理逻辑。编写MapReduce程序,实现单词出现次数统计。统计结果保存到hdfs的output文件夹,并获取统计结果。
2、注意到程序编写时要留意外界的文件是否清空干净,有时程序正确也会因冲突而产生报错
3、编写MapReduce的Java程序时困难重重,整体编写结束后收获颇丰,对整个MapReduce的架构有了更深刻的认识
4、要检查工程文件是否移入相应的位置,内容是否有误写
5、程序崩溃后强制退出程序,删除之前的输出文件,重新执行
5.5 本章小结
在本章的学习中,主要介绍了MapReduce模型的具体工作原理,并以单词统计(WordCount程序)为示例,讲解了MapReduce程序设计方法,通过编程实践,加深了对MapReduce工作流程的理解。
笔者本章内容认为十分硬核也十分重要,需要好好理解。