Task2 GloVe简介
文档摘要
CS224N Word Vectors 2 and Word Senses 引言 Word2vec回顾、优化、基于统计的词向量、GloVe、词向量评价、词义 基于统计的词向量 词向量目的:希望通过低维稠密向量来表示词的含义 t2 课程中举了一个例子:三个句子,比如对于like这个词,在三个句子中,其左右共出现2次I,1次deep和1次NLP,所以like对应的词向量中,I、deep和NLP维的值分别为2,1,1。 不足点 但这些预训练模型也存在不足: 词梳理很多时,矩阵很大,维度很高,需要的存储空间也很大 当词的数目是在不断增长,则词向量的维度也在不断增长 矩阵很稀疏,即词向量很稀疏,会遇到稀疏计算的问题 https://pdfs.semanticscholar.
CS224N Word Vectors 2 and Word Senses
引言
Word2vec回顾、优化、基于统计的词向量、GloVe、词向量评价、词义
基于统计的词向量
词向量目的:希望通过低维稠密向量来表示词的含义
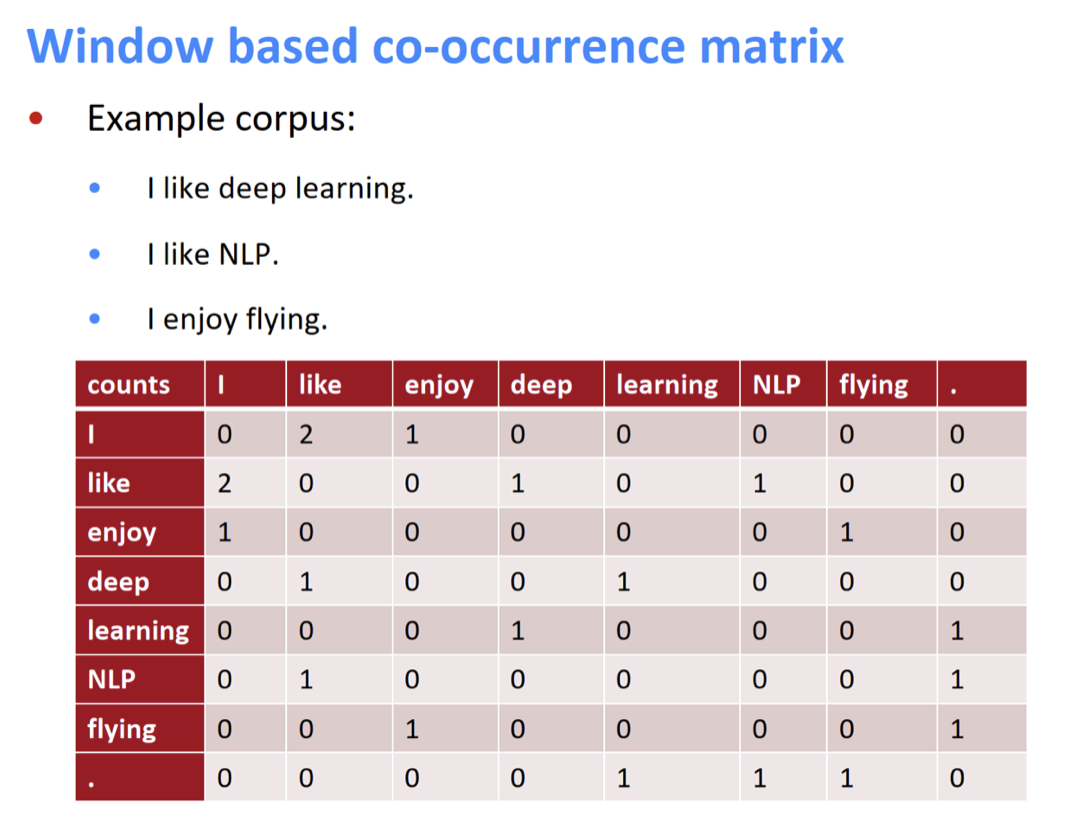
课程中举了一个例子:三个句子,比如对于like这个词,在三个句子中,其左右共出现2次I,1次deep和1次NLP,所以like对应的词向量中,I、deep和NLP维的值分别为2,1,1。
不足点
但这些预训练模型也存在不足:
- 词梳理很多时,矩阵很大,维度很高,需要的存储空间也很大
- 当词的数目是在不断增长,则词向量的维度也在不断增长
- 矩阵很稀疏,即词向量很稀疏,会遇到稀疏计算的问题
https://pdfs.semanticscholar.org/73e6/351a8fb61afc810a8bb3feaa44c41e5c5d7b.pdf
上述链接中的文章对例子中简单的计数方法进行了改进,包括去掉停用词、使用倾斜窗口、使用皮尔逊相关系数等,提出了COALS模型,该模型得到的词向量效果也不错,具有句法特征和语义特征。
GloVe
GloVe的全称是GloVe: bal Vectors for Word Representation
是这门课的老师Christopher D. Manning的研究成果
GloVe目标是综合基于统计和基于预测的两种方法的优点。
模型目标:词进行向量化表示,使得向量之间尽可能多地蕴含语义和语法的信息
流程:输入语料库--> 统计共现矩阵--> 训练词向量-->输出词向量
构建统计共现矩阵X
i表示上下文单词
j表示在特定大小的上下文窗口(context window)内共同出现的次数。这个次数的最小单位是1,但是GloVe不这么认为:它根据两个单词在上下文窗口的距离dd.
提出了一个衰减函数(decreasing weighting):用于计算权重,也就是说距离越远的两个单词所占总计数(total count)的权重越小。
构建词向量和共现矩阵之间的关系
其中, w_{i}^{T} 和 \tilde{w}_{j} 是我们最终要求解的词向量; b_{i} 和 \tilde{b}_{j} 分别是两个词向量的bias term
那它到底是怎么来的,为什么要使用这个公式?为什么要构造两个词向量 w_{i}^{T} 和 \tilde{w}_{j} ?
有了上述公式之后,我们可以构建Loss function:
loss function的基本形式就是最简单的mean square loss,只不过在此基础上加了一个权重函数 f\left(X_{i j}\right) ,那么这个函数起了什么作用,为什么要添加这个函数呢?我们知道在一个语料库中,肯定存在很多单词他们在一起出现的次数是很多的(frequent co-occurrences),那么我们希望:
- 这些单词的权重要大于那些很少在一起出现的单词,因此这个函数要是非递减函数(non-decreasing);
- 但这个权重也不能过大,当到达一定程度之后当不再增加;
- 如果两个单词没有在一起出现,也就是X_{i j},那么他们应该不参与到loss function的计算当中去,也就是f(x)要满足f(x)=0
为此,作者提出了以下权重函数:
实验中作者设定x_{\max }=100,并且发现\alpha=3 / 4时效果比较好。