第2章马尔可夫决策过程
文档摘要
第2章 马尔可夫决策过程 $\qquad$ 在第 $1$ 章中我们了解到强化学习是解决序列决策问题的有效方法,而序列决策问题的本质是在与环境交互的过程中学习到一个目标的过程。在本章中,我们将介绍强化学习中最基本的问题模型,即马尔可夫决策过程($\text{Markov decision process,MDP}$),它能够以数学的形式来表达序列决策过程。注意,从本章开始会涉及理论公式推导,建议读者在阅读之前先回顾一下概率论相关知识,尤其是条件概率、全概率期望公式等等。 2.1 马尔可夫决策过程 $\qquad$ 马尔可夫决策过程是强化学习的基本问题模型之一,它能够以数学的形式来描述智能体在与环境交互的过程中学到一个目标的过程。
第2章 马尔可夫决策过程
\qquad 在第 1 章中我们了解到强化学习是解决序列决策问题的有效方法,而序列决策问题的本质是在与环境交互的过程中学习到一个目标的过程。在本章中,我们将介绍强化学习中最基本的问题模型,即马尔可夫决策过程(\text{Markov decision process,MDP}),它能够以数学的形式来表达序列决策过程。注意,从本章开始会涉及理论公式推导,建议读者在阅读之前先回顾一下概率论相关知识,尤其是条件概率、全概率期望公式等等。
2.1 马尔可夫决策过程
\qquad 马尔可夫决策过程是强化学习的基本问题模型之一,它能够以数学的形式来描述智能体在与环境交互的过程中学到一个目标的过程。这里智能体充当的是作出决策或动作,并且在交互过程中学习的角色,环境指的是智能体与之交互的一切外在事物,不包括智能体本身。
\qquad 例如,我们要学习弹钢琴,在这个过程中充当决策者和学习者的我们人本身就是智能体,而我们的交互主体即钢琴就是环境。当我们执行动作也就是弹的时候会观测到一些信息,例如琴键的位置等,这就是状态。此外当我们弹下去的时候会收到钢琴发出的声音,也就是反馈,我们通过钢琴发出的声音来判断自己弹得好不好然后反思并纠正下一次弹的动作。当然如果这时候有一个钢琴教师在旁边指导我们,那样其实钢琴和教师就同时组成了环境,我们也可以交互过程中接收教师的反馈来提高自己的钢琴水平。
\qquad 如图 \text{2-1} 所示,它描述了马尔可夫决策过程中智能体与环境的交互过程。智能体每一时刻都会接收环境的状态,并执行动作,进而接收到环境反馈的奖励信号和下一时刻的状态。
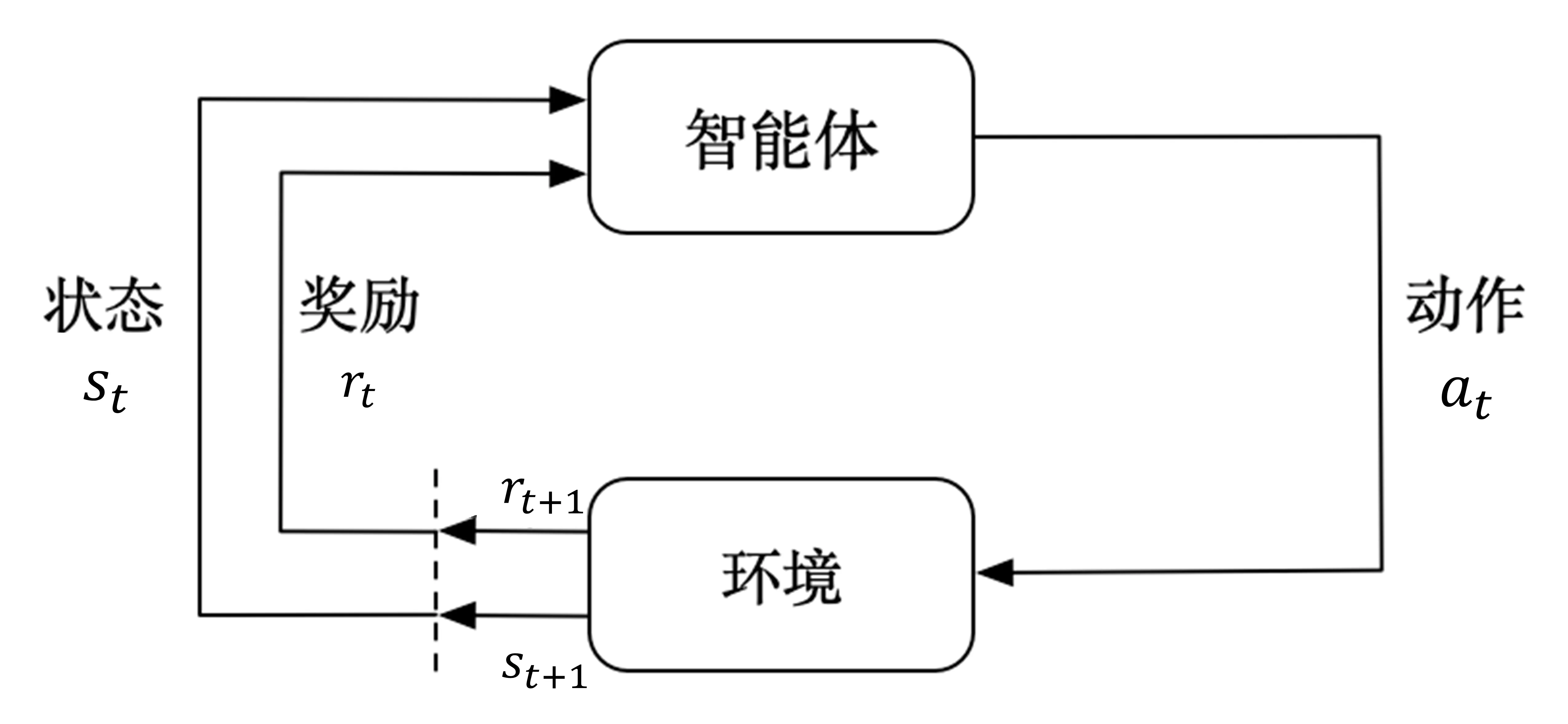
\qquad 确切地说,智能体与环境之间是在一系列离散的时步 ①( \text{time step} )交互的,一般用 t 来表示,t=0,1,2,\cdots②。在每个时步 t, 智能体会观测或者接收到当前环境的状态 s_t,根据这个状态 s_t 执行动作 a_t。执行完动作之后会收到一个奖励 r_{t+1} ③,同时环境也会收到动作 a_t 的影响会变成新的状态 s_{t+1},并且在 t+1 时步被智能体观测到。如此循环下去,我们就可以在这个交互过程中得到一串轨迹,如式 \text{(2.1)} 所示。
\qquad 其中奖励 r_{t+1} 就相当于我们学习弹钢琴时收到的反馈,我们弹对了会收到老师的表扬,相当于一个正奖励,弹错了可能会接受老师的批评,相当于一个负奖励。此外,在强化学习中我们通常考虑的是有限马尔可夫决策过程( \text{Finite MDP} ),即 t 是有限的,这个上限一般用 T 表示,也就是当前交互过程中的最后一个时步或最大步数,从 t=0 和 t+T 这一段时步我们称为一个回合( \text{episode} ),比如游戏中的一局。
① 有些方法可以拓展到连续时间的情况,但为了方便,我们尽量只考虑离散时步的情况。
② 注意,这里的 t=0 和 t=1 之间是跟现实时间无关的,取决于智能体每次交互并获得反馈所需要的时间,比如在弹钢琴的例子中我们是能够实时接收到反馈的,但是比如我们的目标是考试拿高分的时候,每次考完试我们一般是不能立刻接收到反馈即获得考试分数的,这种情况下 t=0 和 t=1 之间会显得特别漫长。
③ 这里奖励表示成 r_{t+1} 而不是 r_{t} ,是因为此时的奖励是由于动作a_t和状态s_t来决定的,也就是执行完动作之后才能收到奖励,因此更强调是下一个时步的奖励。此外,有些相关资料中奖励可能会写成大写的形式 R_{t+1},这是因为实际问题中奖励可能是一个随机变量或函数,而不是一个确定的值,因此用大写表示,在本书前几章考虑读者可能还不太熟悉概率论相关知识,因此我们用小写的形式来表示奖励。
2.2 马尔可夫性质
\qquad 现在我们介绍马尔可夫决策过程的一个前提,即马尔可夫性质,如式 \text{(2.2)} 所示。
\qquad 这个公式的意思就是在给定历史状态s_0, s_1,\cdots,s_t的情况下,某个状态的未来只与当前状态s_t有关,与历史的状态无关。这个性质其实对于很多问题有着非常重要的指导意义的,因为这允许我们在没有考虑系统完整历史的情况下预测和控制其行为,随着我们对强化学习的深入会越来越明白这个性质的重要性。实际问题中,有很多例子其实是不符合马尔可夫性质的,比如我们所熟知的棋类游戏,因为在我们决策的过程中不仅需要考虑到当前棋子的位置和对手的情况,还需要考虑历史走子的位置例如吃子等。
\qquad 换句话说,它们不仅取决于当前状态,还依赖于历史状态。当然这也并不意味着完全不能用强化学习来解决,实际上此时我们可以用深度学习神经网络来表示当前的棋局,并用蒙特卡洛搜索树等技术来模拟玩家的策略和未来可能的状态,来构建一个新的决策模型,这就是著名的 \text{AlphaGO} 算法④。具体的技术细节后面会展开,总之记住在具体的情境下,当我们要解决问题不能严格满足马尔可夫性质的条件时,是可以结合其他的方法来辅助强化学习进行决策的。
④ Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N., Sutskever, I., Lillicrap, T., Leach, M., Kavukcuoglu, K., Graepel, T. & Hassabis, D. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529, 484--.
2.3 回报
\qquad 前面讲到在马尔可夫决策过程中智能体的目标是最大化累积的奖励,通常我们把这个累积的奖励称为回报(Return),用 G_t 表示,最简单的回报公式可以写成式 \text{(2.3)}。
\qquad 其中 T 前面提到过了,表示最后一个时步,也就是每回合的最大步数。这个公式其实只适用于有限步数的情境,例如玩一局游戏,无论输赢每回合总是会在有限的步数内会以一个特殊的状态结束,这样的状态称之为终止状态。但也有一些情况是没有终止状态的,换句话说智能体会持续与环境交互,比如人造卫星在发射出去后会一直在外太空作业直到报废或者被回收,这样的任务称之为持续性任务。在持续性任务中上面的回报公式是有问题的,因为此时 T=\infty。
\qquad 为了解决这个问题,我们引入一个折扣因子(discount factor)\gamma,并可以将回报表示为式 \text{(2.4)}。
\qquad 其中\gamma 取值范围在 0 到 1 之间,它表示了我们在考虑未来奖励时的重要程度,控制着当前奖励和未来奖励之间的权衡。换句话说,它体现了我们对长远目标的关注度。当 \gamma=0 时,我们只会关心当前的奖励,而不会关心将来的任何奖励。而当 \gamma 接近 1 时,我们会对所有未来奖励都给予较高的关注度。
\qquad 这样做的好处是会让当前时步的回报 G_t 跟下一个时步 G_{t+1} 的回报是有所关联的,如式 \text{(2.5)} 所示。
这个公式对于所有 t<T 都是存在的,在后面我们讲贝尔曼公式时就会深入理解它的重要性。
2.4 状态转移矩阵
\qquad 注意,到目前为止我们讲的都是有限状态马尔可夫决策过程( \text{finite MDP} ),即状态的数量必须是有限的(无论是离散的还是连续的。如果状态数是无限的,此时通常会用另一种方式来对问题进行建模,称之为泊松( \text{Poisson} )过程,又称为连续时间马尔可夫过程。然而在绝大部分强化学习实践场景中,泊松过程并不常见,对相关理论感兴趣的读者可自行研究。
\qquad 既然状态数有限,我们就可以用一种状态流向图的形式表示智能体与环境交互过程中的走向。举个例子,学生在上课时一般会有三种状态,认真听讲、玩手机和睡觉,分别用s_1,s_2 和 s_3 表示。我们知道在马尔可夫决策过程中一般所有状态之间都是可以相互切换的,当学生在认真听讲时能切换到玩手机或者睡觉的状态,在睡觉时也可能继续睡觉,也可能醒过来认真听讲或者玩手机。如图 2.2 所示,图中每个曲线箭头表示指向自己,比如当学生在认真听讲即处于状态 s_1 时,会有 0.2 的概率继续认真听讲。当然也会分别有 0.4 和 0.4 的概率玩手机(s_2)或者睡觉(s_3)。此外,当学生处于状态 s_2 时,也会有 0.2 的概率会到认真听讲的状态(s_1),像这种两个状态之间能互相切换的情况我们用一条没有箭头的线连接起来,参考无向图的表示。
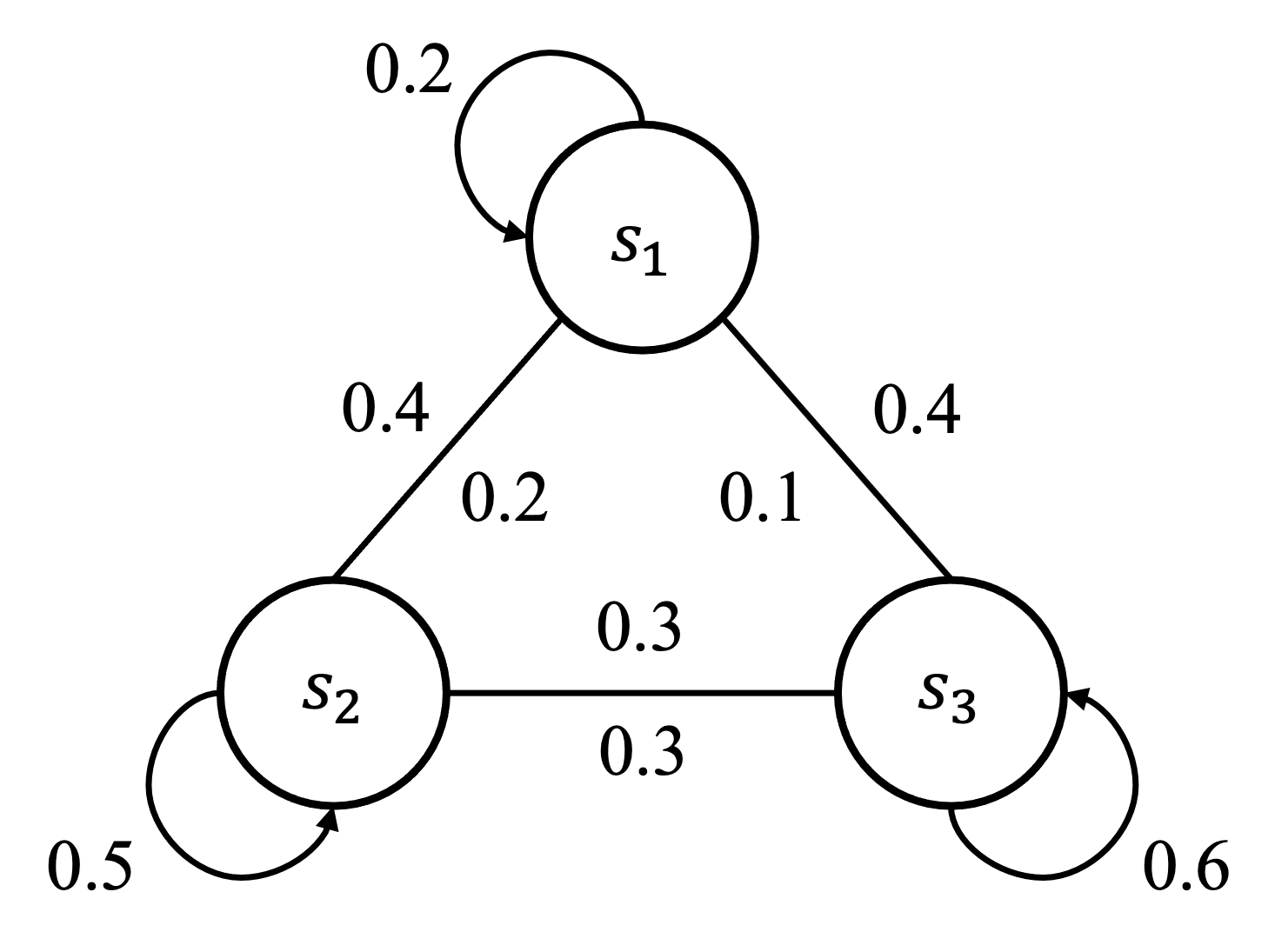
\qquad 整张图表示了马尔可夫决策过程中的状态流向,这其实跟数字电路中有限状态机的概念是一样的。严格意义上来讲,这张图中并没有完整地描述出马尔可夫决策过程,因为没有包涵动作、奖励等元素,所以一般我们称之为马尔可夫链(Markov Chain),又叫做离散时间的马尔可夫过程(Markov Process),跟马尔可夫决策过程一样,都需要满足马尔可夫性质。因此我们可以用一个概率来表示状态之间的切换,比如 P_{12}=P(S_{t+1}=s_2 | S_{t}=s_1) = 0.4 表示当前时步的状态是 s_1 ,即认真听讲时在下一个时步切换到 s_2 即玩手机的概率,我们把这个概率称为状态转移概率(State Transition Probability)。拓展到所有状态我们可以表示为式 \text{(2.6)}。
\qquad 即当前状态是 s 时,下一个状态是 s'的概率,其中大写的 S 表示所有状态的集合,即 S=\{s_1,s_2,s_3\} 。
\qquad 由于状态数是有限的,我们可以把这些概率绘制成表格的形式,如表 2.1 所示。
| $\space$ | $S_{t+1} = s_1$ | $S_{t+1} = s_2$ | $S_{t+1} = s_3$ |
|---|---|---|---|
| $S_t = s_1$ | $0.2$ | $0.4$ | $0.4$ |
| $S_t = s_2$ | $0.2$ | $0.5$ | $0.3$ |
| $S_t = s_3$ | $0.1$ | $0.3$ | $0.6$ |
\qquad 在数学上也可以用矩阵来表示,如下:
\qquad 这个矩阵就叫做状态转移矩阵(State Transition Matrix),拓展到所有状态可表示为式 \text{(2.7)}。
\qquad 其中 n 表示状态数,注意对于同一个状态所有状态转移概率加起来是等于 1 的,比如对于状态 s_1 来说,p_{11}+ p_{12}+ \cdots+p_{1n}=1。还有一个非常重要的点就是,状态转移矩阵是环境的一部分,跟智能体是没什么关系的,而智能体会根据状态转移矩阵来做出决策。在这个例子中老师是智能体,学生的状态不管是认真听讲、玩手机还是睡觉这些老师是无法决定的,老师只能根据学生的状态做出决策,比如看见学生玩手机就提醒一下上课认真听讲等等。
\qquad 此外,在马尔可夫链(马尔可夫过程)的基础上增加奖励元素就会形成马尔可夫奖励过程(Markov reward process, MRP),在马尔可夫奖励过程基础上增加动作的元素就会形成马尔可夫决策过程,也就是强化学习的基本问题模型之一。其中马尔可夫链和马尔可夫奖励过程在其他领域例如金融分析会用的比较多,强化学习则重在决策,这里讲马尔可夫链的例子也是为了帮助读者理解状态转移矩阵的概念。
\qquad 到这里我们就可以把马尔可夫决策过程描述成一个今天常用的写法,即用一个五元组 <S,A,R,P,\gamma> 来表示。其中 S 表示状态空间,即所有状态的集合,A 表示动作空间,R 表示奖励函数,P 表示状态转移矩阵,\gamma 表示折扣因子。想必读者此时已经明白这简简单单的五个字母符号,背后蕴涵了丰富的内容。
2.5 实战:搭建 Python 编程环境
\qquad 本书的代码实现主要基于 \text{Python} 语言,因此读者需要先搭建好相关编程环境。编程环境主要包括语言包和代码编辑器,其中语言包是指 \text{Python} 语言的安装包,代码编辑器是指用来编写代码的软件,比如 \text{PyCharm}、\text{Jupyter Notebook}、\text{Sublime Text} 等等。
\qquad 这里我们推荐使用 \text{Anaconda} 来安装 \text{Python} 语言包,\text{VS Code} 来编写代码。其中 \text{Anaconda} 不仅可以用来管理 \text{Python} 语言包,还可以用来管理 \text{Python} 的虚拟环境,这样可以避免不同项目之间的依赖冲突,同类的环境管理器还有 \text{pipenv} 等等,但都没有 \text{Anaconda} 功能更加强大。\text{VS Code} 是微软开发的一款轻量级代码编辑器,它不仅支持 \text{Python} 语言,还支持 \text{C++}、\text{Java}、\text{JavaScript} 等等,而且还可以安装各种插件,比如 \text{Jupyter Notebook} 插件,这样就可以在 \text{VS Code} 中直接运行 \text{Jupyter Notebook} 代码了,非常方便。
2.5.1 Anaconda 安装
2.5.1.1 Windows 系统
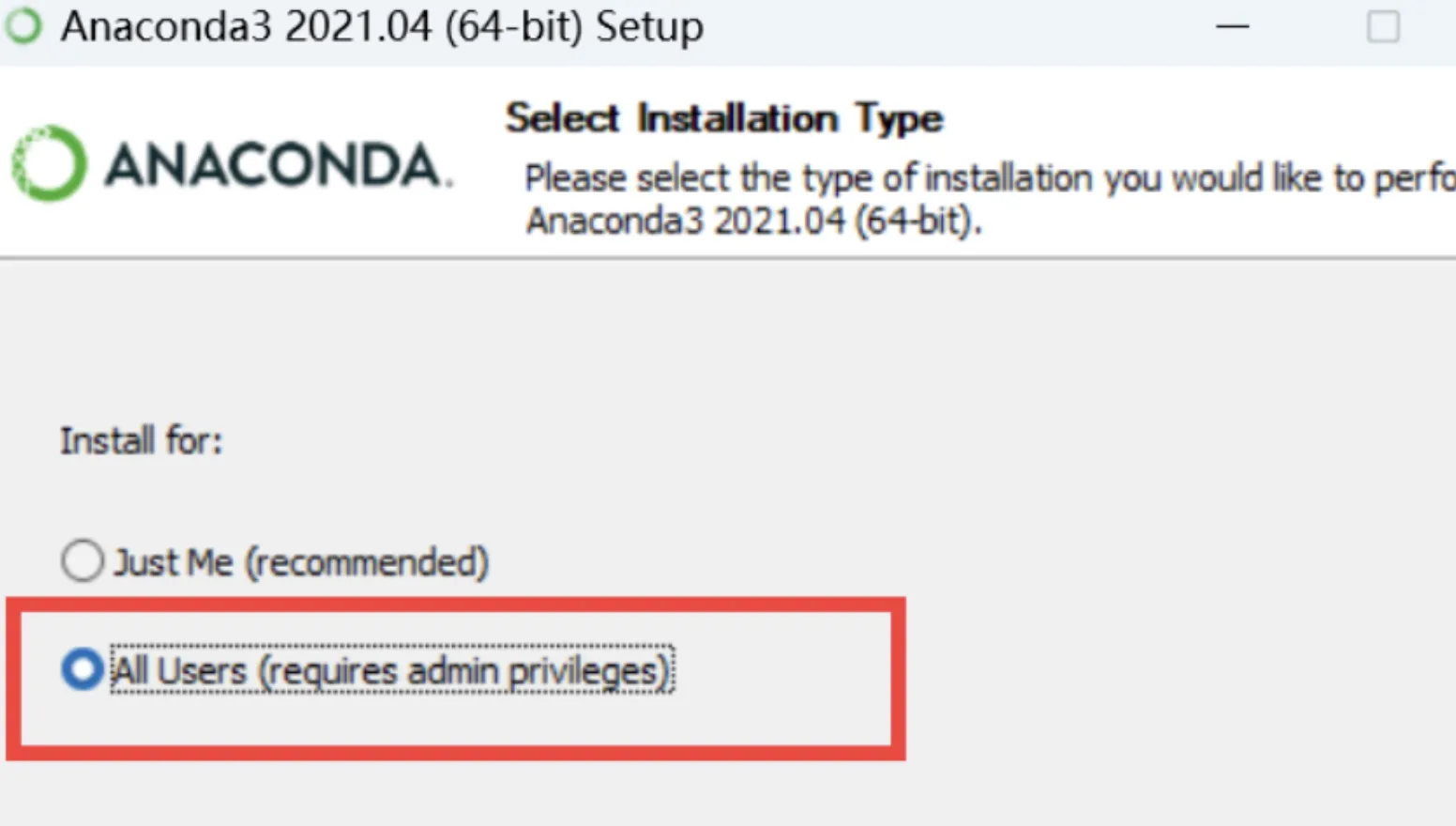
\qquad 打开Anaconda 官网下载对应的安装包,下载完成后双击安装包,按照提示一步步安装即可。注意安装时勾选为所有用户安装,如图 \text{2-3} 所示。
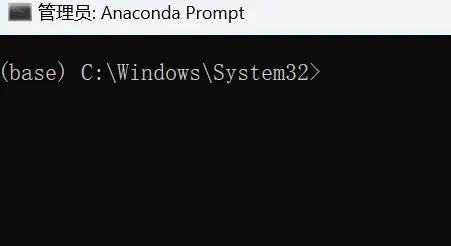
\qquad 由于 \text{Windows} 系统终端较多,在使用时需要在对应的终端初始化 \text{Anaconda} 环境(类似于配置环境变量),首先以管理员身份打开 \text{Anaconda Prompt},如图 \text{2-4} 所示。
然后执行以下命令分别初始化对应终端环境。
# 初始化 cmd 终端 conda init cmd.exe # 初始化 PowerShell 终端 conda init powershell
2.5.1.2 Mac 系统
\qquad \text{Mac} 系统安装较为简单,下载好对应的安装包之后,按照提示安装即可,注意勾选仅为当前用户安装,如图 \text{2-5} 所示。
2.5.1.3 Linux 系统
2.5.2 VS Code 安装
\qquad 不同系统下 \text{VS Code} 的安装是类似的,因此这里仅介绍 \text{Windows} 系统下的安装过程,其他系统读者可参考类推。
\qquad 首先打开VS Code 官网下载对应的安装包,注意 \text{Windows} 要选择 \text{System installer},如图 \text{2-6} 所示。
\qquad 安装时勾选添加到 \text{Windows} 资源管理器的右键菜单,如图 \text{2-7} 所示。

\qquad 安装完成后,打开 \text{VS Code},点击左侧的扩展按钮,即插件市场,搜索 \text{Python} 并安装,如图 \text{2-8} 所示。
2.5.3 基本使用方法
\qquad 上述过程安装配置完成后,就可以简单使用 \text{VS Code} 编写 \text{Python} 代码了,现在我们来简单介绍一下基本的使用方法。
\qquad 简单创建并打开一个 \text{Python} 文件,在 \text{VS Code} 下方就会显示当前 \text{Python} 解释器的版本,如图 \text{2-9} 所示。
然后单击就能选择其他版本的解释器,如图 \text{2-10} 所示。
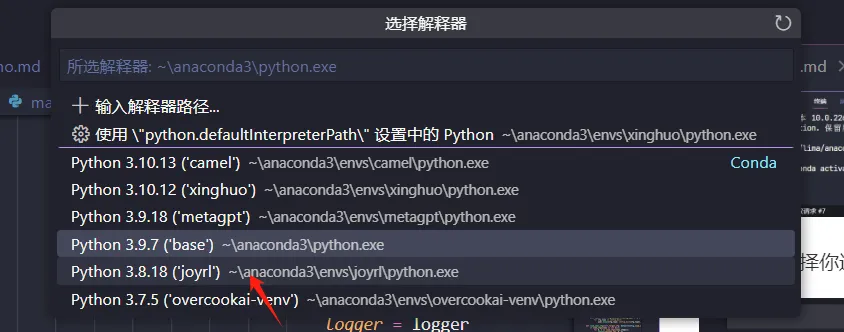
选择好解释器版本后,重新打开一个终端,就能看到当前的解释器版本了,如图 \text{2-11} 所示。

2.6 本章小结
\qquad 本章主要介绍了马尔可夫决策过程的概念,它是强化学习的基本问题模型之一,因此读者需要牢牢掌握。此外拓展了一些重要的概念,包括马尔可夫性质、回报、状态转移矩阵、轨迹、回合等,这些概念在我们后面讲解强化学习算法的时候会频繁用到,务必牢记。
2.7 练习题
-
强化学习所解决的问题一定要严格满足马尔可夫性质吗?请举例说明。
-
马尔可夫决策过程主要包含哪些要素?
-
马尔可夫决策过程与金融科学中的马尔可夫链有什么区别与联系?