5.1常见的模型保存格式
文档摘要
5.1 常见的模型保存格式 在深度学习框架中,模型训练过程、中间表示(Intermediate Representation, IR)和模型推理(Inference)之间有着密切的关系。以下的图示展示了这种关系: fig5-0 模型训练与推理的关系 在深度学习模型训练和部署的过程中,不同的框架和应用场景会使用各种模型保存格式。以下是一些常见的格式及其特点。 5.1.1 ckpt 文件格式通常用于保存模型的检查点(即 ),以便在训练过程中定期保存模型的状态,便于在意外中断后恢复训练或使用中间的模型状态进行后续操作。例如在论文 The Llama 3 Herd of Models](https://arxiv.org/pdf/2407.
5.1 常见的模型保存格式
在深度学习框架中,模型训练过程、中间表示(Intermediate Representation, IR)和模型推理(Inference)之间有着密切的关系。以下的图示展示了这种关系:

在深度学习模型训练和部署的过程中,不同的框架和应用场景会使用各种模型保存格式。以下是一些常见的格式及其特点。
5.1.1 ckpt
.ckpt 文件格式通常用于保存模型的检查点(即 checkpoint),以便在训练过程中定期保存模型的状态,便于在意外中断后恢复训练或使用中间的模型状态进行后续操作。例如在论文 [The Llama 3 Herd of Models](2407.21783 (arxiv.org)) 中便提到LLaMA3系列模型的训练使用了 NVIDIA H100 的GPU集群,而在GPU出现故障后,就会马上启动容灾策略,从上一个 checkpoint 中恢复,继续训练。
例如,使用 TensorFlow 训练的模型通常会保存为 .ckpt 格式。Pytorch 框架中也经常使用 .ckpt 作为模型文件格式。Pytorch 提供了更简单和更高层次的 API,用于训练和管理深度学习模型。.ckpt 文件保存了模型的参数和优化器的状态,并且通常还包含训练的元数据信息。
import tensorflow as tf # 创建一个简单的模型 model = tf.keras.Sequential([ tf.keras.layers.Dense(10, activation='relu', input_shape=(32,)), tf.keras.layers.Dense(1) ]) # 编译模型 model.compile(optimizer='adam', loss='mean_squared_error') # 训练模型并保存检查点 checkpoint_path = "training_checkpoints/cp.ckpt" checkpoint_dir = os.path.dirname(checkpoint_path) cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path, save_weights_only=True, verbose=1) model.fit(data, labels, epochs=10, callbacks=[cp_callback])
使用 Pytorch Lightning 提供的 ModelCheckpoint 回调函数来保存和加载 .ckpt 文件:
import pytorch_lightning as pl # 定义一个 PyTorch Lightning 训练模块 class MyLightningModel(pl.LightningModule): def __init__(self): super().__init__() self.linear_layer = nn.Linear(10, 1) self.loss_function = nn.MSELoss() def forward(self, inputs): return self.linear_layer(inputs) def training_step(self, batch, batch_idx): features, targets = batch predictions = self(features) loss = self.loss_function(predictions, targets) self.log('train_loss', loss) return loss # 初始化 PyTorch Lightning 模型 lightning_model = MyLightningModel() # 配置 ModelCheckpoint 回调以定期保存最佳模型至 .ckpt 文件 checkpoint_callback = pl.callbacks.ModelCheckpoint( monitor='val_loss', filename='best-model-{epoch:02d}-{val_loss:.2f}', save_top_k=3, mode='min' ) # 创建训练器并启动模型训练 trainer = pl.Trainer( callbacks=[checkpoint_callback], max_epochs=10 ) trainer.fit(lightning_model) # 从 .ckpt 文件加载最优模型权重 best_model = MyLightningModel.load_from_checkpoint(checkpoint_path='best-model.ckpt') # 使用加载的 .ckpt 文件中的模型进行预测 sample_input = torch.randn(1, 10) predicted_output = best_model(sample_input) print(predicted_output)
5.1.2 pt
.pt文件格式是 PyTorch 框架中常用的模型保存格式,可以保存模型的权重或者整个模型(包括结构和权重)。
import torch import torch.nn as nn # 创建一个简单的模型 class SimpleModel(nn.Module): def __init__(self): super(SimpleModel, self).__init__() self.fc1 = nn.Linear(32, 10) self.fc2 = nn.Linear(10, 1) def forward(self, x): x = torch.relu(self.fc1(x)) x = self.fc2(x) return x # 初始化模型 model = SimpleModel() # 保存模型 torch.save(model.state_dict(), 'model_weights.pt') # 或者保存整个模型 torch.save(model, 'model.pt')
5.1.3 pth
.pth文件格式也是 PyTorch 框架中常用的模型保存格式,与 .pt 格式类似,用于保存模型的权重或整个模型。
它是一个二进制文件,包含了模型的参数和状态。.pth 文件保存了模型的权重和各层的参数,可以方便地用于加载和恢复模型。通过保存模型为 .pth 文件,我们可以在需要时重新加载模型,并使用它进行预测或继续训练。
要将模型保存为 .pth 文件,我们可以使用 torch.save() 函数。下面是一个保存和加载 .pth 文件的示例:
import torch import torch.nn as nn # 定义一个简单的神经网络 class MyModel(nn.Module): def __init__(self): super(MyModel, self).__init__() self.fc = nn.Linear(10, 1) def forward(self, x): return self.fc(x) # 创建模型实例 model = MyModel() # 保存模型为.pth文件 torch.save(model.state_dict(), 'model.pth') # 加载.pth文件中的模型 loaded_model = MyModel() loaded_model.load_state_dict(torch.load('model.pth'))
在上面的示例中,我们首先定义了一个简单的神经网络模型,然后将其保存为 .pth 文件,文件名为 model.pth。接下来,我们创建了一个新的模型实例 loaded_model ,并使用 load_state_dict() 函数加载了 .pth 文件中的模型参数。
保存的 .pth 文件可以用于加载模型并进行推理。下面是一个使用 .pth 文件进行推理的示例:
input_tensor = torch.randn(1, 10) output = loaded_model(input_tensor) print(output)
在上面的示例中,我们首先创建了一个随机输入张量 input_tensor,然后使用加载的模型 loaded_model 对其进行预测,并打印出预测结果 output。
5.1.4 bin
.bin 文件格式是适用范围最广的,数据和模型权重以二进制的形式存储,在很多深度学习框架中被广泛使用,例如 Hugging Face 的 Transformers 库通常将模型保存为 .bin 格式,它可以用来存储任意类型的数据。下面是示例代码:
from transformers import BertModel # 初始化模型 model = BertModel.from_pretrained('bert-base-uncased') # 保存模型 model.save_pretrained('bert_model') # 加载模型 model = BertModel.from_pretrained('bert_model')
5.1.5 safetensors
safetensors 是一种由 Hugging Face 推出的一种新型安全模型存储格式,强调安全性和高效性,尤其在分布式训练和推理场景中被广泛使用。其特别关注模型安全性、隐私保护和快速加载。它仅包含模型的权重参数,而不包括执行代码,这样可以减少模型文件大小,提高加载速度。其以更加紧凑、跨框架的方式存储 Dict[str, Tensor] ,主要存储的内容为 tensor 的名字(字符串)及内容(权重)。
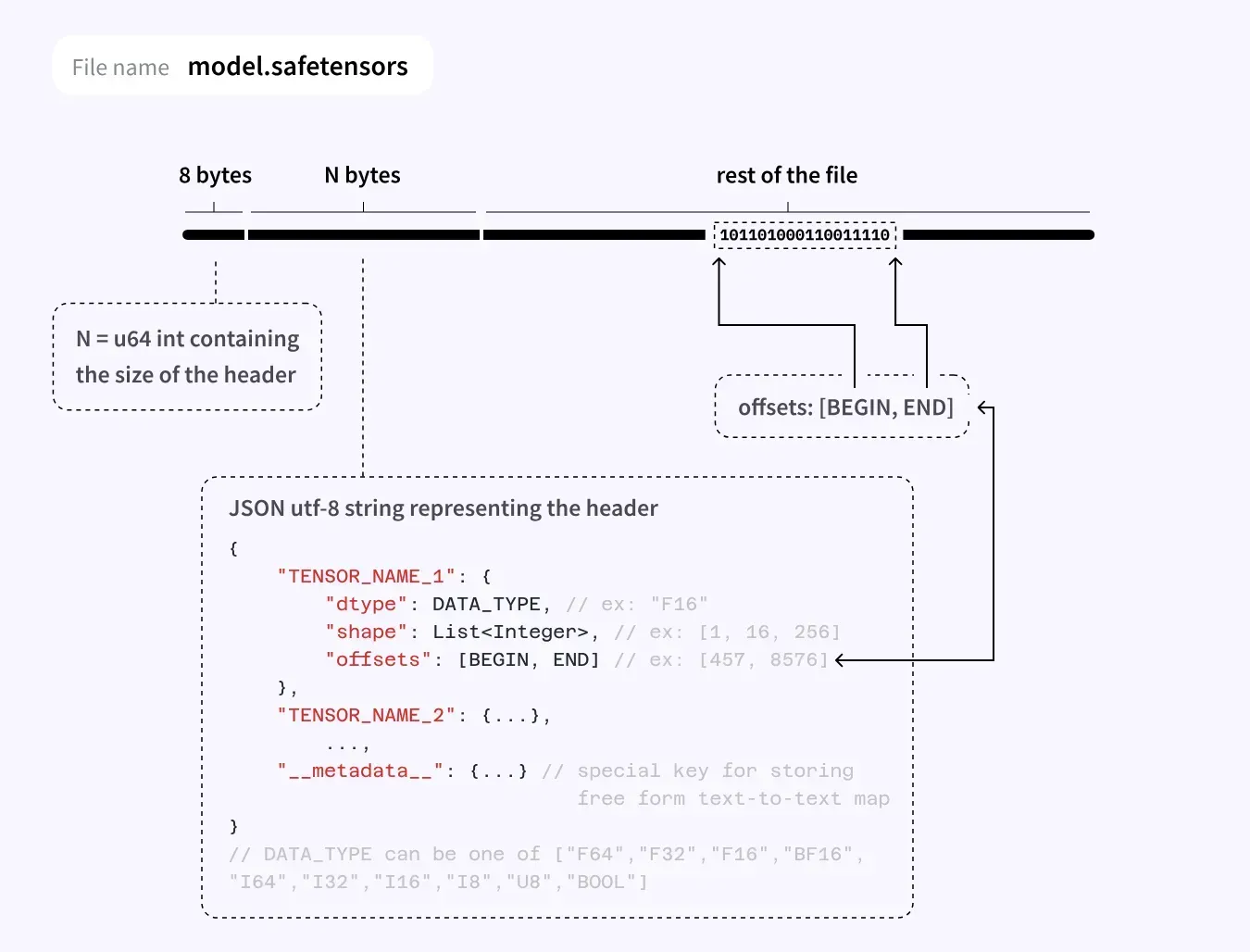
其官网对文件格式的详细内容进行了解释,本质上就是一个JSON文件加上若干binary形式的buffer。对于tensor而言,它只存储了数据类型、形状、对应的数据区域起点和终点。因此它只支持存储dense and contiguous tensor,也就是稠密张量(没有stride,没有view等信息)。本质上它就像存储了一大块连续的内存,甚至可以直接把文件映射到内存里(使用Python的mmap模块)。
如果熟悉 text-to-image 领域的读者可能会很熟悉,现在的 Stable Diffusion 的各种开源文生图模型绝大多数都是以 safetensors 格式保存的,如图所示。
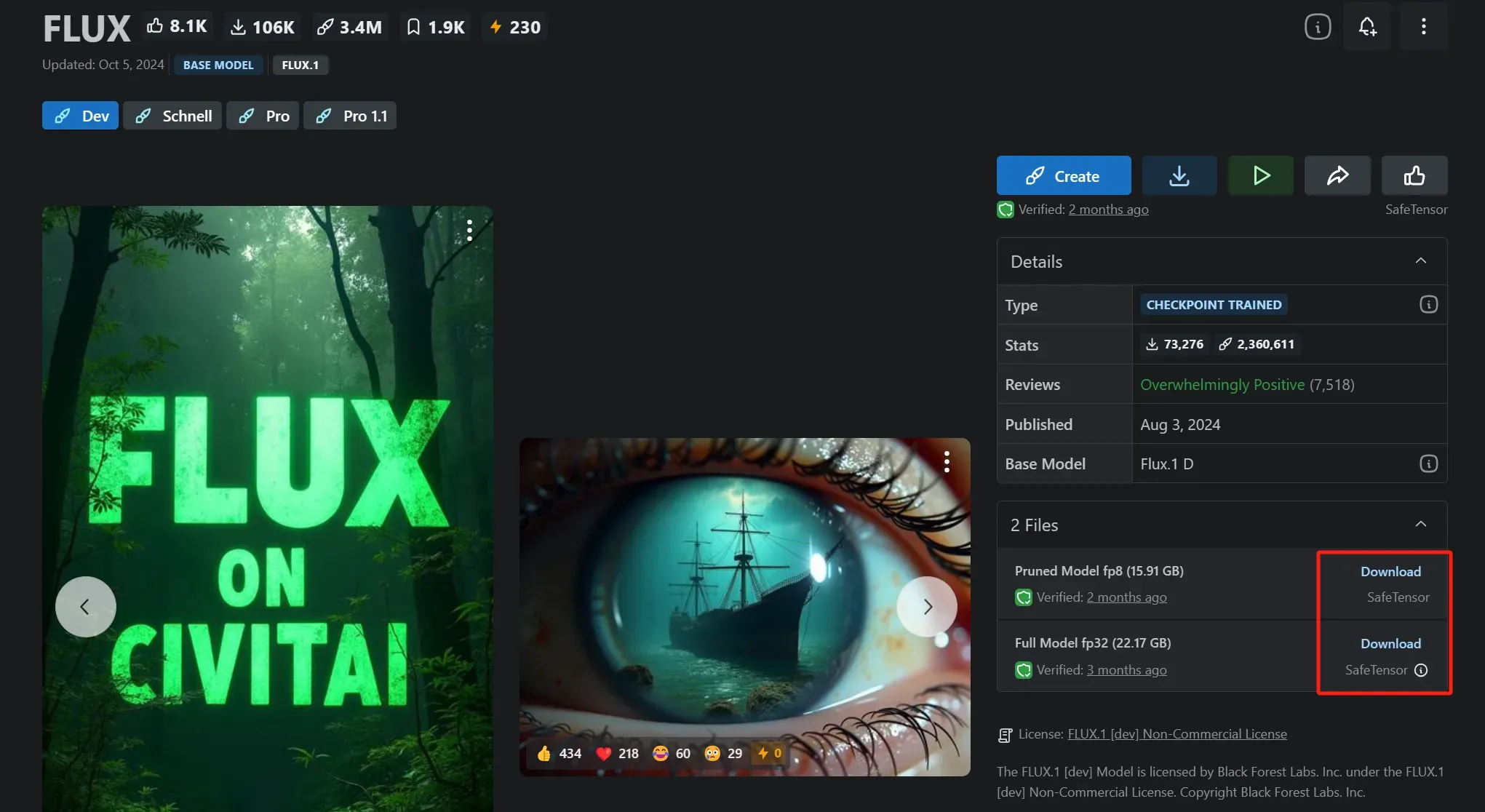
而更为早期的文生图模型可能还有一些保留了 .ckpt 格式,但由于可能会导致恶意代码的注入而没有safetensor 安全而逐渐被过渡。关于 Stable Diffusion 中 SafeTensors vs CheckPoint 的更详细的讨论可以进一步参考 SafeTensors vs Ckpt for Stable Diffusion。
# SDXL举例 import torch from diffusers import StableDiffusionXLPipeline, UNet2DConditionModel, EulerDiscreteScheduler from huggingface_hub import hf_hub_download from safetensors.torch import load_file base = "stabilityai/stable-diffusion-xl-base-1.0" repo = "ByteDance/SDXL-Lightning" ckpt = "/home/bino/svul/models/sdxl/sdxl_lightning_2step_unet.safetensors" # Use the correct ckpt for your step setting! # Load model. unet = UNet2DConditionModel.from_config(base, subfolder="unet").to("cuda", torch.float16) unet.load_state_dict(load_file(ckpt, device="cuda")) # unet.load_state_dict(load_file(hf_hub_download(repo, ckpt), device="cuda")) pipe = StableDiffusionXLPipeline.from_pretrained(base, unet=unet, torch_dtype=torch.float16, variant="fp16").to("cuda") # Ensure sampler uses "trailing" timesteps. pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing") # Ensure using the same inference steps as the loaded model and CFG set to 0. pipe("A girl smiling", num_inference_steps=4, guidance_scale=0).images[0].save(https://www.aiknowledge.cn/images/大模型/LLM推理和部署理论与实践/"output.webp)
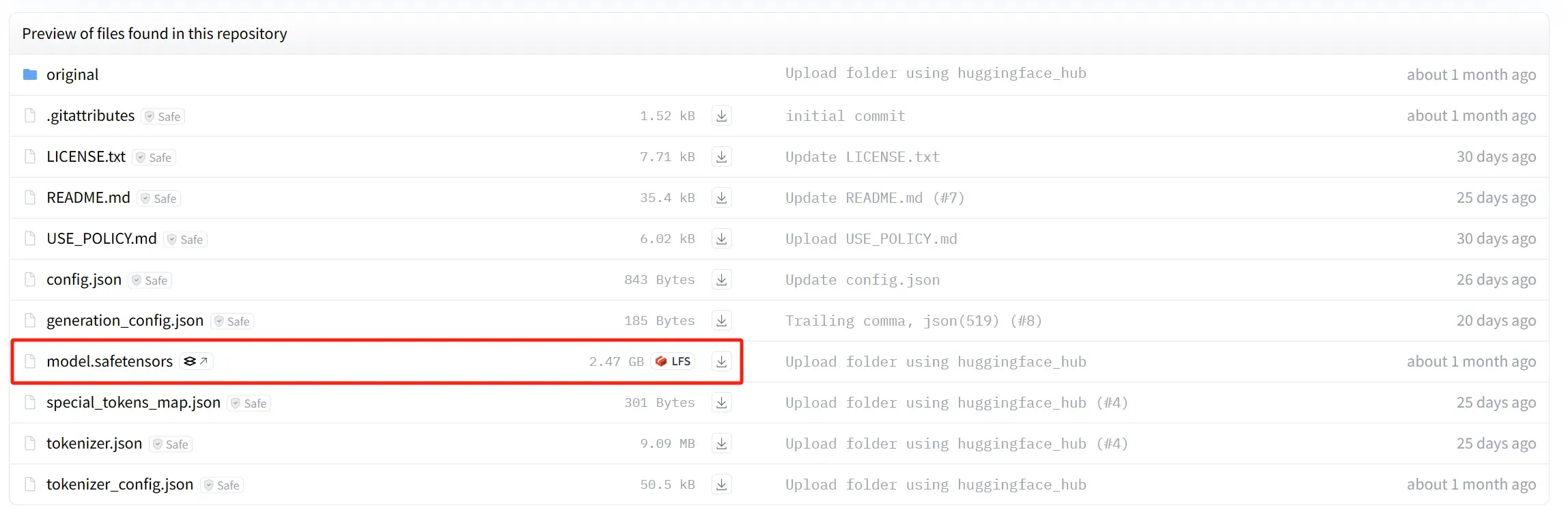
当然现在 Hugging Face 上的大多数主流大语言模型 Large Language Model 的权重文件也都是以 safetensors 保存的,对于 LLM 来说,使用 Transformers library 加载模型的代码会更简单。
# Load model directly from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-1B") model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.2-1B")

5.1.6 Netron 模型可视化工具介绍

Netron 是一个开源的神经网络模型可视化工具,支持多种模型格式的可视化,包括 ONNX、TensorFlow、Keras、Caffe、PyTorch 等。
使用 Netron 可视化模型:
- 从Netron 官网下载并安装 Netron;
- 打开 Netron,加载需要可视化的模型文件;
- 在 Netron 界面中浏览和分析模型的结构。
以yolov5m为例,其网络结构可视化如下图所示

通过 Netron,可以方便地查看模型的各层结构和参数,有助于理解模型的内部工作原理,并进行调试和优化。
在后续章节中,我们将深入探讨如何将不同格式的模型转换为通用的中间表示(IR),并在不同的推理引擎中部署这些模型。