43.时间复杂度
文档摘要
title: 43. 时间复杂度 tags: zk complexity theory time complexity big O notation WTF zk 教程第 43 讲:时间复杂度 在上一讲中,我们介绍了图灵机的概念及其在计算理论中的重要性。这一讲,我们将探讨计算理论中另一个核心概念:复杂性理论,并介绍时间复杂度。 什么是复杂性理论 复杂性理论是计算机科学的一个重要分支,主要研究解决计算问题所需的资源(如时间和空间)。它回答了以下关键问题: 解决一个特定问题需要多少时间? 需要多少内存空间? 不同问题之间的难度如何比较? 复杂性理论不仅关注解决问题是否可能(这是可计算性理论的范畴),更关注解决问题的效率。它帮助我们理解问题的内在难度,指导我们设计更高效的算法。
title: 43. 时间复杂度 tags: - zk - complexity theory - time complexity - big O notation
WTF zk 教程第 43 讲:时间复杂度
在上一讲中,我们介绍了图灵机的概念及其在计算理论中的重要性。这一讲,我们将探讨计算理论中另一个核心概念:复杂性理论,并介绍时间复杂度。
1. 什么是复杂性理论
复杂性理论是计算机科学的一个重要分支,主要研究解决计算问题所需的资源(如时间和空间)。它回答了以下关键问题:
- 解决一个特定问题需要多少时间?
- 需要多少内存空间?
- 不同问题之间的难度如何比较?
复杂性理论不仅关注解决问题是否可能(这是可计算性理论的范畴),更关注解决问题的效率。它帮助我们理解问题的内在难度,指导我们设计更高效的算法。
2. 时间复杂度
时间复杂度(Time Complexity)是衡量算法执行效率的一个重要指标,它描述了算法运行时间与输入规模之间的关系。具体来说,时间复杂度表示当输入规模增加时,算法执行所需时间的增长率。
在理论计算机科学中,我们通常使用图灵机模型来定义时间复杂度。假设 M 是一个对于所有输入都能停机的图灵机,它的时间复杂度函数 t(n) 定义为:对于所有长度为 n 的输入,M 执行的最大步数。
这个定义可以帮助我们分析算法在最坏情况下的性能。实际应用中,我们通常使用大 O 符号来表示时间复杂度的上界,这提供了一种描述算法效率增长趋势的标准方法。
2.1 大 O 表示法
算法的精确运行时间通常可以表示为一个多项式表达式,例如 T(n) = an^3 + bn^2 + cn + d,其中 n 是输入规模,a、b、c 和 d 是常数系数。然而,为了简化分析并关注算法的整体性能趋势,我们通常只估计它的增长率和数量级。这种方法被称为渐进分析,它主要考虑算法运行时间表达式中的最高次项,因为在输入规模较大时,最高次项的影响会远远超过其他项。
大 O 表示法给出了算法运行时间的上界。如果一个算法的时间复杂度是 O(t(n)),意味着存在常数 c 和 n_0,使得对于所有 n \ge n_0,算法在输入大小为 n 时的运行时间不超过 ct(n)。这种表示方法允许我们忽略常数因子和低阶项,专注于算法运行时间随输入规模增长的总体趋势。
例如,如果一个算法的精确运行时间是 T(n) = 3n^2 + 2n + 1,我们会说它的时间复杂度是 O(n^2),因为在输入规模足够大时,n^2 项主导了整个表达式的增长。
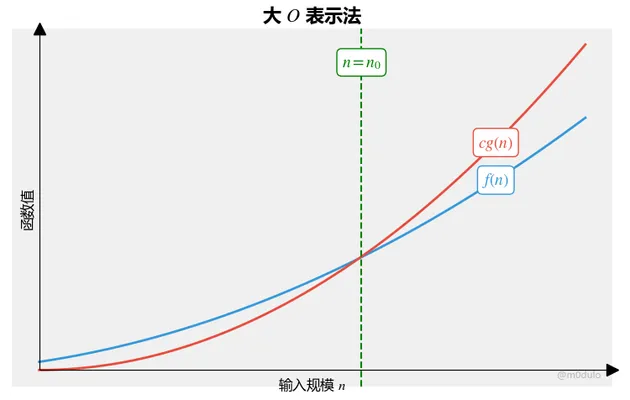
形式化定义:
- 设 f 和 g 是两个函数 f 和 g : \mathcal{N} \rightarrow {\mathcal{R}}^{ + } . 称 f(n) = O(g(n));
- 若存在正整数 c 和 n_0, 使得对所有 n \ge n_0 有 f(n) \le cg(n);
- 当 f\left( n\right) = O\left( {g\left( n\right) }\right) 时,称 g\left( n\right) 是 f\left( n\right) 的渐进上界。
考察下边这个例子:
设 f_1(n) 是函数 5n^3 + 2n^2 + 22n + 6. 保留最高次项 5n^3 , 并且舍去它的系数 5, 得到 f_1(n) = O(n^3) .
验证一下这个结果是否满足上面的形式定义。为此令 c 等于 6, n_0 等于 10, 则对于所有 n \ge 10, 有 5n^3 + 2n^2 + 22n + 6 \le 6n^3 .
此外,有 f_1(n) = O(n^4). 因为 n^4 比 n^3 大,所以它也是 f_1 的一个渐近上界。
但是 f_1(n) 不等于 O(n^2) . 不论给 c 和 n_0 赋什么值,始终不能满足定义的要求。
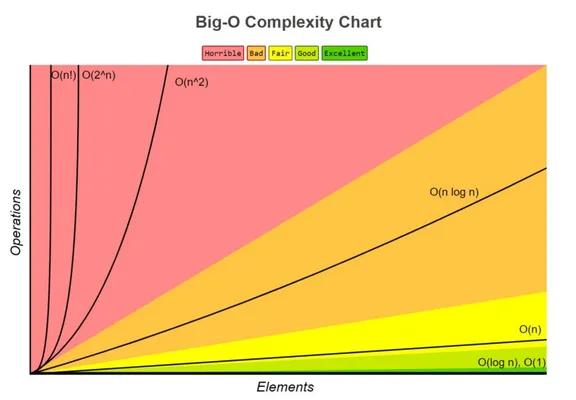
2.2 常见的时间复杂度
假设输入长度为 n。
-
O(1) - 常数时间:无论输入大小如何,算法总是执行固定次数的操作,非常高效。比如访问数组的特定元素:
def constant_time(arr): return arr[0] if arr else None -
O(\log{n}) - 对数时间:算法的运行时间与输入大小的对数成正比,非常高效。比如二分查找:
def binbary_search(arr, target): left, right = 0, len(arr) - 1 while left <= right: mid = (left + right) // 2 if arr[mid] == target: return mid elif arr[mid] < target: left = mid + 1 else: right = mid - 1 return -1 -
O(n) - 线性时间:算法的运行时间与输入大小成正比,比较高效。比如遍历数组:
def linear_search(arr, target): for i, value in enumerate(arr): if value == target: return i return -1 -
O(n \log{n}) - 线性对数时间:算法的运行时间与 n\log{n} 成正比。很多高效的排序算法都具有这种复杂度,效率可以接受,比如归并排序(Merge Sort):
def merge_sort(arr): if len(arr) <= 1: return arr mid = len(arr) // 2 left = merge_sort(arr[:mid]) right = merge_sort(arr[mid:]) return merge(left, right) def merge(left, right): result = [] i, j = 0, 0 while i < len(left) and j < len(right): if left[i] <= right[j]: result.append(left[i]) i += 1 else: result.append(right[j]) j += 1 result.extend(left[i:]) result.extend(right[j:]) return result
-
O(n^2) - 平方时间:算法的运行时间与 n^2 成正比,通常涉及嵌套循环,效率低下。比如冒泡排序:
def bubble_sort(arr): n = len(arr) for i in range(n): for j in range(0, n - i - 1): if arr[j] > arr[j + 1]: arr[j], arr[j + 1] = arr[j + 1], arr[j] return arr -
O(2^n) - 指数时间:算法的运行时间随输入大小呈指数增长,效率低下。比如递归计算斐波那契数列:
def fibonacci(n): if n <= 1: return n return fibonacci(n-1) + fibonacci(n-2)
我们经常导出形如 n^c 的界, c 是大于 0 的常数。这种界称为多项式界;形如 2^{(n^k)} 的界,当 k 是大于 0 的实数时,称为指数界。
3. 最坏情况、平均情况和最好情况分析
在分析算法时,我们通常考虑三种情况:
-
最坏情况:算法执行时间最长的情况。这通常是我们最关心的,因为它给出了算法性能的上界。
-
平均情况:算法在所有可能输入下的平均表现。这通常更接近算法在实践中的表现。
-
最好情况:算法执行时间最短的情况。尽管这不太常用,但有时也能提供有用的信息。
考虑线性搜索算法:
- 最坏情况:目标元素在数组的最后或不存在,需要遍历整个数组,时间复杂度为 O(n)。
- 平均情况:假设目标元素随机分布,平均需要遍历半个数组,时间复杂度仍为 O(n)。
- 最好情况:目标元素在数组的第一个位置,时间复杂度为 O(1)。
4. 模型间的复杂性关系
问题的复杂度与选择的计算模型有关。
考虑单带图灵机、多带图灵机和非确定型图灵机,这几种计算模型的选择怎样影响时间复杂度。
-
设 t\left( n\right) 是一个函数, t\left( n\right) \geq n 。则每一个 t\left( n\right) 时间的多带图灵机都和某一个 O\left( {{t}^{2}\left( n\right) }\right) 时间的单带图灵机等价。
-
设 t\left( n\right) 是一个函数, t\left( n\right) \geq n 。则每一个 t\left( n\right) 时间的非确定型单带图灵机都与某一个 {2}^{O\left( {t\left( n\right) }\right) } 时间的确定型单带图灵机等价。
单带图灵机和多带图灵机的时间复杂性最多是平方级别的差异。
确定型图灵机和非确定型图灵机的时间复杂性最多是指数级别的差异。
所有合理的确定型计算模型都是多项式等价的。也就是说,它们中任何一个模型都可以模拟另一个,而运行时间只增长多项式倍。
5. 与 ZK 的联系:为什么复杂性分析对 ZK 重要
复杂性分析在 ZK 证明系统的设计和实现中起着关键作用:
-
效率评估:复杂性分析帮助我们评估 ZK 协议的计算和通信成本。例如,我们希望证明生成的时间复杂度尽可能低,而验证的时间复杂度理想情况下应该是常数级的。
-
安全性分析:复杂性理论帮助我们理解破解 ZK 系统的难度。许多 ZK 协议的安全性基于某些计算问题的难解性,这些问题通常具有高时间复杂度。
-
可行性判断:复杂性分析允许我们确定哪些计算问题适合转化为 ZK 证明。通常,我们寻找 NP 类中的问题,因为它们既难以解决又易于验证。
-
协议设计:理解复杂性有助于设计更高效的 ZK 协议。例如,我们可能会使用复杂度较低的算法来构造证明,或者优化协议以减少通信轮数。
-
性能优化:通过分析 ZK 系统各个组件的复杂度,我们可以识别瓶颈并进行有针对性的优化。
比如 zk-SNARKs(零知识简洁非交互式知识论证)的一个关键特性是验证的时间复杂度为 O(1),即常数时间。这意味着无论原始计算多么复杂,验证 ZK 证明的时间都是恒定的。这种特性使得 zk-SNARKs 特别适用于区块链这种高效验证的场景。
6. 总结
本讲介绍了时间复杂度这一复杂性理论核心概念。我们学习了大 O 符号、不同情况分析和计算模型间的复杂性关系。还探讨了复杂性分析在 ZK 证明系统中的重要应用,包括效率评估、安全性分析和协议设计等。这些知识为深入理解和应用 ZK 技术奠定了理论基础。