训练水果质量检测器
文档摘要
训练水果质量检测器 本课概述的草图笔记 草图笔记由 Nitya Narasimhan 创作。点击图片查看大图。 本视频将介绍 Azure 自定义视觉服务,这将在本课中被覆盖。 自定义视觉——使机器学习变得简单 | Xamarin Show 点击上面的图像观看视频 预习测验 预习测验 引言 最近人工智能(AI)和机器学习(ML)的兴起为当今开发者提供了广泛的能力。ML 模型可以训练以识别图像中的不同事物,包括未成熟的水果,这些可以用于物联网设备中,在收获时或工厂或仓库处理过程中帮助分类农产品。 在本课中,你将学习图像分类——使用 ML 模型区分不同事物的图像。你将学习如何训练一个图像分类器来区分好水果和坏水果,无论是过熟、未成熟、有瘀伤还是腐烂的水果。
训练水果质量检测器

草图笔记由 Nitya Narasimhan 创作。点击图片查看大图。
本视频将介绍 Azure 自定义视觉服务,这将在本课中被覆盖。
点击上面的图像观看视频
预习测验
引言
最近人工智能(AI)和机器学习(ML)的兴起为当今开发者提供了广泛的能力。ML 模型可以训练以识别图像中的不同事物,包括未成熟的水果,这些可以用于物联网设备中,在收获时或工厂或仓库处理过程中帮助分类农产品。
在本课中,你将学习图像分类——使用 ML 模型区分不同事物的图像。你将学习如何训练一个图像分类器来区分好水果和坏水果,无论是过熟、未成熟、有瘀伤还是腐烂的水果。
本课我们将涵盖以下内容:
- 使用 AI 和 ML 分类食品
- 通过机器学习进行图像分类
- 训练图像分类器
- 测试你的图像分类器
- 重新训练你的图像分类器
使用 AI 和 ML 分类食品
养活全球人口是一项艰巨的任务,尤其是在价格能让所有人都负担得起的情况下。最大的成本之一是劳动力,因此农民越来越多地转向自动化工具,如物联网(IoT),以减少劳动力成本。手工采摘劳动强度大(而且往往是辛苦的工作),正在被机械取代,尤其是在富裕国家。尽管使用机械收割节省了成本,但有一个缺点——无法在收割时对食品进行分类。
并非所有作物都能均匀成熟。例如,西红柿在大部分成熟时仍可能有一些绿色果实留在藤上。虽然过早收获这些是浪费,但对农民来说,使用机械收割所有作物并稍后处理未成熟的果实更便宜、更容易。
✅ 查看附近的农场或花园里生长的不同水果或蔬菜,或者商店里的水果,它们是否都处于相同的成熟度,还是你看到差异?
自动化的收割改变了食品分类从田间到工厂的过程。食物会在长传送带上移动,由一组人挑选并移除不符合质量标准的东西。虽然机械收割降低了成本,但仍然需要人工进行食品分类。
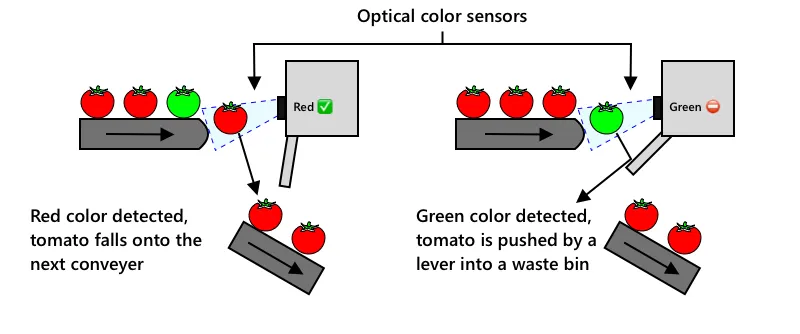
下一个进化阶段是使用机器进行分类,这些机器要么集成在收割机中,要么在加工厂中。第一代这种机器使用光学传感器检测颜色,通过杠杆或空气脉冲控制执行器,将绿色西红柿推入废料箱,留下红色西红柿继续在一系列传送带上前进。
在这段视频中,当西红柿从一个传送带落到另一个传送带上时,绿色西红柿被检测到并用杠杆弹入废料箱。
✅ 在工厂或田间,你需要什么条件才能让这些光学传感器正常工作?
最新的分类机利用了 AI 和 ML,使用经过训练的模型来区分好的食品和坏的食品,不仅仅是通过明显的颜色差异,如绿色西红柿与红色,而是通过更细微的外观差异,这些差异可以指示疾病或瘀伤。
通过机器学习进行图像分类
传统编程是你取数据,应用算法,然后得到输出。例如,在上一个项目中,你取 GPS 坐标和地理围栏,应用由 Azure Maps 提供的算法,并得到该点是否在地理围栏内的结果。输入更多数据,得到更多输出。
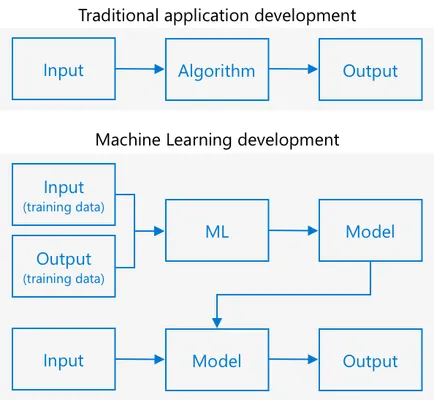
机器学习则相反——你从数据和已知输出开始,机器学习算法从数据中学习。然后你可以将训练过的算法,称为“机器学习模型”或“模型”,输入新的数据并获得新的输出。
机器学习算法从数据中学习的过程称为“训练”。输入和已知输出称为“训练数据”。
例如,你可以给模型数百万张未成熟香蕉的图片作为输入训练数据,训练输出设置为 unripe,以及数百万张成熟香蕉的图片作为训练数据,训练输出设置为 ripe。ML 算法将根据这些数据创建一个模型。然后你可以给这个模型一张新的香蕉图片,它会预测这张新图片是成熟还是未成熟的香蕉。
ML 模型的结果称为“预测”

ML 模型不会给出二进制答案,而是给出概率。例如,模型可能会给一张香蕉图片预测 ripe 的概率为 99.7%,预测 unripe 的概率为 0.3%。你的代码会根据最佳预测选择,判断香蕉是成熟的。
用于检测此类图像的 ML 模型称为“图像分类器”——它接收带有标签的图像,然后根据这些标签对新图像进行分类。
这是一个简化的解释,还有许多其他不需要标签输出的训练方法,如无监督学习。如果你想了解更多关于 ML 的知识,请参阅ML 初学者课程,一个关于机器学习的 24 课时课程。
训练图像分类器
成功训练图像分类器需要数百万张图像。事实证明,一旦你训练了一个包含数百万甚至数十亿张各种图像的图像分类器,你可以用少量图像重新训练它并获得很好的结果,这一过程称为“迁移学习”。
迁移学习是指将现有 ML 模型的学习转移到基于新数据的新模型。
一旦图像分类器被广泛训练,它的内部结构擅长识别形状、颜色和模式。迁移学习允许模型利用已经学会识别图像部分的能力,将其用于识别新图像。
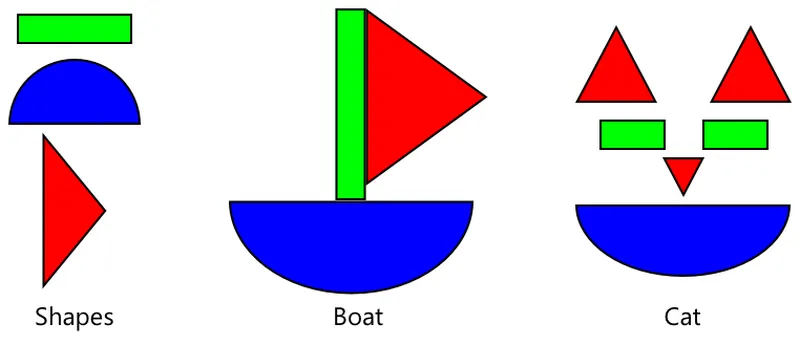
你可以想象这就像儿童形状书,一旦你能够识别半圆、矩形和三角形,你可以根据这些形状的配置识别出一艘船或一只猫。图像分类器可以识别形状,而迁移学习教会它什么组合构成了船或猫——或者是一只成熟的香蕉。
有许多工具可以帮助你做到这一点,包括可以在云中帮助你训练模型并通过 Web API 使用它的工具。
训练这些模型需要大量的计算能力,通常使用图形处理单元(GPU)。与使你在 Xbox 上的游戏看起来很棒的专用硬件相同,也可以用来训练机器学习模型。通过使用云,你可以租用配备 GPU 的强大计算机的时间,只需在你需要的时候获取所需的计算能力。
自定义视觉
自定义视觉是一种基于云的工具,用于训练图像分类器。它允许你仅使用少量图像来训练分类器。你可以通过网络门户、Web API 或 SDK 上传图像,并为每张图像添加一个表示其分类的“标签”。然后训练模型并测试其性能。一旦你对模型满意,可以通过 Web API 或 SDK 发布版本。
![]()
你可以使用每种分类少于 5 张图像来训练自定义视觉模型,但越多越好。至少使用 30 张图像可以获得更好的结果。
自定义视觉是微软提供的认知服务的一部分。这些服务是可以直接使用或通过少量训练使用的 AI 工具。它们包括语音识别和翻译、语言理解和图像分析。这些服务在 Azure 中提供免费层级。
免费层级足以创建一个模型,训练它,然后用于开发工作。你可以在 Microsoft 文档的自定义视觉限制和配额页面上阅读有关免费层级的限制信息。
任务 - 创建认知服务资源
要使用自定义视觉,首先你需要使用 Azure CLI 在 Azure 中创建两个认知服务资源,一个用于自定义视觉训练,一个用于自定义视觉预测。
-
为该项目创建一个资源组,命名为
fruit-quality-detector -
使用以下命令创建一个免费的自定义视觉训练资源:
az cognitiveservices account create --name fruit-quality-detector-training \ --resource-group fruit-quality-detector \ --kind CustomVision.Training \ --sku F0 \ --yes \ --location <location>将
<location>with the location you used when creating the Resource Group.This will create a Custom Vision training resource in your Resource Group. It will be called
fruit-quality-detector-trainingand use theF0sku, which is the free tier. The--yesoption means you agree to the terms and conditions of the cognitive services.
Use
S0替换为你已经拥有任何认知服务的免费账户的 SKU。
-
使用以下命令创建一个免费的自定义视觉预测资源:
az cognitiveservices account create --name fruit-quality-detector-prediction \ --resource-group fruit-quality-detector \ --kind CustomVision.Prediction \ --sku F0 \ --yes \ --location <location>将
<location>with the location you used when creating the Resource Group.This will create a Custom Vision prediction resource in your Resource Group. It will be called
fruit-quality-detector-predictionand use theF0sku, which is the free tier. The--yes替换为你的位置。--yes选项意味着你同意认知服务的条款和条件。
任务 - 创建图像分类器项目
-
打开自定义视觉门户 CustomVision.ai,并使用你在 Azure 账户中使用的 Microsoft 账户登录。
-
按照 创建新项目的构建分类器快速入门部分中的说明创建一个新的自定义视觉项目。UI 可能会更改,这些文档始终是最新的参考。
将你的项目命名为
fruit-quality-detector。在创建项目时,请确保使用之前创建的
fruit-quality-detector-training资源。使用“分类”项目类型,“多类别”分类类型和“食品”领域。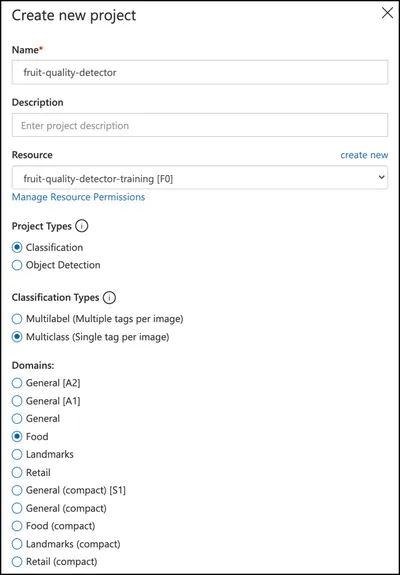
✅ 花些时间探索自定义视觉 UI 以了解你的图像分类器。
任务 - 训练你的图像分类器项目
为了训练一个图像分类器,你需要多个水果的图片,包括好质量和坏质量的图片,标记为好和坏,比如一根成熟的和一根过熟的香蕉。
这些分类器可以对任何图像进行分类,所以如果你手头没有不同质量的水果,可以用两种不同类型的水果,或者用猫和狗!
理想情况下,每张图片应该是单一的水果,具有一致的背景或广泛的背景。确保背景中没有任何特定于成熟或未成熟水果的物品。
重要的是不要有特定的背景或与分类无关的特定物品,否则分类器可能会仅仅基于背景进行分类。有一个皮肤癌分类器在训练时使用了正常的和癌变的痣,但癌变的痣旁边都有尺子来测量大小。结果是分类器几乎 100% 准确地识别了图片中的尺子,而不是癌变的痣。
图像分类器在非常低的分辨率下运行。例如,自定义视觉可以接受高达 10240x10240 的训练和预测图像,但在训练和运行模型时将图像缩小到 227x227。较大的图像会被缩小到这个尺寸,因此确保你要分类的东西在图像中占据很大一部分,否则在分类器使用的较小图像中可能太小。
-
收集分类器所需的图片。你至少需要每种标签 5 张图片来训练分类器,但越多越好。你还需要一些额外的图片来测试分类器。这些图片应该是同一事物的不同图片。例如:
-
使用两根成熟的香蕉,从几个不同角度拍摄每根香蕉的照片,至少拍摄 7 张照片(5 张用于训练,2 张用于测试),但最好更多。

-
对两根未成熟的香蕉重复同样的过程。
你应该至少有 10 张训练图片,至少 5 张成熟的和 5 张未成熟的,以及 4 张测试图片,2 张成熟的和 2 张未成熟的。图片应该是 PNG 或 JPEG 格式,小于 6MB。如果你使用 iPhone 创建它们,它们可能是高分辨率的 HEIC 图片,因此需要转换并可能缩小。图片越多越好,而且你应该有类似数量的成熟和未成熟的图片。
如果你没有成熟和未成熟的水果,可以用不同的水果,或者任何你手头可用的两个物体。你还可以在 images 文件夹中找到一些示例图像,这些图像展示了成熟和未成熟的香蕉,你可以使用这些图像。
-
-
按照 上传和标记图像部分中的说明上传训练图像。将成熟的水果标记为
ripe,将未成熟的水果标记为unripe。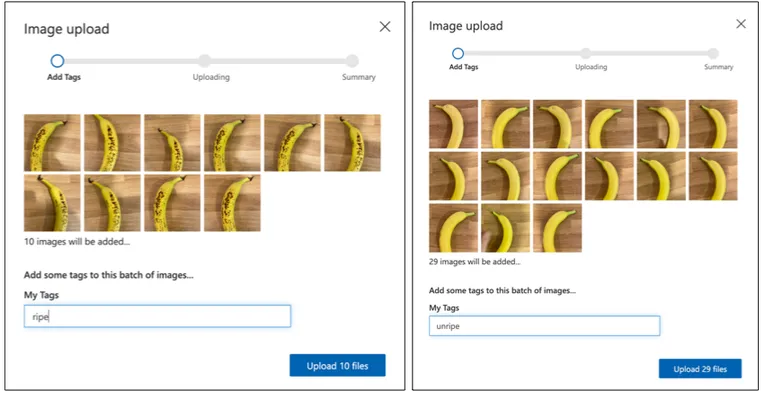
-
按照 训练分类器部分中的说明使用上传的图像训练图像分类器。
你将被要求选择训练类型。选择 快速训练。
分类器将开始训练。训练完成大约需要几分钟。
如果你在分类器训练期间决定吃掉你的水果,请确保你有足够的测试图片!
测试你的图像分类器
一旦你的分类器训练完成,你可以通过给它一张新图片来测试它。
任务 - 测试你的图像分类器
-
按照 测试你的模型文档中的说明测试你的图像分类器。使用你之前创建的测试图片,而不是你用于训练的任何图片。
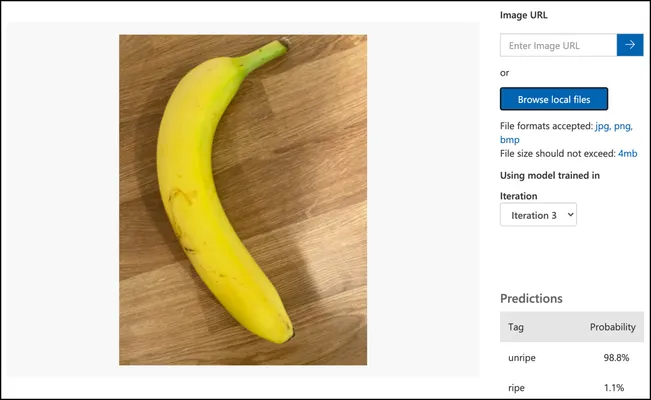
-
尝试所有你能访问的测试图片,并观察概率。
重新训练你的图像分类器
当你测试你的分类器时,它可能不会给你预期的结果。图像分类器使用机器学习根据图像特征的概率来预测图像中有什么。它并不理解图像内容——它不知道什么是香蕉,也不理解什么使香蕉成为香蕉而不是船。你可以通过使用错误的图片重新训练它来改进你的分类器。
每次使用快速测试选项进行预测时,图像和结果都会被存储。你可以使用这些图像来重新训练你的模型。
任务 - 重新训练你的图像分类器
-
按照 使用预测图像进行训练文档中的说明使用正确的标签重新训练你的模型。
-
一旦你的模型重新训练完成,测试新图片。
挑战
你认为如果你使用草莓的图片去训练一个用香蕉图片训练的模型,或者一个充气香蕉的图片,或者一个人穿香蕉服的图片,甚至是像辛普森家庭中黄色卡通人物一样的东西,会发生什么?
试着做一下看看预测结果是什么。你可以使用 Bing 图像搜索来查找可以尝试的图片。
课后测验
复习与自学
- 当你训练分类器时,你会看到 精确度、召回率 和 AP 的值来评估创建的模型。阅读 评估分类器部分 了解这些值是什么意思。
- 了解如何在 Microsoft 文档中提升你的自定义视觉模型 的相关内容。
任务
声明:
本文件灏天文库团队进行了翻译。尽管我们力求准确,但请注意,翻译可能包含错误或不准确之处。原文档以其原始语言为准。我们不对因使用此翻译而产生的任何误解或误译负责。