常见的自然语言处理任务和技术
文档摘要
常见的自然语言处理任务和技术 对于大多数自然语言处理任务,需要将要处理的文本分解、检查,并将结果存储或与规则和数据集交叉引用。这些任务使程序员能够推导出文本的意义、意图 或只是术语和单词出现的频率。 课前测验 让我们发现用于处理文本的一些常见技术。结合机器学习,这些技术可以帮助您高效地分析大量文本。然而,在应用机器学习之前,让我们了解自然语言处理专家遇到的问题。 自然语言处理中的常见任务 在分析一段文本时有不同的方法。您可以执行一些任务,并通过这些任务来理解文本并得出结论。通常按顺序执行这些任务。 分词 大多数自然语言处理算法首先要做的可能是将文本分割成标记(或单词)。虽然这听起来很简单,但考虑到标点符号和不同语言的单词和句子分隔符可能会使其变得复杂。您可能需要使用各种方法来确定分隔符。
常见的自然语言处理任务和技术
对于大多数自然语言处理任务,需要将要处理的文本分解、检查,并将结果存储或与规则和数据集交叉引用。这些任务使程序员能够推导出文本的_意义_、*意图* 或只是_术语和单词出现的频率_。
课前测验
让我们发现用于处理文本的一些常见技术。结合机器学习,这些技术可以帮助您高效地分析大量文本。然而,在应用机器学习之前,让我们了解自然语言处理专家遇到的问题。
自然语言处理中的常见任务
在分析一段文本时有不同的方法。您可以执行一些任务,并通过这些任务来理解文本并得出结论。通常按顺序执行这些任务。
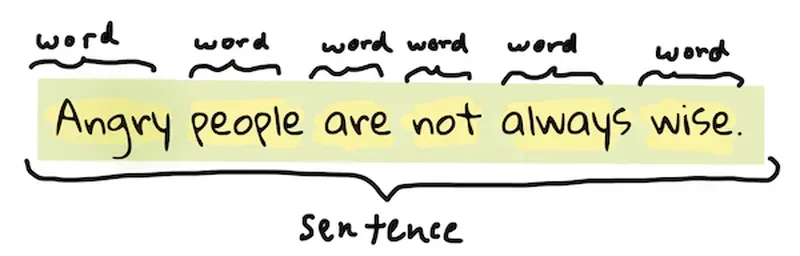
分词
大多数自然语言处理算法首先要做的可能是将文本分割成标记(或单词)。虽然这听起来很简单,但考虑到标点符号和不同语言的单词和句子分隔符可能会使其变得复杂。您可能需要使用各种方法来确定分隔符。
从《傲慢与偏见》中分词一个句子。信息图由Jen Looper制作
嵌入
词嵌入是一种将文本数据转换为数值的方法。嵌入的方式是让具有相似含义或经常一起使用的单词聚集在一起。

“我对你的神经非常尊敬,它们是我的老朋友。”- 《傲慢与偏见》中的一句话的词嵌入。信息图由Jen Looper制作
✅ 尝试这个有趣的工具(https://projector.tensorflow.org/) 来实验词嵌入。点击一个词会显示相似词的聚类:“玩具”与“迪士尼”、“乐高”、“PlayStation”和“控制台”聚类。
解析与词性标注
每个已分词的词都可以被标记为词性——名词、动词或形容词。句子 the quick red fox jumped over the lazy brown dog 可能会被词性标注为 fox = 名词,jumped = 动词。

从《傲慢与偏见》中解析一个句子。信息图由Jen Looper制作
解析是指识别句子中哪些词相互关联——例如 the quick red fox jumped 是一个形容词-名词-动词序列,而 lazy brown dog 则是一个独立的序列。
单词和短语频率
在分析大量文本时,构建一个包含所有感兴趣单词或短语及其出现频率的字典是一项有用的程序。短语 the quick red fox jumped over the lazy brown dog 的词频为2。
让我们看一个例子,统计单词的频率。鲁德亚德·吉卜林的诗《胜利者》包含以下一节:
What the moral? Who rides may read. When the night is thick and the tracks are blind A friend at a pinch is a friend, indeed, But a fool to wait for the laggard behind. Down to Gehenna or up to the Throne, He travels the fastest who travels alone.
由于短语的频率可以是不区分大小写或区分大小写的,因此短语 a friend has a frequency of 2 and the has a frequency of 6, and travels 出现了2次。
N-gram
文本可以拆分为一组固定长度的单词序列,单个单词(一元组)、两个单词(二元组)、三个单词(三元组)或任意数量的单词(N-gram)。
例如,the quick red fox jumped over the lazy brown dog 的 N-gram 得分为2,产生以下N-gram:
- the quick
- quick red
- red fox
- fox jumped
- jumped over
- over the
- the lazy
- lazy brown
- brown dog
将其可视化为滑动窗口会更简单。这里是3词N-gram的情况,N-gram在每个句子中用粗体表示:
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog

N-gram值为3:信息图由Jen Looper制作
名词短语提取
在大多数句子中,有一个名词是句子的主语或宾语。在英语中,它通常前面有'a'或'an'或'the'。通过“提取名词短语”来识别句子的主语或宾语是在自然语言处理中理解句子含义的常见任务。
✅ 在句子“I cannot fix on the hour, or the spot, or the look or the words, which laid the foundation. It is too long ago. I was in the middle before I knew that I had begun.”中,你能识别出名词短语吗?
在句子 the quick red fox jumped over the lazy brown dog 中有两个名词短语:quick red fox 和 lazy brown dog。
情感分析
句子或文本可以通过情感进行分析,即正面或负面的程度。情感以polarity和客观性/主观性来衡量。极性从-1.0到1.0(负到正)和0.0到1.0(最客观到最主观)来测量。
✅ 后续课程中你会学到,使用机器学习来确定情感有不同的方法,但一种方法是使用人类专家分类的正面或负面词汇和短语列表,并将该模型应用于文本以计算极性得分。你能在某些情况下看到这种方法如何运作,但在其他情况下效果较差吗?
词形变化
词形变化使您能够获取一个词的单数或复数形式。
词形还原
词根是一组词的根或基本形式,例如flew、flies、flying 的词根是动词fly。
还有一些对自然语言处理研究人员有用的数据库,特别是:
WordNet
WordNet 是一个包含多种语言中每个单词的同义词、反义词等详细信息的数据库。在构建翻译、拼写检查器或其他类型的语言工具时,它非常有用。
自然语言处理库
幸运的是,您不必自己构建所有这些技术,因为有一些优秀的Python库可用,使那些不专门从事自然语言处理或机器学习的开发人员更容易上手。接下来的课程包括更多示例,但这里您将学习一些有用的示例来帮助您完成下一个任务。
练习 - 使用 TextBlob library
Let's use a library called TextBlob as it contains helpful APIs for tackling these types of tasks. TextBlob "stands on the giant shoulders of NLTK and pattern, and plays nicely with both." It has a considerable amount of ML embedded in its API.
Note: A useful Quick Start guide is available for TextBlob that is recommended for experienced Python developers
When attempting to identify noun phrases, TextBlob offers several options of extractors to find noun phrases.
-
Take a look at
ConllExtractorfrom textblob import TextBlob from textblob.np_extractors import ConllExtractor # import and create a Conll extractor to use later extractor = ConllExtractor() # later when you need a noun phrase extractor: user_input = input("> ") user_input_blob = TextBlob(user_input, np_extractor=extractor) # note non-default extractor specified np = user_input_blob.noun_phrases这里发生了什么?ConllExtractor 是“一个使用 ConLL-2000 训练语料库训练的名词短语提取器”。ConLL-2000 指的是2000年的计算自然语言学习会议。每年该会议都会举办一个研讨会来解决棘手的自然语言处理问题,2000年是名词切分。该模型在《华尔街日报》上进行了训练,使用“第15至18部分作为训练数据(211727个标记)和第20部分作为测试数据(47377个标记)”。您可以在这里查看所用的程序(https://www.clips.uantwerpen.be/conll2000/chunking/) 和结果(https://ifarm.nl/erikt/research/np-chunking.html)。
挑战 - 使用自然语言处理改进您的机器人
在上一课中,您构建了一个非常简单的问答机器人。现在,您将通过分析输入的情感并打印出匹配情感的响应来使Marvin更具同情心。您还需要识别一个名词短语并询问有关该主题的信息。
构建更好的对话机器人的步骤:
- 打印说明,告知用户如何与机器人交互
- 开始循环
- 接受用户输入
- 如果用户请求退出,则退出
- 处理用户输入并确定适当的情感响应
- 如果检测到名词短语,则将其复数化并询问关于该主题的更多信息
- 打印响应
- 返回步骤2
以下是使用TextBlob确定情感的代码片段。注意只有四个梯度的情感响应(如果您喜欢,可以有更多的梯度):
if user_input_blob.polarity <= -0.5: response = "Oh dear, that sounds bad. " elif user_input_blob.polarity <= 0: response = "Hmm, that's not great. " elif user_input_blob.polarity <= 0.5: response = "Well, that sounds positive. " elif user_input_blob.polarity <= 1: response = "Wow, that sounds great. "
以下是一些样本输出以供参考(用户输入以>开头的行):
Hello, I am Marvin, the friendly robot. You can end this conversation at any time by typing 'bye' After typing each answer, press 'enter' How are you today? > I am ok Well, that sounds positive. Can you tell me more? > I went for a walk and saw a lovely cat Well, that sounds positive. Can you tell me more about lovely cats? > cats are the best. But I also have a cool dog Wow, that sounds great. Can you tell me more about cool dogs? > I have an old hounddog but he is sick Hmm, that's not great. Can you tell me more about old hounddogs? > bye It was nice talking to you, goodbye!
一个可能的解决方案在此(https://github.com/microsoft/ML-For-Beginners/blob/main/6-NLP/2-Tasks/solution/bot.py)
✅ 知识检查
- 您认为这些同情响应是否会“欺骗”某人相信机器人实际上理解他们?
- 识别名词短语是否会使机器人更具可信度?
- 为什么从句子中提取“名词短语”是有用的?
实现前一个知识检查中的机器人,并在朋友身上测试它。它能骗过他们吗?你可以让你的机器人更“可信”吗?
挑战
尝试实现前一个知识检查中的一个任务。在朋友身上测试机器人。它可以骗过他们吗?你能让你的机器人更“可信”吗?
课后测验
复习与自学
在接下来的几节课中,您将学习更多关于情感分析的知识。研究这种有趣的技术,如这些文章(https://www.kdnuggets.com/tag/nlp) 中的文章。
作业
声明:
本文件灏天文库团队进行了翻译。尽管我们力求准确,但请注意,翻译可能包含错误或不准确之处。原文档以其原始语言为准。我们不对因使用此翻译而产生的任何误解或误译负责。