多模态网络
文档摘要
多模态网络 在解决自然语言处理(NLP)任务的成功之后,类似的架构也被应用于计算机视觉任务。构建能够将视觉和自然语言能力结合在一起的模型的兴趣日益增长。其中一个尝试是由OpenAI完成的,称为CLIP和DALL·E。 对比图像预训练(CLIP) CLIP的主要思想是能够比较文本提示与图像,并确定该图像与提示的相关程度。 CLIP架构 图片来自这篇博客文章 该模型是在从互联网获取的图像及其标题上进行训练的。对于每个批次,我们选取N对(图像,文本),并将其转换为一些向量表示I 1 ,..., I N / T 1 , ..., T N 。然后将这些表示匹配在一起。损失函数被定义为最大化一对对应向量(如I i 和 T i )之间的余弦相似度,同时最小化与其他所有对之间的余弦相似度。
多模态网络
在解决自然语言处理(NLP)任务的成功之后,类似的架构也被应用于计算机视觉任务。构建能够将视觉和自然语言能力结合在一起的模型的兴趣日益增长。其中一个尝试是由OpenAI完成的,称为CLIP和DALL·E。
对比图像预训练(CLIP)
CLIP的主要思想是能够比较文本提示与图像,并确定该图像与提示的相关程度。
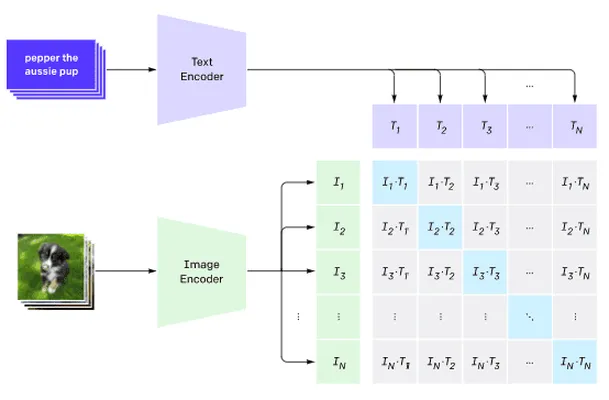
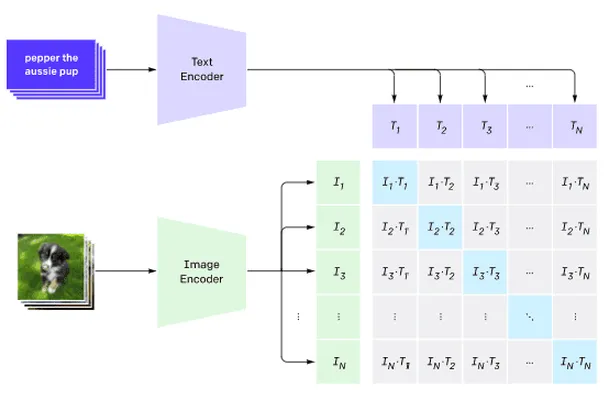
图片来自这篇博客文章
该模型是在从互联网获取的图像及其标题上进行训练的。对于每个批次,我们选取N对(图像,文本),并将其转换为一些向量表示I1,..., IN / T1, ..., TN。然后将这些表示匹配在一起。损失函数被定义为最大化一对对应向量(如Ii 和 Ti)之间的余弦相似度,同时最小化与其他所有对之间的余弦相似度。这就是这种方法被称为对比的原因。
CLIP模型/库可以从OpenAI GitHub获得。该方法在这篇博客文章中有所描述,并且在这篇论文中有更详细的说明。
一旦模型预训练完成,我们可以给它一批图像和一批文本提示,它将返回一个包含概率的张量。CLIP可以用于多个任务:
图像分类
假设我们需要对猫、狗和人类的图像进行分类。在这种情况下,我们可以给模型一张图像和一系列文本提示:“一张猫的照片”、“一张狗的照片”、“一张人的照片”。在结果的三个概率向量中,我们只需要选择最高值对应的索引。
图片来自这篇博客文章
基于文本的图像搜索
我们也可以反向操作。如果我们有一批图像,我们可以将这批图像传递给模型,再加上一个文本提示——这将给我们最接近给定提示的图像。
✍ 示例:使用CLIP进行图像分类和图像搜索
打开Clip.ipynb笔记本以查看CLIP的实际应用。
使用VQGAN+CLIP生成图像
CLIP还可以通过文本提示来生成图像。为了实现这一点,我们需要一个生成器模型,该模型可以根据某些向量输入生成图像。其中一个这样的模型被称为VQGAN(向量化量化生成对抗网络)。
VQGAN与普通生成对抗网络(GAN)的主要区别在于:
- 使用自回归变压器架构生成由CNN学习的一系列丰富的上下文视觉部分组成的图像。
- 使用子图像判别器检测图像的各个部分是否“真实”或“伪造”(不同于传统GAN的“全有或全无”方法)。
更多关于VQGAN的信息可以在Taming Transformers网站上找到。
VQGAN与传统GAN之间的一个重要区别在于,后者可以从任何输入向量生成一张合理的图像,而VQGAN生成的图像可能不连贯。因此,我们需要进一步引导图像创建过程,这可以通过CLIP来实现。
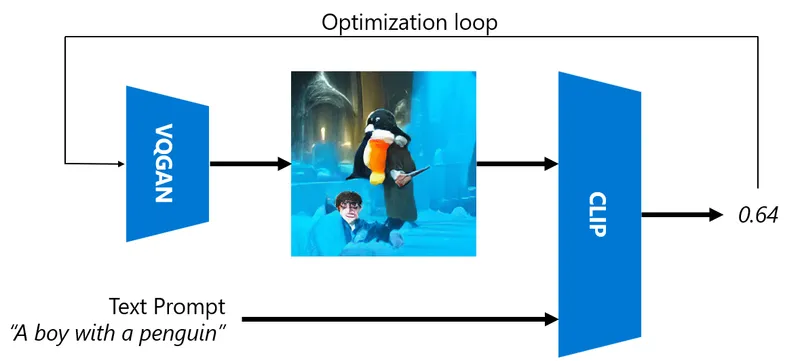
为了生成与文本提示相对应的图像,我们从一个随机编码向量开始,通过VQGAN生成图像。然后,CLIP用于生成一个损失函数,该函数显示图像与文本提示的对应程度。目标是最小化这个损失,通过反向传播调整输入向量参数。
一个实现了VQGAN+CLIP的伟大库是Pixray
 |
 |
 |
|---|---|---|
| 根据提示“一张近距离水彩肖像画,年轻的男性文学教师拿着一本书”生成的图片 | 根据提示“一张近距离油画肖像画,年轻的女性计算机科学教师拿着一台电脑”生成的图片 | 根据提示“一张近距离油画肖像画,年老的男性数学教师站在黑板前”的图片 |
图片来自Dmitry Soshnikov的《人工智能教师》系列
DALL·E
DALL·E 1
DALL·E是GPT-3的一个版本,它经过训练可以从提示生成图像。它拥有120亿个参数。
与CLIP不同,DALL·E接收文本和图像作为单一流中的标记。因此,从多个提示中,你可以根据文本生成图像。
DALL·E 2
DALL·E 1和DALL·E 2之间的主要区别在于,后者生成更逼真和艺术化的图像。
使用DALL·E生成的图像示例:
 |
 |
 |
|---|---|---|
| 根据提示“一张近距离水彩肖像画,年轻的男性文学教师拿着一本书”生成的图片 | 根据提示“一张近距离油画肖像画,年轻的女性计算机科学教师拿着一台电脑”生成的图片 | 根据提示“一张近距离油画肖像画,年老的男性数学教师站在黑板前”生成的图片 |
参考文献
- VQGAN论文:驯服变压器进行高分辨率图像合成
- CLIP论文:从自然语言监督中学习可迁移的视觉模型
声明:
本文件灏天文库团队进行了翻译。尽管我们力求准确,但请注意,翻译可能包含错误或不准确之处。原文档以其原始语言为准。我们不对因使用此翻译而产生的任何误解或误译负责。