Meta-Chunking:一种新的文本切分策略
文档摘要
Meta-Chunking 该章节大部分内容将围绕着论文中提到的新技术和架构设计展开,FusionANNS部分有一个Demo代码,但并没有调用GPU,也没有充分的利用SSD进行存储。主要原因是架构设计过于庞大难以实现,属于整体项目架构方面,但本文中介绍的Meta-Chunking框架,在RAG系统中是极为重要的,数据分块的质量将直接影响到问答系统的召回率。低效的分块策略会导致上下文不完整或包含过多无关信息,从而损害问答系统的性能。 但在RAG的流程中,文本分块往往是容易被忽视的关键环节,这篇论文中提出Meta-Chunking这一元分块框架,通过识别最优分割点与保留全局信息的双重策略,专门提升分块质量。
Meta-Chunking
该章节大部分内容将围绕着论文中提到的新技术和架构设计展开,FusionANNS部分有一个Demo代码,但并没有调用GPU,也没有充分的利用SSD进行存储。主要原因是架构设计过于庞大难以实现,属于整体项目架构方面,但本文中介绍的Meta-Chunking框架,在RAG系统中是极为重要的,数据分块的质量将直接影响到问答系统的召回率。低效的分块策略会导致上下文不完整或包含过多无关信息,从而损害问答系统的性能。
但在RAG的流程中,文本分块往往是容易被忽视的关键环节,这篇论文中提出Meta-Chunking这一元分块框架,通过识别最优分割点与保留全局信息的双重策略,专门提升分块质量。
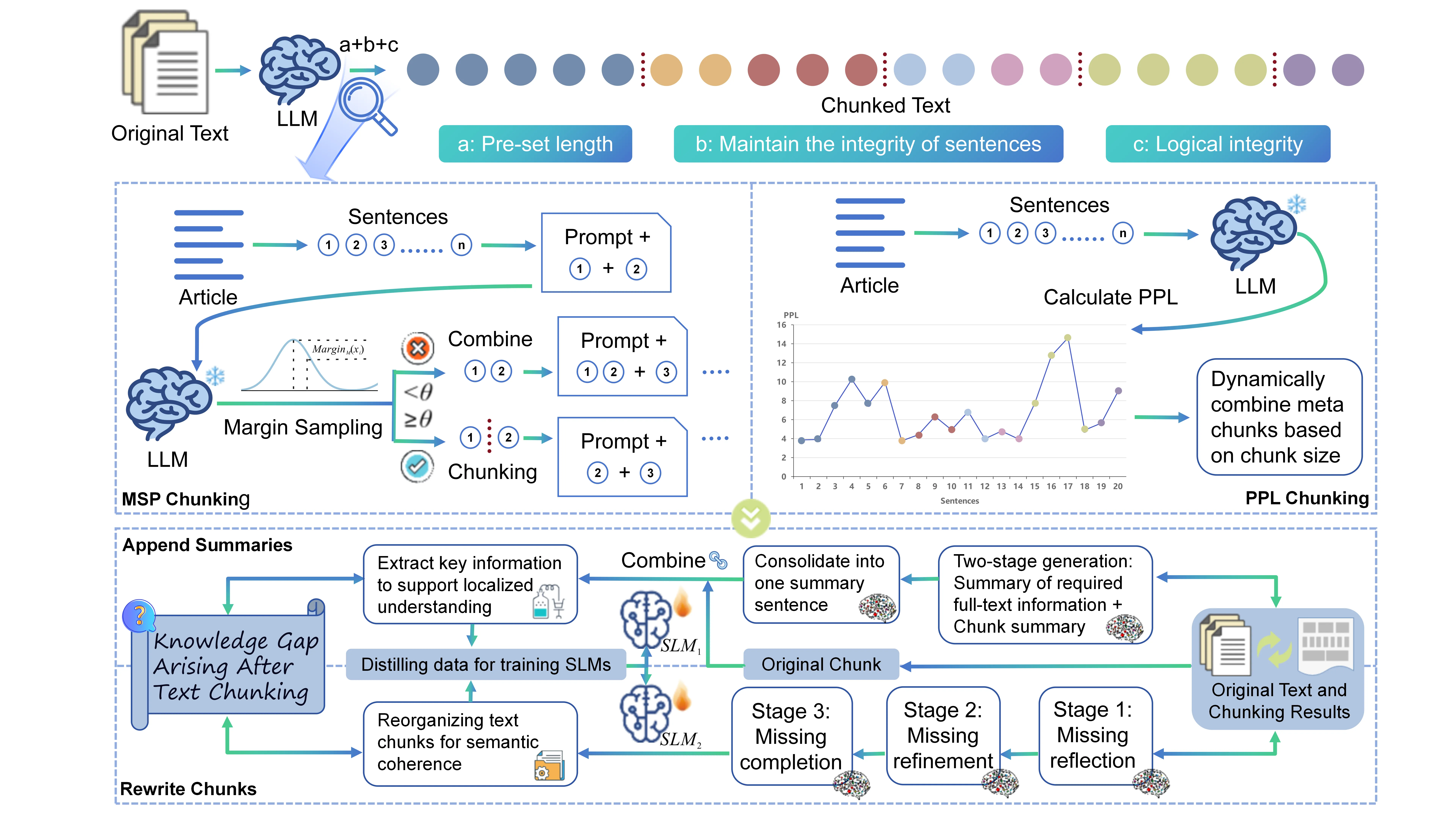
如图 1 所示,Meta-Chunking融合了传统文本分块策略的优势,例如遵循预设的分块长度约束和确保句子结构完整性,同时增强了在分块过程中保证逻辑连贯性的能力。我们将通过分块获得的每个文本块称为元块(Meta-Chunk),它由段落中按顺序排列的句子集合组成。这些句子不仅具有语义相关性,更重要的是还包含深层次的语言逻辑联系,包括但不限于总分、并列、递进和例证等关系。
该方法基于一个核心理念:通过允许分块大小的可变性,更有效地捕捉并保持内容的逻辑完整性。这种动态调整的粒度控制确保每个分割后的块都包含完整且独立的思想表达,从而避免分割过程中出现逻辑链条断裂。这不仅提升了文档检索的相关性,同时也增强了内容的清晰度。
首先突破基于相似度的分块局限,我们利用LLM的能力,设计了两种基于不确定性的自适应分块技术Perplexity Chunking(PPL) and Margin Sampling Chunking(MSP) 针对不同文本的固有复杂性,我们通过动态合并实现元分块,在细粒度与粗粒度文本分块间取得平衡。此外,我们建立了全局信息补偿机制,包含两阶段层次化摘要生成流程与聚焦缺失反思、精修和补全的三阶段文本块重写过程。这些组件共同增强了文本块的语义完整性与上下文连贯性。
对于一些论文中提到的专业术语,我们进行了翻译和解释:
-
Through lightweight chunking algorithm design, the logical analysis capability of LLMs is decoupled into computable the PPL features and MSP indicators, achieving identification of textual logical boundaries and dynamic balance of chunking granularity.
• 通过轻量级分块算法设计,将 LLMs 的逻辑分析能力解耦为可计算的 PPL 特征和 MSP 指标,实现文本逻辑边界的识别与分块粒度的动态平衡。
-
We establish a information compensation mechanism that collaboratively executes through a three-stage missing-aware rewriting process and a two-stage context-aware summary generation, repairing the semantic discontinuities in text chunks.
• 我们建立了信息补偿机制,通过三阶段缺失感知重写流程与两阶段上下文感知摘要生成的协同执行,修复文本块中的语义断裂问题。
下面将正式进入论文的详细介绍部分,首先你需要了解文章中提出的两个非常重要的概念,同时也是论文提出的分块的两种策略:
- PPL (Perplexity):困惑度是自然语言处理中一个常用的评价指标,用于衡量一个概率模型预测样本的能力。简单来说,它评估了语言模型在预测下一个词时的不确定性。较低的困惑度意味着模型对文本的理解更好,能够更准确地预测下一个词。因此,在轻量级分块算法设计中,PPL 特征可能被用来作为衡量文本逻辑连贯性的一个标准,以帮助识别文本的逻辑边界。
- MSP (Most Significant Passage):虽然“MSP”这个缩写在特定领域可能有多种含义,但在这里,我们可以假设它指的是“最重要段落”或“最具代表性片段”。在给定的语境下,MSP 指标可能是用于识别文本中最能代表其主要内容或主题的部分。通过计算每个分块的重要性或代表性,可以帮助实现分块粒度的动态平衡,确保每个分块既不过于细碎也不过于笼统,从而更好地保持原始文本的逻辑结构和信息完整性。
策略一 Perplexity Calculation per Sentence (PPL困惑度)
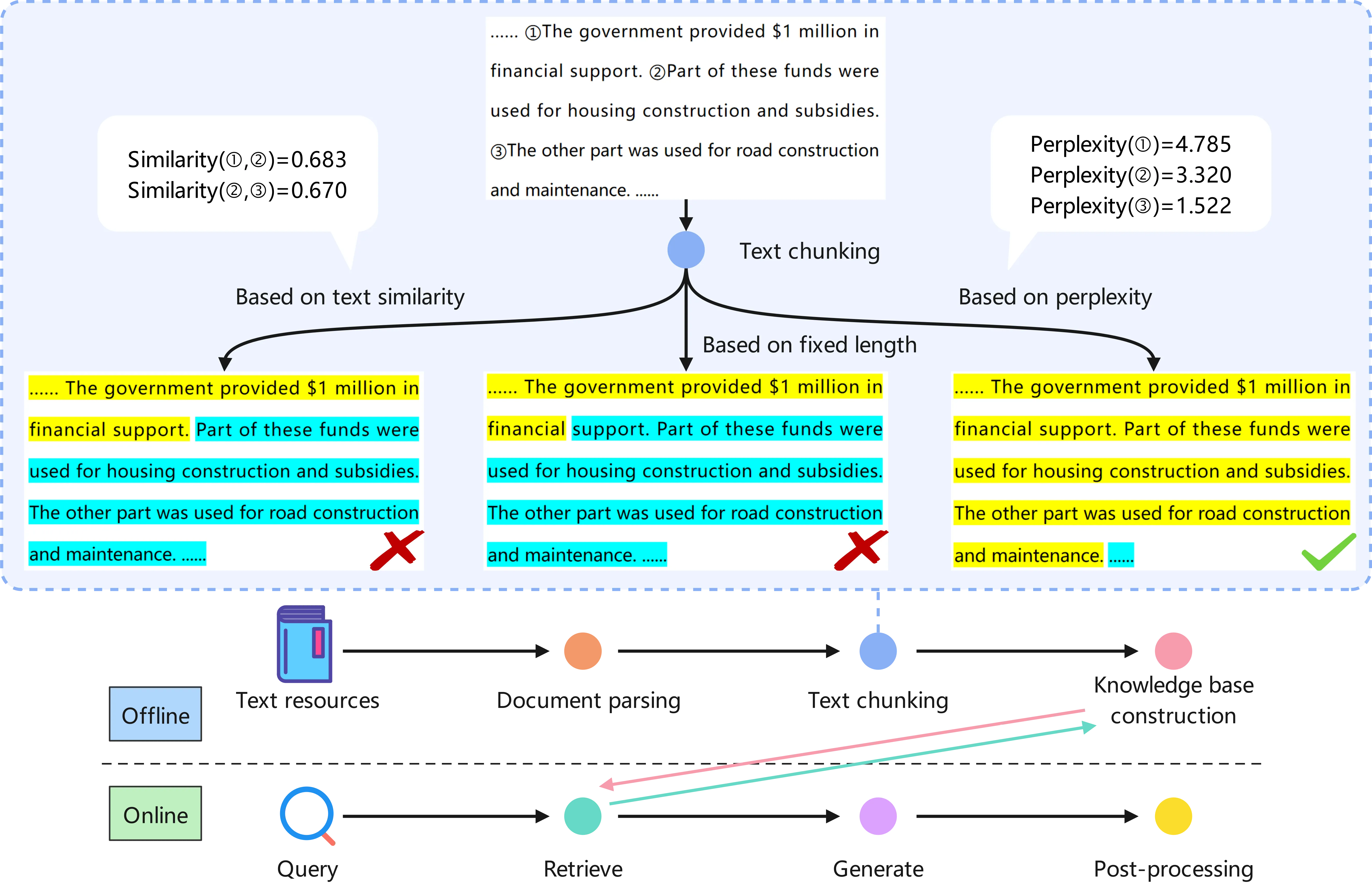
如上图所示,根据PPL困惑度来处理文本分块的效果将比传统的固定分块以及文本相似度分块的要好。
PPL(困惑度,Perplexity)是衡量语言模型预测能力的一个指标,用于量化模型对文本的预测难度。用一句话来说:给定一个上下文T,对于T的下一个词 t_i,PPL表示大语言模型(LLM)在T的基础上,对 t_i 的预测难度。在论文提出的Meta - Chunking框架中,基于模型计算PPL并实现文本分块的具体流程可分为预处理、PPL计算、边界识别、动态调整四个核心步骤,每个步骤都与模型的能力深度绑定,具体实现细节如下:
1. 预处理:文本拆分与序列构建
- 句子拆分:将原始文本按标点符号(如句号、问号)拆分为独立句子,形成句子序列 (x_1, x_2, ..., x_n)。例如,将“动物迁徙由多种因素驱动。气候周期性变化影响最大。”拆分为 x_1=“动物迁徙由多种因素驱动”、x_2=“气候周期性变化影响最大”。
- 上下文准备:为每个句子 x_i 构建其“前文语境”,即包含 x_i 之前的所有句子(x_1 到 x_{i-1})的token序列 t_{\lt i},作为模型预测的上下文输入。目标是将这些句子划分为若干语义连贯的块 (X_1, X_2, ..., X_k)。例如,当拆分为 x_1=“动物迁徙由多种因素驱动”、x_2=“气候周期性变化影响最大”时, x_2 的前文语境 t_{\lt 2} 就是 x_1 的所有token。
2. PPL计算:模型预测与概率聚合
-
模型输入构造:对于句子 x_i 中的每个token t_k^i(如“气候”“影响”等),模型的输入为“前文语境 t_{\lt i} + 句子 x_i 中该token之前的所有token t_{\lt k}^i”。例如,计算 x_2 中“影响”的概率时,输入为“动物迁徙由多种因素驱动。气候周期性变化”。
-
条件概率预测:模型(如Qwen2-7B、Baichuan2-7B等,为了效果,你可以选择参数量更大的模型,但我们用的只是大模型所提供的大参数量和性能,而不是让模型直接告诉你在哪里分块)基于输入的上下文,预测每个token t_k^i 出现的条件概率 P(t_k^i | t_{\lt k}^i, t_{\lt i})。能力越强的模型,越能根据逻辑关联输出合理概率(如“气候”后接“影响”的概率高于接“电脑”)。 所以,这里模型最终输出的是什么呢?你可以先往下翻找,下文 PPL 的计算算法基础 这一部分里面的开头写道:
PPL 的计算核心基于交叉熵。公式为 PPL = 2^{H},其中交叉熵 H = -\frac{1}{N} \sum_{i=1}^{N} \log_2 p(w_i | w_1, w_2, ..., w_{i-1}),N 表示测试集中单词总数,p(w_i | w_1, w_2, ..., w_{i-1}) 表示给定前面所有词的情况下第 i 个词的条件概率。
其中,p(w_i | w_1, w_2, ..., w_{i-1}) 就是模型最后输出的内容。
-
单句PPL聚合:对句子 x_i 中所有token的概率取平均值,得到该句子的PPL值:
[
PPL_M(x_i) = \frac{\sum_{k=1}^{K} PPL_M(t_k^i | t_{<k}^i, t_{<i})}{K}
]
其中,K 为句子 x_i 的token总数,PPL值越低表示模型对该句子的预测越“确定”(与前文逻辑越连贯)。
3. 边界识别:基于PPL序列的分割点定位
- PPL序列生成:将所有句子的PPL值按顺序排列,形成序列 PPL_{seq} = (PPL(x_1), PPL(x_2), ..., PPL(x_n))。例如,若 x_1 到 x_3 的PPL值为5.2、3.1、6.8,则序列为 (5.2, 3.1, 6.8)。
- 最小值点检测:算法聚焦于PPL序列中的两类最小值点(潜在分割点):
- 某点两侧的PPL值均高于该点,且至少一侧差值超过阈值 \theta(如 x_2 的PPL=3.1,左侧 x_1=5.2、右侧 x_3=6.8,若 \theta=2,则 x_2 是分割点);
- 左侧PPL值与该点的差值超过 \theta,且右侧PPL值等于该点(如 x_2=3.1,左侧差值5.2-3.1=2.1>θ,右侧 x_3=3.1)。
- 分割逻辑:这些最小值点表明模型对该句子的预测“突然变容易”,暗示其与前后文的逻辑关联较弱,因此将其作为分块边界。例如,上述序列中 x_2 是分割点,分块结果为 (x_1), (x_2, x_3)。
4. 动态调整:解决长文本与粒度平衡问题
- KV缓存机制:当文本过长(超出模型上下文长度或GPU内存限制)时,算法会动态移除前文部分文本的键值对(KV pairs),在不显著损失上下文连贯性的前提下,确保PPL计算可执行。例如,处理1000句长文本时,仅保留最近200句的KV缓存用于后续句子的PPL计算。
- 动态合并策略:先通过PPL Chunking得到“元块”(meta-chunk,即逻辑完整的句子组),再根据用户指定的chunk长度 L 合并相邻元块。例如,若元块长度分别为 c_1=50、c_2=40、c_3=30,且 L=110,则合并 c_1+c_2+c_3=120(接近 L)作为最终分块。
比如,对于存在一般-特殊(x \supset y)、并列(x | y)、递进(x \to y)等逻辑关系的句子序列,PPL值呈现逐渐下降的趋势,说明句子间逻辑连贯,应被划分为同一分块;而若某句子的PPL值突然升高,则表明其与前文逻辑关联较弱,需分割。
例如:
- 句子序列“动物迁徙由多种因素驱动。气候周期性变化影响最大,其次是食物资源分布。基因特征也起重要作用。”的PPL值依次为5、4.37、3.33,呈现下降趋势,应合并为一个块;
- 若中间插入一句PPL值为8的句子(如“汽车产业的发展依赖技术创新”),则该句与前后文逻辑脱节,PPL值显著升高,应作为分割点。
- 再以句子序列“小明喜欢运动。他每天早上跑步。天空是蓝色的。”为例:
- 模型计算 x_1(小明喜欢运动)的PPL时,因无前文,PPL值较高(如6.5);
- 计算 x_2(他每天早上跑步)时,模型基于“小明喜欢运动”的上下文,预测“跑步”等词的概率高,PPL值低(如3.2);
PPL 与模型的关系及模型在 PPL 计算中的作用
PPL(困惑度)是衡量语言模型预测能力的指标,有人可能会疑惑:PPL 只是通过算法实现的,没用到大模型的能力吗?其实不是的,PPL 的计算本身基于算法,但在实际应用,尤其是与大模型相关的场景下,会借助大模型的能力。
PPL 的计算算法基础
PPL 的计算核心基于交叉熵。公式为 PPL = 2^{H},其中交叉熵 H = -\frac{1}{N} \sum_{i=1}^{N} \log_2 p(w_i | w_1, w_2, ..., w_{i-1}),N 表示测试集中单词总数,p(w_i | w_1, w_2, ..., w_{i-1}) 表示给定前面所有词的情况下第 i 个词的条件概率。在计算时,需要准备未参与模型训练的文本数据,利用已训练好的模型计算每个词的条件概率,再求解交叉熵,最终得到 PPL。从这个计算流程看,PPL 计算依赖的是概率计算和数学公式,是算法层面的实现。在涉及主题建模(如 LDA 主题模型)时,困惑度可通过语料似然值间接计算,依赖于文档的主题分布和词语在各主题下的分布,这同样是基于特定算法的计算方式。
PPL 计算依赖大模型能力
在论文《Meta-Chunking: Learning Text Segmentation and Semantic Completion via Logical Perception》中,PPL 被用于文本分块任务,计算时要先将文本分割为句子序列,再用模型计算每个句子基于前文的 PPL 值。这里计算 PPL 所依赖的模型,实际上就是大语言模型(LLMs)。在实际应用中,大模型的训练过程是对大量文本数据中语言模式和规律的学习,其目的之一就是让模型在预测下一个词时更加准确,而 PPL 正是衡量这种预测准确性的指标。如果大模型没有学习到语言的逻辑和语义关系,就无法准确计算出反映句子间逻辑连贯性的 PPL 值。
PPL 在大模型性能评估中的应用
PPL 在评估大模型性能方面有重要作用。通过计算 PPL,可以了解大模型对文本的理解和预测能力。在模型训练过程中,PPL 可用于监控模型的收敛状态,帮助调整模型的训练参数。研究发现 PPL 与准确率存在强负相关性,可作为模型置信度指标,以此开发基于 PPL 的动态推理决策框架,在低置信度场景(PPL 超过阈值)下触发长文本推理,在高置信度场景直接输出简短答案,提升推理效率和准确性。这一系列应用都依赖于大模型对语言的理解和处理能力,PPL 作为衡量指标与之紧密结合。
在计算每个句子基于前文的 PPL 值时,模型(如论文中使用的 LLMs 或 SLMs)起到了核心的概率预测作用,是 PPL 值能够反映句子间逻辑连贯性的关键。具体来说,模型的作用体现在以下三个方面:
-
模型提供“条件概率预测”的能力
PPL 的本质是通过模型对文本序列中“下一个 token”的预测概率来衡量句子间的逻辑关联,而这种概率预测完全依赖模型的语言理解能力。
对于句子 x_i 中的每个 token t_k^i,模型需要计算其在“前文所有信息(即 t_{\lt i},也就是 x_i 之前的所有句子的 token)”和“该句子内部前文 token(t_{\lt k}^i)”条件下的出现概率 P(t_k^i | t_{\lt k}^i, t_{\lt i}) 。
例如,若前文讨论“动物迁徙的原因”,模型会基于已学习的语言规律,预测下一个 token 更可能是“气候”“食物”等相关词汇(概率高),而不是“计算机”“金融”等无关词汇(概率低)。这种预测能力直接来自模型对文本逻辑和语义的理解。 -
模型的“逻辑感知能力”决定 PPL 对分块的指导意义
论文中明确提到,PPL Chunking 的设计核心是利用 LLMs 的逻辑感知能力,通过 PPL 值捕捉句子间的深层逻辑关系(如递进、并列、因果等),而非表面的语义相似性 。
模型在训练过程中学习了文本中隐藏的逻辑结构(如“因为 A,所以 B”的因果关系会让模型对 B 的预测概率更高),因此其输出的 PPL 值能间接反映这种逻辑关联:- 当句子 x_i 与前文逻辑连贯时,模型对 x_i 中 token 的预测更“确定”(概率高),PPL 值低;
- 当 x_i 与前文逻辑断裂时,模型预测更“困惑”(概率低),PPL 值高 。
例如,对于句子序列“小明喜欢运动。他每天早上跑步。”,模型能识别两者的逻辑关联(“喜欢运动”是“跑步”的前提),因此第二句的 PPL 值较低;若改为“小明喜欢运动。天空是蓝色的。”,模型会因逻辑断裂而给出较高的 PPL 值。
-
模型规模与能力影响 PPL 计算的准确性
论文实验表明,不同规模的模型(如 Qwen2 - 0.5B、Qwen2 - 7B、Baichuan2 - 7B)计算的 PPL 值对分块效果有差异,这说明模型的能力直接影响 PPL 的可靠性 。- 能力更强的模型(如更大参数的 LLMs)能更好地理解复杂逻辑关系,其计算的 PPL 值更能准确区分“逻辑连贯”和“逻辑断裂”的边界;
- 即使是小规模模型(SLMs),通过微调后也能学习到基础的逻辑感知能力,从而计算出有效的 PPL 值,这也是论文强调“无需依赖强指令跟随能力的大模型”的原因 。
最后我们对上面关于PPL与模型关系做一个总结:模型只是计算 PPL 值的“核心工具”——它通过学习到的语言规律和逻辑感知能力,为每个 token 的出现概率提供预测(Mask掩码一样),而 PPL 值正是基于这些概率计算得出的。最终,PPL 值的高低能够反映句子间逻辑关联的强弱,本质上是模型对文本逻辑结构的“量化表达”,这也是 PPL 能用于确定分块边界的底层原因。
现在,我们通过公式来更加详细的了解PPL,首先,回忆一下分块的核心目标: 将长文本分割成多个连贯的语块 (X1, X2, ..., Xk),每个语块由连续的句子组成 (xi),并且最终语块的长度尽可能满足用户需求。
我们来看懂这个公式:
-
目标: 量化当前句子 xi 在给定其之前所有文本内容 (x1, x2, ..., xi-1) 的上下文下,语言模型 (LLM M) 对其的“惊讶程度”或“预测难度”。
-
PPL: 困惑度 (Perplexity, PPL) 是衡量语言模型预测能力的一个指标。PPL 越低,表示模型对当前词序列的出现越不感到“困惑”,即该序列在给定上下文中越“自然”、越“可预测”、越“连贯”。
-
公式 (1) 详解:
PPL_M(xi) = ( Σ_{k=1}^{K} PPL_M(t_k^i | t_{\lt k}^i, t_{\lt i}) ) / K- xi: 当前要计算 PPL 的第 i 个句子。
- K: 句子 xi 中包含的 token (词元) 的总数量。例如,xi = “我喜欢苹果” 可能被分词成
["我", "喜欢", "苹果"],那么 K=3。 - t_k^i: 句子 xi 中的第
k个 token。 - t_{\lt k}^i: 句子 xi 中,排在 t_k^i 之前的所有 token。即 xi 句子内部,
t_k^i的上文。 - t_{\lt i}: 所有排在句子 xi 之前的 token。即整个文档中,xi 之前的所有句子的所有 token。这是 xi 的外部上文,提供了最重要的语境。
- PPL_M(t_k^i | t_{\lt k}^i, t_{\lt i}): 核心条件概率计算。 这表示在给定以下两部分的条件下:
- t_{\lt k}^i (句子 xi 内部,t_k^i 之前的 token)
- t_{\lt i} (整个文档中,xi 之前的所有 token)
语言模型M预测出 token t_k^i 的困惑度。更基础的计算通常是模型预测 t_k^i 的概率 P_M(t_k^i | t_{\lt k}^i, t_{\lt i})。PPL 是概率的衍生度量(通常基于概率的对数和平均)。
- Σ_{k=1}^{K} ... / K: 对句子 xi 中的 每一个 token (
k从 1 到K) 计算其条件 PPL,然后将这K个值求和后再除以K(句子 token 总数)。这得到了句子 xi 在整个上下文 (t_{\lt i}) 下的平均 token 级困惑度。这个平均值 PPL_M(xi) 就代表了整个句子 xi 在给定前文 (t_{\lt i}) 下的连贯性/自然度分数。分数越低,句子 xi 与前文的衔接越流畅、越符合预期。
当我们计算完一个句子中,所有的token 的 PPL 后
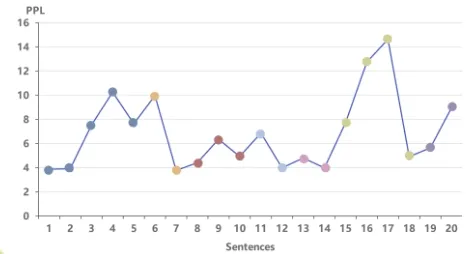
开始构建 PPL 序列 (PPL Sequence Construction):
- 处理:对序列
S中的每一个句子 xi (i 从 1 到 n) 都执行上文的PPL计算,计算其 PPL_M(xi)。 - 输出:得到一个与句子序列对应的 PPL 值序列:PPL_seq = (PPL_M(x1), PPL_M(x2), ..., PPL_M(xn))。
- 关键: 当一个句子 xi 与其前文 (t_{\lt i}) 在语义或话题上发生转换或断裂时,模型预测 xi 的难度会增大,导致 PPL_M(xi) 升高。相反,如果 xi 与前文紧密相关,则 PPL_M(xi) 会相对较低。更重要的是,在话题结束点或新话题开始点附近,我们预期会看到 PPL_seq 中的局部极小值 (local minima)。这些极小值点标识了文本中相对更自然、更连贯的潜在分割位置。
然后开始根据图识别关键分割点 (Finding Segmentation Points - Minima Detection):
- 目标:分析 PPL_{seq},找出可以作为潜在语块边界的点(主要是局部极小值点)。
- 算法关注两类极小值点 (对于点
i, 即句子xi的位置):- 类型 1 (波谷): PPL_M(xi-1) \gt PPL_M(xi) 且 PPL_M(xi+1) \gt PPL_M(xi) 且 (PPL_M(xi-1) - PPL_M(xi) \gt θ 或 PPL_M(xi+1) - PPL_M(xi) \gt θ)。
- 点
i的 PPL 比它左边 (i-1) 和右边 (i+1) 邻居的 PPL 都低(形成一个谷底),并且至少有一侧的下降幅度(左邻居减当前值 或 右邻居减当前值)超过了预设的阈值θ。θ是一个可调参数,用于过滤掉微小的、可能由噪声引起的波动,只关注显著的连贯性转换点。
- 点
- 类型 2 (左悬崖): PPL_M(xi-1) - PPL_M(xi) \gt θ 且 PPL_M(xi+1) == PPL_M(xi)。
- :点
i的 PPL 相比其左邻居 (i-1) 有一个显著的下降(下降幅度 >θ),而其右邻居 (i+1) 的 PPL 与它持平。这通常表示一个话题在 xi 处结束或发生剧变,而 x_i 和 x_{i+1} 可能属于同一个新单元的开头。
- :点
- 类型 1 (波谷): PPL_M(xi-1) \gt PPL_M(xi) 且 PPL_M(xi+1) \gt PPL_M(xi) 且 (PPL_M(xi-1) - PPL_M(xi) \gt θ 或 PPL_M(xi+1) - PPL_M(xi) \gt θ)。
- 输出:一个潜在分割点位置的集合
B = {b1, b2, ..., bm}(例如b1=3,b2=7,b3=12表示建议在句子3后、7后、12后进行分割)。这些点标识了文本中相对连贯的子单元(元块)之间的边界。
生成元块 (Meta-Chunk Formation):
根据分割点集合 B 将句子序列 S 切分开。
最后输出元块序列 MC = (M_{C1}, M_{C2}, ..., M_{Cp})。
- 每个元块 M_{Cj} 由两个相邻分割点之间(或从开头到第一个分割点,或最后一个分割点到结尾)的所有连续句子组成。
- 例如,分割点
B = {3, 7, 12}, 句子总数n=15,则:
* M_{C1} = (x1, x2, x3) (句子1到句子3)
* M_{C2} = (x4, x5, x6, x7) (句子4到句子7)
* M_{C3} = (x8, x9, x10, x11, x12) (句子8到句子12)
* M_{C4} = (x13, x14, x15) (句子13到句子15)
* 下文中,我们将使用论文作者开源的Demo代码进行演示,你可以在运行的时候查看终端,会发现终端中输出了句子的分段编号。 - 元块 M_{Cj} 的特性: 算法认为每个元块内部的句子在给定的上下文(前文)下,具有相对较高的连贯性(由 PPL 极小值点标识其边界)。它们是基于文本自身语义和结构划分出的基础连贯单元。元块的长度是算法根据连贯性自动决定的,通常是不均匀的。
观察上面的M_{Cj},会有一个问题,元块的长度是不均匀的,例如,元块M_{C1}的长度是3,元块M_{C2}的长度是4,元块M_{C3}的长度是5,元块M_{C4}的长度是3。我们并不希望这样,因为这样可以会出现某些元块的长度太长或者太短。因此,一种更好的方法是动态组合元块以满足长度需求。
动态组合元块以满足长度需求 (Dynamic Combination for Final Chunks): - 目标: 用户通常对最终输出语块 (X) 有最大长度限制 L (例如,不超过 512 tokens)。元块 MC_j 本身可能太短或太长。这一步将连续的元块合并,形成最终的语块 X_k,使得每个 X_k 的 token 总数尽可能接近但不超过 L。
- 处理 (贪心策略示例):
- 初始化:从第一个元块 MC_1 开始。
- 当前合并组:
CurrentChunk = [MC1],CurrentLength = len(MC1)(token 数)。 - 遍历后续元块 (MC_2, MC_3, ... MC_p):
- 如果
CurrentLength + len(MC_next)\leq L:- 将
MC_next加入CurrentChunk。 CurrentLength = CurrentLength + len(MC_next)。
- 将
- 否则 (
CurrentLength + len(MC_next)> L):- 将当前的
CurrentChunk输出为一个最终语块 X_k。 - 重置
CurrentChunk = [MC_next]。 - 重置
CurrentLength = len(MC_next)。
- 将当前的
- 如果
- 处理完所有元块后,将剩余的
CurrentChunk输出为最后一个 X_k。
- 输出: 最终语块序列 X = (X_1, X_2, ..., X_k)。
- 每个 X_k 由一个或多个连续的元块 (MC_j) 组成。
- 每个 X_k 的总 token 长度 \leq L (用户设定的最大长度)。
- 关键: 组合发生在元块的边界处。算法不会在一个元块 MC_j 内部(即其连贯句子组内部)进行切割。优先保证了最终语块 X_k 内部包含的是完整的、算法认为连贯的子单元 (元块)。 牺牲的是最终块可能由多个元块组成,但避免了破坏基础的连贯单元。
若文本超出 LLMs 或设备的处理范围,我们会策略性地引入键值(KV)缓存机制:先按 token 将文本分割为若干部分形成多个子序列,随着 PPL 计算的推进,当 GPU 内存即将超过服务器配置或 LLMs 最大上下文长度时,算法会适时移除先前部分文本的 KV 键值对,从而不过度牺牲上下文连贯性。
- KV 缓存: Transformer 模型在计算注意力时会生成 Key (
K) 和 Value (V) 矩阵,代表之前 token 的信息。缓存这些K和V可以避免在预测后续 token 时重新计算前面的所有层,大大加速自回归生成和 PPL 计算。 - 滚动缓存策略 (Rolling Cache Strategy):
- 将整个文本按 token 分成多个子序列 (Segment)。计算第一个子序列的 PPL 时,正常建立并保留其完整的 KV 缓存。当处理到后续子序列,并且累计的 KV 缓存大小接近设备 (GPU) 内存上限或模型最大上下文长度时:策略性地丢弃最早的一部分子序列的 KV 缓存。保留最近、最相关的部分子序列的 KV 缓存。用剩余缓存 + 新 token 继续计算后续句子的 PPL。
- 丢弃部分历史缓存会损失一些远距离的上下文信息,可能轻微影响后续句子 PPL 计算的绝对准确性。但这种方法在内存限制和保持足够连贯性上下文之间取得了平衡,使得处理超长文本成为可能。通常,近期保留的上下文对于保持局部连贯性(即识别局部极小值点)已经足够重要。
边缘采样分块(Margin Sampling Chunking)
首先,为什么要提出边缘采样分块呢?
技术背景与解决的问题
传统RAG在处理长文本时,会首先将长文本切分为多个元块,然后对元块进行分块,最后将分块后的结果进行拼接得到最终的语块;但存在以下三种问题:
- 依赖于特定格式文本生成
- 需要正则表达式提取分块结果
- 在小模型(<7B参数)上性能下降明显
MSP边缘采样分块策略直接分析模型输出的概率分布,无需格式约束,计算复杂度降低,适合场景资源受限的场景,与PPL分块形成互补,覆盖不同类型文本边界,下面我们直接来看公式:
其中
- K_1、K_2表示分割判断时,对Yes/No做出的二元决策。其中Yes决策表示:模型认为"应该分块"的概率,同理No决策表示模型认为"不应该分块"的概率。
- \text{Prompt}(x_i, X') 表示:分块判断提示,构造包括当前句 x_i 和上下文 X 的指令,如:判断句子 x_i 是否应为前文 X 的分块,回答Yes或者No。
- \text{Margin}_M(x_i) 边缘概率差,模型对于两个分块决策的确定性度量,值越小表示决策越不稳定。换句话说,当模型对某段文本是否应该分块的判断变得模糊不清时,这种不确定性往往出现在语义边界处,此时应该考虑在该位置进行分块。
随后,通过将 \text{Margin}_M(x_i) 与阈值 \theta 进行对比,就能得出这两个句子是否应被分割的结论。
动态阈值机制
此外,为决策标准设定阈值是所有策略的普遍要求,为此我们引入了动态阈值机制。具体而言:
- 在 \theta 的初始化阶段,我们为其赋予 0 的初始值,你可以设置为0。
- 随后,我们通过追踪历史 \text{Margin}_M(x_i) 值并计算其平均值来微调 \theta,从而实现更灵活的分块调整。
但是!单纯通过调整阈值控制分块大小可能导致随着阈值增大出现分块尺寸不均的问题,比如某些分块过长而另一些过短,这会影响后续检索的效果。为此,我们提出元分块与动态合并相结合的策略,旨在灵活应对不同分块要求。
首先,采用 PPL 分块或 MSP 分块将文档划分为若干元分块,记作 (c_1, c_2, \ldots, c_{\alpha})。传统分块方法将句子视为独立逻辑单元,而我们则将元分块作为独立逻辑单元。元分块是基于文本自身语义和结构划分出的基础连贯单元,内部句子具有相对较高的连贯性。
随后,根据用户指定的分块长度 L,迭代合并相邻元分块直至总长度满足或接近要求。具体而言,我们会按顺序尝试合并相邻的元分块。若当前合并的元分块总长度刚好等于 L,或者当前合并的元分块总长度小于 L,但再加入下一个元分块后总长度就会超过 L,则将当前合并的这些元分块视为一个完整分块。
例如,若满足
至此,我们得到了符合我们要求的(语义分割、块大小)数据块。
全局信息补偿机制
然而,即使采用了上述精心设计的分块策略,文本分割过程仍然不可避免地会带来语义断裂问题。这种断裂主要表现在以下几个方面:
- 跨块引用断裂:当一个概念在块A中首次定义,但在块B中被引用时,块B的读者可能无法理解该引用的含义。例如,"根据前述的马尔可夫假设..."这样的表述在独立的文本块中会失去其指代对象。
- 逻辑链条中断:复杂的论证过程往往跨越多个段落,当这些段落被分割到不同块中时,每个块的逻辑完整性都会受损。比如,"因此可以得出..."这样的结论性语句如果缺少前提条件,就会变得难以理解。
- 上下文信息缺失:某些专业术语或概念需要特定的背景知识才能理解,当这些背景信息被分散到其他块中时,会影响当前块的可理解性。
为解决这些根本性问题,我们提出了一种全局增强的文本重写与摘要生成机制。该机制的核心思想是:通过智能识别和补充缺失信息,修复分块过程中产生的语义鸿沟,同时为每个文本块生成包含全局上下文的增强摘要。
具体而言,我们利用 LLM 作为判别器来检测每个分块是否存在语义缺失,若存在则触发上述的重写流程,包括:
三阶段语义补全流程
1. 缺失内容识别
借助大语言模型(LLM),再结合预处理阶段找到的相关信息,对每个文本片段进行深入分析。这一步的主要任务是找出当前片段里缺失的前提条件、背景知识、相关事实或者结论。大语言模型要把缺失信息的地方都列出来,还得说清楚需要补充什么内容。
2. 缺失信息精炼
在这一阶段,我们会对前一步检测出来的可能缺失的信息进行打分和筛选。这么做是为了避免添加一些无关或者错误的内容,保证补充信息的准确性。
3. 缺失信息补全
根据上一阶段确定的缺失位置和需要补充的信息,让大语言模型(LLM)把这些信息和当前的文本块整合在一起。最终目标是生成一个上下文连贯、读起来自然的新文本块,让不同文本块之间的信息能很好地融合。
上下文感知摘要生成
处理完这些缺失后,我们在上下文感知摘要生成对所有分块执行摘要生成以进一步提升召回率,为最终提升问答性能奠定坚实基础。
这部分的主要目的是为每个文本块生成简洁但包含全局信息的摘要,让文本块能更好地感知上下文。
生成补充摘要
模型会利用全局信息,为目标文本块生成一个补充摘要。这么做是为了弥补文本块在分割过程中可能丢失的语篇背景和外部关联信息。
生成局部摘要并融合
模型会单独对文本块的内容进行概括,生成一个总结核心观点的局部摘要。然后把这个局部摘要和前面生成的补充摘要融合提炼,得到一个能从全局角度介绍文本块内容的增强版摘要。
下面的内容更多的是一些数学公式的证明和难以理解的知识,可以选择不看,看了其实效果也并不明显,我们希望能从这篇论文中学习到新的文本分割的策略,所以,请将该文档往下翻,直接看Demo这一章节。
模型训练与损失函数
为了让我们提出的改写和摘要生成功能更好用,我们按照上面说的流程,分别为这两个功能构建了 20,000 个训练数据样本。同时,我们选择对小型语言模型(SLM)的所有参数进行微调。
对于输入序列 X 和目标输出序列 Y=(y_1, y_2, \ldots, y_T),损失函数定义如下:
其中:
- P(y_t|y_{\lt t}, X;\theta) 表示模型在给定输入 X 和之前生成的内容 y_{\lt t} 时,预测出真实目标标记 y_t 的概率
- \theta 表示模型的参数
- N 表示一批次里的样本数量
关于数据集构建和微调时超参数的具体配置,可以查看附录 C。
附录 C:语义补全详细流程
C.1 语义补全的必要性
当原文被分割为孤立文本块时,每个文本块可能丢失跨块上下文关联、全局结构连贯性或隐含逻辑关系,从而引发以下问题:
- 信息不完整:关键细节被截断或分散在多个文本块中(例如:某公式定义在块A,而公式应用却在块C)
- 语义不连贯:文本块间的逻辑关系断裂(例如:原因陈述与结果分析被分割在不同块中)
- 噪声干扰:无关内容被错误地包含在文本块中(例如:将举例说明与核心论点混合)
通过采用全局增强的重写与摘要生成技术,我们能够为每个文本块补充缺失的全局信息,弥合语义断层,最终提升RAG系统的响应质量。
C.2 语义补全实施步骤
C.2.1 信息缺口识别阶段
我们首先采用QwQ-32B模型的长推理模式(可处理超长文本的特殊模式),全面识别以下类型的信息缺口:
- 明确引用但未定义的术语
- 需要前文信息才能理解的代词指代
- 跨章节的逻辑依赖关系
- 分散在不同位置的相关数据
C.2.2 补充信息过滤阶段
使用ERNIE-3.5-128K模型对潜在补充内容进行评分与过滤,具体指标包括:
- 相关性:与当前文本块主题的关联程度
- 必要性:缺失后是否影响理解
- 简洁性:补充内容是否精炼
C.2.3 文本块融合阶段
将精炼后的信息片段与当前文本块内容融合,生成既保持上下文连贯性又具备更高语义完整性的文本段落。融合策略包括:
- 前置补充:对需要背景知识的文本块,在开头补充必要上下文
- 插入补充:对术语定义类缺口,在首次出现位置插入解释
- 后置补充:对结果分析类文本块,在结尾补充相关结论
C.3 增强型摘要生成
ERNIE-3.5-128K模型采用两阶段策略生成增强型摘要:
- 全局补充摘要:利用文档级信息为当前文本块生成补充说明
- 局部核心摘要:提炼当前文本块自身的核心内容
- 融合优化:将两类摘要精细融合,形成既能体现局部重点又包含全局关联的增强型摘要
C.4 训练数据构建
通过LLM驱动的数据蒸馏管道,我们构建了高质量训练样本集:
- 为语义补全模块构建20,000条实例
- 为摘要生成模块构建20,000条实例
- 所有样本均包含人工标注的质量评分
这些数据为小语言模型(SLM)的全参数微调提供了关键指导信号,使我们的框架能够在高性能与轻量级部署之间取得平衡。
C.5 效果验证

图5:不同LLMs间原始文本块与改写文本块的PPL分布变化趋势
如图5所示,经过语义补全处理后(紫色线),各类模型的PPL值(困惑度)普遍低于原始文本块(橙色线),表明文本块的语义连贯性和可理解性得到显著提升。特别是在Qwen2-7B和Qwen2.5-7B模型上,PPL值降低了约30%,验证了语义补全策略的有效性。
理论基础与数学证明(选学)
在深入理解 PPL 分块方法之前,我们需要从信息论的基础开始,逐步构建完整的理论框架。本节将详细解释为什么要使用 PPL 来指导文本分块,以及为什么更长的文本块通常能带来更好的效果。
传统的文本分块方法(如固定长度分块、句子分块)往往忽略了语言的内在统计特性。它们可能在语义边界的中间进行切分,破坏了文本的连贯性。PPL 分块方法的核心思想是:利用语言模型对文本的"理解程度"来指导分块决策。
但这里有一个关键问题:为什么模型的"理解程度"可以用来指导分块?更长的上下文真的会让模型理解得更好吗? 这就需要我们从信息论的角度来寻找答案。
信息论基础:熵、交叉熵与困惑度 (PPL)
评估指标 (交叉熵 - H(P, Q)): 衡量概率分布 Q 逼近真实语言数据背后的经验分布 P 的效果,常用交叉熵:
- 物理意义: 想象你要用一种编码方式来压缩文本。如果你的编码方式(模型Q)很好地理解了真实语言的规律(分布P),那么压缩效果就会很好,需要的存储空间就少。交叉熵就是衡量这个"压缩效率"的指标——数值越小,说明你的模型越能准确预测下一个词应该是什么,压缩效果越好。
交叉熵的分解:
让我们用更通俗的语言来解释这个公式:
-
H(P) - 语言本身的复杂度:
- 通俗理解: 想象你在玩猜词游戏,H(P) 就是这个游戏本身的难度。比如中文比英文复杂,古文比现代文复杂,这个复杂度是语言本身决定的,不会因为你用什么模型而改变。
- 举个例子: 如果下一个词可能是"苹果"、"香蕉"、"橘子"中的任意一个,且概率相等,那么这个位置的不确定性就很高。如果99%的概率是"苹果",那么不确定性就很低。
- 关键点: 这个值是固定的,就像考试题目的难度一样,不管你是学霸还是学渣,题目难度都不会变。
-
D_{\text{\1}}(P || Q)散度 - 模型的"理解偏差":
- 通俗理解: 这个值衡量的是你的模型(比如ChatGPT)对语言的理解与真实语言规律之间的差距。
- 举个例子:
- 真实情况:在"我喜欢吃___"这个句子中,下一个词是"苹果"的概率是60%,是"汽车"的概率是0.1%
- 你的模型预测:下一个词是"苹果"的概率是40%,是"汽车"的概率是10%
- 那么D_{KL}(P || Q)就衡量了这种预测偏差有多大
- 关键点: 这个值可以通过训练来降低,就像学生通过学习可以提高成绩一样。
为什么这个分解很重要?
- 因为语言的复杂度H(P)是固定的,所以训练模型的目标就是让模型的理解偏差D_{KL}(P || Q)越来越小
- 当模型完美理解语言时,D_{KL}(P || Q) = 0,此时交叉熵H(P, Q) = H(P),达到理论最优值
- 这就像考试一样:题目难度固定,你只能通过学习来减少答错的题目,最终目标是考满分
困惑度 (PPL) - 更直观的评估指标:
- 定义: 困惑度定义为交叉熵的指数形式:
\text{PPL}(P, Q) = 2^{H(P, Q)}
- 直观解释: PPL 可以理解为模型在预测下一个词时,平均面临的等效选择数量。
- 例子: 如果 PPL = 100,意味着模型在预测时,感觉平均有 100 个词看起来"差不多可能"会是下一个词。值越小越好。
- PPL 与 KL 散度的关系:
\text{PPL}(P, Q) = 2^{H(P, Q)} = 2^{H(P) + D_{KL}(P || Q)}
- 因为 H(P) 是常数,不同 LLM 之间的 PPL 差异主要由它们对应的 D_{KL}(P || Q) 差异决定。KL 散度越大(模型越不准),PPL 越高。
- 文本中 PPL 异常高的点通常意味着模型在该位置非常"困惑",预测能力骤降。这往往发生在语义边界(如句子结束、段落结束、话题转折)。强行在这些高 PPL 点切分文本块,会破坏上下文完整性,导致后续处理(如 RAG 中的检索或问答)效果变差。因此,分块策略应避免在高 PPL 点切割,可以看上文中所提及的图表,正确切割点应该为谷底点,该点所对应的PPL值是特定区间中的极小值,代表模型对该位置"不困惑",预测能力比较高。
熵的近似:香农的 G_} 公式及其证明 (核心重点)
核心问题: 如何估计真实语言分布 P 的熵 H(P)?
让我们用一个简单的例子来理解这个问题:
问题的本质:
想象你要预测一篇文章的下一个字。如果你只看当前这个字,预测会很困难;如果你看前面2个字,预测会容易一些;如果你看前面10个字,预测会更准确。
香农的解决方案:
香农发现了一个规律:看的上下文越长,预测下一个字就越容易。他用数学公式把这个规律表达出来,这就是著名的G_{\text{\1}}公式。
通俗理解:
- G_{\text{\1}}就是"看前面K个字,预测下一个字的平均难度"
- K越大(看的上下文越长),G_{\text{\1}}越小(预测越容易)
- 这个规律适用于所有自然语言
为什么这很重要?
这告诉我们:在文本分块时,保留更长的上下文信息会让AI模型理解得更好。这就是为什么我们要用PPL(困惑度)来指导分块——它能帮我们找到既保持语义完整,又不破坏上下文连贯性的最佳分割点。
-
G_{\text{\1}} 的定义:
G_K = \frac{1}{K} \sum_{k=1}^{K} H(X_k | X_1, ..., X_{k-1}) \quad \text{(公式 6 的等价形式)}- 拿一段长度为
K的文本(比如K=100个字)。 - 对于这段文本中的每一个位置
k(第1个字、第2个字、...、第100个字),计算"知道前面所有字的情况下,预测这个位置的字有多难"。 - 把这100个"预测难度"加起来,再除以100,得到平均难度。
- 这个平均难度 G_K 就代表了:如果我们的记忆力只能记住前面K-1个字,那么预测下一个字的平均难度是多少(请记住这一句~)。
- 如果K=3,文本是"我喜欢"
- H(X_1):预测第1个字"我"的难度(没有任何提示)
- H(X_2|X_1):知道"我"的情况下,预测第2个字"喜"的难度
- H(X_3|X_1,X_2):知道"我喜"的情况下,预测第3个字"欢"的难度
- G_3 = \frac{1}{3}[H(X_1) + H(X_2|X_1) + H(X_3|X_1,X_2)]
- 拿一段长度为
下面我们将证明G_{K} \geq G_{K+1}这个公式,首先你需要知道定理一:
-
定理 1 (G_{\text{\1}} 是 H_{\text{\1}}(P) 的上界)
-
定理 2 (G_{\text{\1}} 单调递减且有下界)
下面我们来证明定理二:
* 证明思路 (核心): 关键在于证明 G_{K} \geq G_{K+1}。
写出 G_{K+1} 和 G_K:
将 G_{K+1} 拆分为前 K 项和第 K+1 项:
注意到 \sum_{k=1}^{K} H(X_k | X_1, ..., X_{k-1}) = KG_K 代入得:
由定理 1 的证明思路或直接由条件熵性质,我们知道:给模型提供更多的信息,预测就会更准确(或至少不会变差)。
具体来说:
- H(X_{K+1} | X_1, ..., X_K):知道前面K个词的情况下,预测第K+1个词的难度
- H(X_{K+1} | X_2, ..., X_K):知道前面K-1个词的情况下,预测第K+1个词的难度
显然,知道的信息越多(包括X_1),预测就越容易,所以:
进一步地,利用数学上的链式法则和熵的凹性质,可以证明一个更强的结论:
香农发现了一个重要规律:对于平稳的语言序列,预测的难度只取决于你能看到的上下文长度,而不取决于这段文字出现在文章的哪个位置。
具体来说:
- H(X_{K+1} | X_m, ..., X_K) 表示:已知第m个词到第K个词,预测第K+1个词的难度
- 上下文长度 = (K - m + 1) 个词
香农发现:只要上下文长度相同,预测难度就相同,不管这段上下文出现在文章开头、中间还是结尾。举个例子:看3个词预测第4个词的难度,在文章任何位置都是一样的;看5个词预测第6个词的难度,在文章任何位置也都是一样的。这样是不是更加清晰了。
因此,我们可以用一个简单的符号 h_l 来表示"看l个词预测下一个词的难度",其中 l 就是上下文长度。这样就把复杂的位置相关问题,简化成了只与长度相关的问题。
证明 G_K \geq G_{K+1}(单调递减性)
根据平稳性假设,我们可以用 h_l 表示"看 l 个词预测下一个词的难度":
其中:
- h_0 = H(X_1)(无上下文)
- h_1 = H(X_2|X_1)(上下文长度1)
- h_{K-1} = H(X_K|X_1, ..., X_{K-1})(上下文长度K-1)
- h_K = H(X_{K+1}|X_1, ..., X_K)(上下文长度K)
核心推导:
从定义可得:
移项得到:
关键引理: 由于条件熵的性质,更长的上下文总是降低预测不确定性,因此:
证明 G_K \geq h_K:
由于 h_0 \geq h_1 \geq ... \geq h_{K-1},它们的平均值必然大于等于最小项:
结合 h_{K-1} \geq h_K,得到:
结论:
因此 G_K \geq G_{K+1},证明了序列的单调递减性。
定理3(极限存在且等于熵率):
由单调有界数列必收敛准则,结合熵率定义可得此结论。
最后,综合以上的公式定理,我们可以知道G_{\text{\1}} 公式的重要性与意义,该公式通过计算有限长度 K 下的 G_K,来估计语言的熵率。G_K \downarrow 意味着预测能力 \uparrow:G_K 越小,预测越准确。 其次,上下文长度是关键 (K \uparrow \Rightarrow G_K \downarrow), 根据 定理 2 (G_1 \geq G_2 \geq ...) 表明,提供更长的历史上下文 (K 增大) 会显著降低预测下一个符号的平均不确定性 (G_K 减小)。
所以对于PPL来说:给 LLM 提供更长的上下文 (K 增大),其预测下一个词的条件交叉熵也会降低。进而,模型在整个长序列上的平均交叉熵 H(P, Q) 和困惑度 PPL 也会降低。
总结就是下面一句话:
Demo
下面将根据论文以及作者的开源项目复现:Meta-chunking
首先,打开modelscope的官网,注册账号,并登录。打开自己的notebook,GPU/CPU无所谓,使用下面的指令安装conda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh chmod +x Miniconda3-latest-Linux-x86_64.sh
Miniconda 允许用户在安装过程中指定安装路径。当您下载 Miniconda 安装包后,在运行安装命令时可以通过 -p 或 --prefix 参数来指定安装目录。我们要确保将其安装到Notebook的默认存储路径/mnt/workspace下,因为只有这个路径下的文件,才会被持久化保存。
具体来说,假如我们希望将其安装到/mnt/worksapce/miniconda3 目录下,可使用如下命令:
!bash Miniconda3-latest-Linux-x86_64.sh -b -p /mnt/workspace/miniconda3
-p指定的是您希望安装 Miniconda 的完整路径。
-b表示以批处理模式运行安装程序,不需要在安装过程提示交互。
初始化Conda
手工指定安装路径时,在安装后需要显式地调用conda binary 进行初始化:
/mnt/workspace/miniconda3/bin/conda init
初始化成功以后,关闭当前的terminal窗口,再重新打开。就可以正常使用conda命令了。
请注意,在您关闭ModelScope Notebook实例后,后续每次打开ModelScope Notebook的时候,都需要重新执行一次如上的初始化命令。
在你的notebook中,执行如下指令
git clone https://github.com/IAAR-Shanghai/Meta-Chunking.git cd Meta-Chunking conda create -n MetaChunking python=3.10 conda activate MetaChunking pip install -r requirements.txt # 这一步pip install非常慢,因为需要下载大量的包 cd example python app.py
如果报错,出现
OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like Qwen2-1.5B-Instruct is not the path to a directory containing a file named config.json. Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
请打开example/app.py文件,将
import gradio as gr from transformers import AutoModelForCausalLM, AutoTokenizer import torch import json import torch.nn.functional as F model_name_or_path= 'Qwen2-1.5B-Instruct' device_map = "auto" small_tokenizer = AutoTokenizer.from_pretrained(model_name_or_path,trust_remote_code=True) small_model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True,device_map=device_map) small_model.eval()
修改为
import gradio as gr from modelscope import AutoModelForCausalLM, AutoTokenizer # 使用ModelScope的Auto类 import torch import json import torch.nn.functional as F model_name_or_path = 'qwen/Qwen2-1.5B-Instruct' # ModelSpace路径 device_map = "auto" # 使用ModelScope的AutoTokenizer small_tokenizer = AutoTokenizer.from_pretrained( model_name_or_path, trust_remote_code=True ) # 使用ModelScope的AutoModel small_model = AutoModelForCausalLM.from_pretrained( model_name_or_path, trust_remote_code=True, device_map=device_map, torch_dtype=torch.bfloat16 # 添加数据类型以节省显存 ) small_model.eval()
注意:首次运行需要安装ModelSpace客户端
pip install modelscope
最后我们将看到如下的效果:
是否成功看到这个页面了呢?下面将讲解代码逻辑,看看作者是如何通过代码来实现PPL以及MSP的。