GRPO
文档摘要
GRPO This is the dev-log from SGLang team to support GRPO in TRL. Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO), enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO.
GRPO
This is the dev-log from SGLang team to support GRPO in TRL. Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO), enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO. This doc will first introduce how GRPO works and then show how we add SGLang as an alternative inference backend for TRL, specifically the GRPO Trainer, which also functions in the Open-R1 project.
How GRPO works
Compared with PPO, GRPO doesn't have the value/critic model to estimate total value. The algorithm computes the normalized reward for each output to derive advantages and updates the reward model to enhance training performance. In the context of GRPO, the term "update" refers specifically to the parameter updates of the policy model using gradients computed from the loss function. This means each training iteration adjusts the model's weights to maximize the advantage while maintaining proximity to a reference policy.
GRPO is composed of four steps:
- Generating completions
- Computing the advantage
- Estimating the KL divergence
- Computing the loss
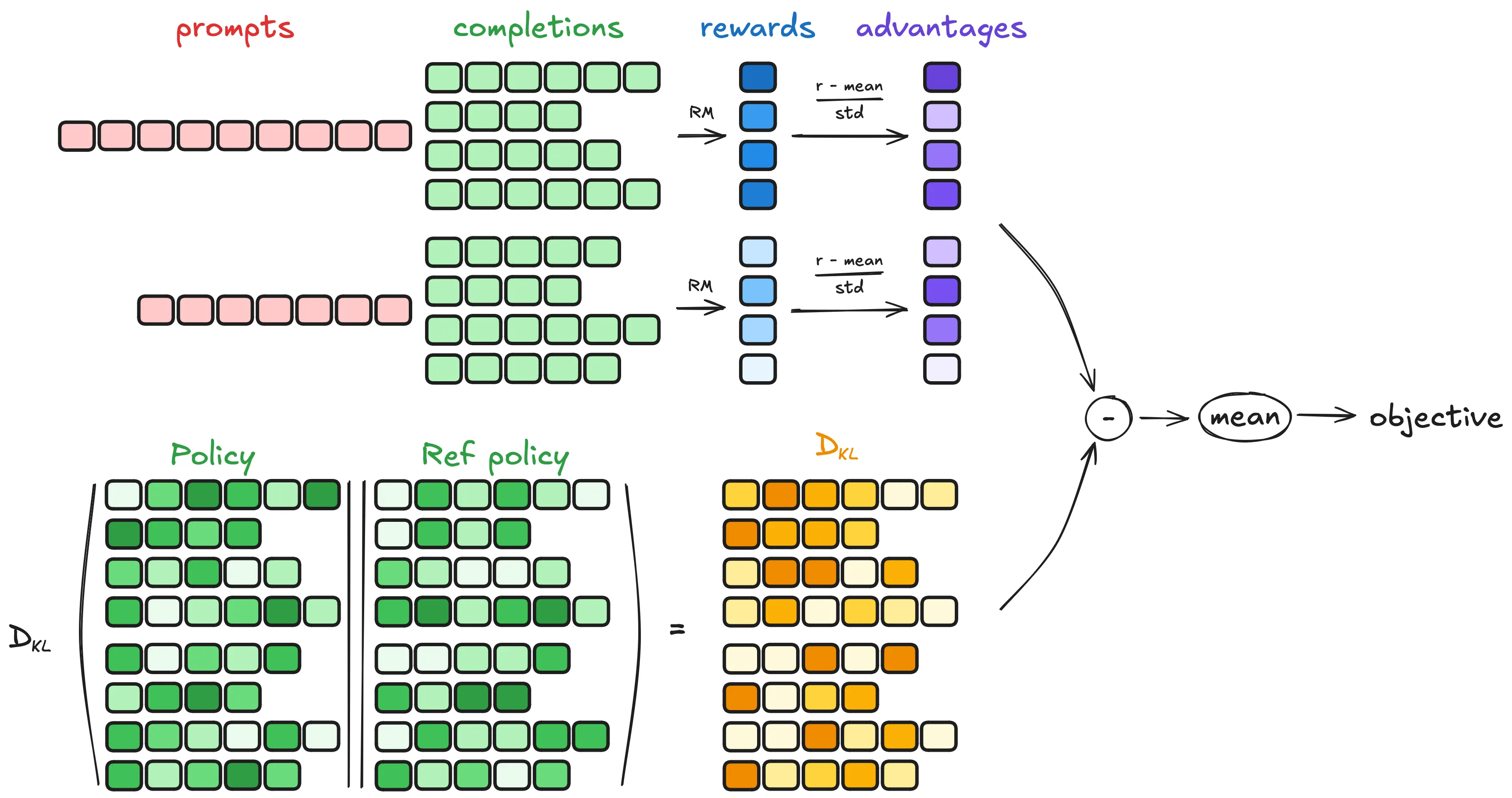
Generating completions
At each training step, we sample a batch of prompts and generate a set of G completions for each prompt (denoted as o_{i = 1, 2, ..., G}).
Computing the advantage
For each of the G sequences, we compute the reward using a reward model. To align with the comparative nature of reward models—typically trained on datasets of comparisons between outputs for the same question—the advantage is calculated to reflect these relative comparisons. It is normalized as follows:
This approach gives the method its name: Group Relative Policy Optimization (GRPO), since it uses the relative reward to compute the advantage.
Hugging Face uses the above equation to compute advantages. In GRPO paper, the author named it Outcome Supervision RL with GRPO. The author also found another method named Process Supervision RL with GRPO.
Supervision Reinforcement Learning (Supervision RL) combines traditional reinforcement learning with explicit guidance from labeled or structured data during training. It leverages direct supervision to enhance learning efficiency and model performance.
Process Supervision RL specifically uses intermediate step-wise rewards rather than evaluating only final outcomes. It provides detailed, step-by-step feedback to the model, thus facilitating fine-grained optimization of policy decisions at every generation step.
We can also leverage the information in each step. Formally, given the question q and G sampled outputs {o_1, o_2, … , o_G}, a process reward model is R = {{r_1^{index(1)}, …, r_1^{index(K_1)}}, … , {r_G^{index(1)}, …, r_G^{index(K_G)}}}, where index(K_j) is the end token index of K_j-th completion.
Normalize each reward:
The advantages of each output in each step:
Estimating the KL divergence
KL divergence is estimated using the approximator, which is defined as follows:
Computing the loss
The objective is to maximize the advantage while ensuring that the model remains close to the reference policy. Consequently, the loss is defined as follows:
- the first term represents the scaled advantage
- the second term penalizes deviations from the reference policy through KL divergence.
In the original paper, this formulation is generalized to account for multiple updates after each generation by leveraging the clipped surrogate objective:
where clip(⋅,1−\epsilon,1+\epsilon) ensures that updates stay close to the reference policy by keeping the policy ratio between 1−\epsilon and 1+\epsilon. However, since TRL follows the original paper in performing only one update per generation, we can simplify the loss to the first form.
Customized GRPO
To support GRPO in TRL, we need to customize the GRPO Trainer. First, we can take a look at how inference engines are used in the GRPO Trainer.
Conditional Setup and Import
The code conditionally imports vLLM modules and uses a configuration flag (args.use_vllm) to enable/disable vLLM's generation engine. This is controlled through the self.use_vllm flag in the trainer's constructor.
Initialization and Dedicated GPU Selection
- Dedicated Device Assignment
When use_vllm is True, the trainer (but only on the main process) determines a dedicated GPU for generation. For example:
if self.accelerator.is_main_process: vllm_device = self.args.vllm_device if vllm_device == "auto": if torch.cuda.device_count() == 1: vllm_device = "cuda:0" else: vllm_device = f"cuda:{self.accelerator.num_processes}"
This logic assigns one GPU (or a GPU outside of those used for training) exclusively for the vLLM generation task, thereby detaching generation work from the training GPUs.
- Patching for Compatibility
Since vLLM isn't inherently designed to work with the distributed setup from accelerate, the code applies two patches:
world_size_patch = patch("torch.distributed.get_world_size", return_value=1) profiling_patch = patch("vllm.worker.worker.Worker._assert_memory_footprint_increased_during_profiling", return_value=None) with world_size_patch, profiling_patch: self.llm = LLM( model=model.name_or_path, device=vllm_device, gpu_memory_utilization=self.args.vllm_gpu_memory_utilization, dtype=self.args.vllm_dtype, enable_prefix_caching=True, max_model_len=self.args.vllm_max_model_len, ) self.sampling_params = SamplingParams( temperature=args.temperature, max_tokens=self.max_completion_length, )
These patches make sure that:
- The vLLM engine sees a "world size" of 1 (since it's running on a dedicated device).
- Certain profiling checks that aren't applicable in this setting are bypassed.
- Synchronization
After setting up vLLM, the main process calls self.accelerator.wait_for_everyone() to ensure all processes are synchronized.When using vLLM, the main process is responsible for loading the model weights. This can cause process desynchronization and seems to lead to DeepSpeed hanging during initialization. To prevent this, this function ensures all processes are synchronized after the dedicated generation device is set up.
Using vLLM for Generation During Training
- Moving Weights to vLLM
Before generating completions, the trainer calls _move_model_to_vllm(self). This method extracts the model's state (merging adapters if needed) and loads the weights into the vLLM engine's GPU worker:
if self.accelerator.is_main_process: llm_model = self.llm.llm_engine.model_executor.driver_worker.model_runner.model llm_model.load_weights(state_dict.items())
This transfer is key because vLLM is responsible for generating text, and its internal model must reflect the latest training weights.
The method llm_model.load_weights(state_dict.items()) is initially used to load model weights into vLLM during setup. Subsequent updates during training are also done by updating vLLM weights from disk.
- Generation Workflow
In the _prepare_inputs method, when using vLLM:
- The main process gathers all prompt texts across GPUs.
- It then generates completions with
outputs = self.llm.generate(all_prompts_text, sampling_params=self.sampling_params, use_tqdm=False). - The completions are extracted, and the results are broadcast to all processes so that every GPU gets its corresponding slice of generated text.
- Detach Generation from Training
By detaching the generation task to a dedicated GPU placement group, the training GPUs remain fully occupied with gradient computations.
Support SGLang in GRPO Trainer
Here, we support SGLang as an inference backend alongside other inference engines in the GRPOTrainer. Unlike other inference engines—which run as an in-process engine using dedicated classes (e.g. LLM, SamplingParams) and requires patching of distributed methods—SGLang is deployed as a standalone server with HTTP endpoints (compatible with OpenAI's APIs). As a result, our integration leverages HTTP requests to manage weight updates and generate completions.
To substitute other inference engines with SGLang, we must account for the differences in API and internal architecture. The following steps outline the necessary modifications:
-
Checkpoint-based Updates
-
Update the
GRPOConfigby adding acheckpoint_pathparameter. -
Write model checkpoints at regular intervals.
-
Use the existing
/update_weights_from_diskendpoint provided by the SGLang server.
-
This approach avoids modifying SGLang’s internal initialization routines and leverages its existing, stable checkpoint-loading capabilities.
Import and Availability Check
Instead of importing in-process engine classes for SGLang, we introduce a configuration flag (use_sglang) in our arguments (e.g., in GRPOConfig). This flag signals that generation should be offloaded to a SGLang server. Since SGLang is accessed via HTTP calls, there's no need to import objects like SGLangEngine. Instead, we ensure that the SGLang server is reachable (or launch it within our code) and then use helper utilities (from sglang.utils) to manage the server lifecycle.
Initialization on a Dedicated GPU
- Server Launch and Device Assignment
Rather than creating an in-process generation engine, we launch the SGLang server as an external process on a dedicated GPU. For example, in the trainer's __init__, we added:
if self.args.use_sglang: # Assign a dedicated GPU for the SGLang server (e.g., "cuda:1") sglang_gpu_id = self.args.sglang_device.split(':')[-1] sglang_command = ( f"CUDA_VISIBLE_DEVICES={sglang_gpu_id} python -m sglang.launch_server " f"--model-path {model_id} --host 0.0.0.0" ) from sglang.utils import launch_server_cmd, wait_for_server self.server_process, port = launch_server_cmd(sglang_command) wait_for_server(f"http://localhost:{port}") self.sglang_server_url = f"http://localhost:{port}"
This command dedicates one GPU exclusively for the SGLang server, which will handle all generation requests.
- Process Synchronization
After launching the server, we call:
self.accelerator.wait_for_everyone()
to ensure that all distributed processes are synchronized before proceeding.
Generation and Weight Synchronization
- Weight Synchronization
SGLang offers several weight update strategies, each suited to a different deployment setting:
update_weights_from_distributed uses NCCL (NVIDIA Collective Communications Library) for high-performance GPU-to-GPU communication. It's ideal for fully distributed training setups across multiple nodes.
update_weights_from_tensor, in contrast, is designed for intra-node, cross-process updates. It’s particularly useful for inference servers like VerlEngine using HybridEngine. This method passes tensors via shared memory between CPU or GPU processes, and the receiving process directly copies them into model parameters. It does not rely on NCCL or HTTP. Instead, it uses pointer sharing and explicit copy operations. As a result, parameters are never transmitted over HTTP during updates. When migrating from veRL Engine to veRL Server, only lightweight metadata needs to be transferred. This minor overhead is a reasonable tradeoff for the greater flexibility that a server-based architecture provides.
In vLLM, update weights are done in-process via a helper like _move_model_to_vllm(). For SGLang, weight updates occur externally through its HTTP API. For SGLang, weight updates occur externally. We implement a helper function _update_sglang_weights() that calls SGLang's /update_weights_from_tensor API to update the server's model state:
- About SGLang update weights
The _update_sglang_weights function updates the model's weights on the SGLang server by serializing the model's parameters using MultiprocessingSerializer. It then sends the serialized tensors to the server via an HTTP POST request to the /update_weights_from_tensor endpoint. This method directly transfers tensors between processes and can optionally flush the cache after the update. The approach avoids disk-based checkpoints and relies on tensor communication for more efficient weight synchronization.
This function:
- Serializes model parameters using MultiprocessingSerializer.
- Sends an HTTP POST request to SGLang's /update_weights_from_tensor API.
- Flushes the cache after the update.
def _update_sglang_weights(self): """ Update the model weights on the SGLang server via its tensor-based update API. This function only be called in main_process. """ payload = { "serialized_named_tensors": [ MultiprocessingSerializer.serialize(list(self.model.named_parameters()), output_str=True) ], "flush_cache": True, # flush cache after update weights } try: response = requests.post( f"{self.sglang_server_url}/update_weights_from_tensor", json=payload, timeout=60, ) except requests.RequestException as e: raise RuntimeError(f"Weight update request failed: {e}") res_json = response.json() if not res_json.get("success", False): raise RuntimeError( f"Failed to update weights on SGLang server: {res_json.get('message', 'No message provided')}" )
- Generation Call
In the _prepare_inputs() method, we replace the in-process generation call with an HTTP request to SGLang's /generate endpoint:
if self.use_sglang: # Update weights if the training step has advanced. if self.state.global_step != self._last_loaded_step: self._update_sglang_weights() self._last_loaded_step = self.state.global_step # Gather all prompt texts from all processes. all_prompts_text = gather_object(prompts_text) if self.accelerator.is_main_process: import requests payload = { "text": all_prompts_text, "sampling_params": self.sglang_sampling_params, } response = requests.post(f"{self.sglang_server_url}/generate", json=payload) generated_texts = response.json().get("text", []) completion_ids = [self.processing_class.encode(text) for text in generated_texts] else: completion_ids = [None] * len(all_prompts_text) # Broadcast and slice the generated completions. completion_ids = broadcast_object_list(completion_ids, from_process=0) process_slice = slice( self.accelerator.process_index * len(prompts), (self.accelerator.process_index + 1) * len(prompts), ) completion_ids = completion_ids[process_slice] completion_ids = [torch.tensor(ids, device=device) for ids in completion_ids] completion_ids = pad(completion_ids, padding_value=self.processing_class.pad_token_id) prompt_completion_ids = torch.cat([prompt_ids, completion_ids], dim=1)
- Broadcasting Results
We then broadcast the generated completions from the main process across all processes using broadcast_object_list() and slice the results according to each process's index.
API and Integration Adjustments
- Parameter Differences
Since SGLang's API mimics OpenAI's endpoints, we pass sampling parameters as a JSON payload (e.g., temperature, max_new_tokens) to the /generate endpoint.
- Error Handling and Device Checks
We update error messages and checks for SGLang without needing to patch distributed functions—since SGLang runs as an external service, it operates independently of the training environment.
Overall Code Changes Recap
- Backend Flags
Added use_sglang (and retained use_vllm) in configuration to let users choose the inference backend.
- Server Initialization
In the __init__ method, if use_sglang is True, launch the SGLang server on a dedicated GPU and set self.sglang_server_url.
- Weight Updates
Implemented a robust _update_sglang_weights() function that ensures the SGLang server updates its model weights from the latest checkpoint, with error handling and cache flushing.
- Generation Branch
Modified _prepare_inputs() to branch based on the selected backend:
- SGLang Branch
Uses HTTP calls to SGLang's /generate endpoint, then converts returned texts to token IDs, broadcasts, and postprocesses.
Testing and Next Steps
- Test the SGLang Server
Ensure that the SGLang server launches correctly on the dedicated GPU and that its /generate and /update_weights_from_disk endpoints respond as expected.
- Integration Test
Run the modified GRPOTrainer on a small dataset and verify that:
- Weights are updated on the SGLang server when the training step advances.
- Generation results are correctly broadcast and postprocessed.
- The overall training loop runs without errors.
Summary
To support SGLang in TRL, we:
- Introduce a configuration flag (e.g. use_sglang) and assign a dedicated GPU for the SGLang server.
- Launch the SGLang server externally using a command (with appropriate GPU assignment) and wait for it to initialize.
- Replace the in-process generation call in _prepare_inputs() with an HTTP POST to the SGLang /generate endpoint.
- Implement a helper to update model weights on the SGLang server via its /update_weights_from_disk API.
- Adjust parameter names, error handling, and synchronization logic to match SGLang's external server API.
References
- SGLang Documentation – https://docs.sglang.ai/backend
- HuggingFace GRPO Trainer Documentation - https://huggingface.co/docs/trl/main/en/grpo_trainer
- Speeding Up Training - https://huggingface.co/docs/trl/main/en/speeding_up_training?vllm+examples=GRPO#vllm-for-fast-generation-in-online-methods
- GRPO Trainer in TRL - https://github.com/huggingface/trl/blob/main/trl/trainer/grpo_trainer.py