slimeRollout系统详解
文档摘要
slime Rollout 系统详解 概述 模块是 slime 框架中的核心组件,负责处理强化学习训练过程中的样本生成、过滤和评估。该模块提供了一个完整的 pipeline,从数据源获取提示,生成响应,应用奖励模型,并通过过滤器选择高质量样本用于训练。 系统架构图解析 slime整体工作流程 训练循环流程 SGLang 分布式生成 模块结构 核心组件详解 SGLang Rollout ( ) 这是主要的样本生成引擎,基于 SGLang 实现高效的异步文本生成。 关键特性: 异步生成: 使用 实现并发样本生成 状态管理: 单例类管理全局生成状态 可中断生成: 支持在生成过程中中断和恢复 批量处理: 支持批量生成和奖励模型评估 核心类和函数: 是全局生成状态管理器。
slime Rollout 系统详解
概述
slime/rollout 模块是 slime 框架中的核心组件,负责处理强化学习训练过程中的样本生成、过滤和评估。该模块提供了一个完整的 pipeline,从数据源获取提示,生成响应,应用奖励模型,并通过过滤器选择高质量样本用于训练。
系统架构图解析
训练循环流程
train.py → ray/rollout.py → RolloutManager → RolloutController → 数据生成 → 模型训练
SGLang 分布式生成
Router → SGLang Server 1/2 → TP0/TP1/TP2/TP3 → 样本生成 → 奖励评估
模块结构
slime/rollout/ ├── __init__.py ├── sglang_rollout.py # 基于 SGLang 的异步样本生成 ├── sft_rollout.py # SFT 训练样本处理 ├── filter_hub/ # 样本过滤器 │ ├── dynamic_sampling_filters.py │ └── over_sampling_filters.py └── rm_hub/ # 奖励模型集合 ├── __init__.py ├── deepscaler.py ├── f1.py ├── math_utils.py └── math_dapo_utils.py
核心组件详解
SGLang Rollout (sglang_rollout.py)
这是主要的样本生成引擎,基于 SGLang 实现高效的异步文本生成。
关键特性:
- 异步生成: 使用
asyncio实现并发样本生成 - 状态管理:
GenerateState单例类管理全局生成状态 - 可中断生成: 支持在生成过程中中断和恢复
- 批量处理: 支持批量生成和奖励模型评估
核心类和函数:
GenerateState 是全局生成状态管理器。
- 管理
Group: List[Sample]的生成状态 - 控制
generate_and_rm_group任务的提交 - 维护
semaphore,sampling_params,args, etc.
GenerateState 类
class GenerateState(metaclass=SingletonMeta): def __init__(self, args): self.args = args self.tokenizer = AutoTokenizer.from_pretrained(args.hf_checkpoint, trust_remote_code=True) self.semaphore = asyncio.Semaphore(args.sglang_server_concurrency * args.rollout_num_gpus // args.rollout_num_gpus_per_engine) self.sampling_params = dict( temperature=args.rollout_temperature, top_p=args.rollout_top_p, top_k=args.rollout_top_k, max_new_tokens=args.rollout_max_response_len, stop=args.rollout_stop, stop_token_ids=args.rollout_stop_token_ids, skip_special_tokens=args.rollout_skip_special_tokens, no_stop_trim=True, spaces_between_special_tokens=False, ) self.reset() def reset(self): self.remaining_batch_size = 0 self.pendings = set() self.aborted = False def submit_generate_tasks(self, samples: list[list[Sample]]): for group in samples: self.pendings.add( asyncio.create_task( generate_and_rm_group( self.args, group, sampling_params=self.sampling_params.copy(), evaluation=False, ) ) ) self.remaining_batch_size += len(samples)
generate_rollout_async 这是异步样本生成的主函数。
workflow:
- Step1. 定义相关的filters,e.g. dynamic_filter&over_sampling_filter
- 定义 target_data_size=
- 如果over_sampling_filter未开启,则target_data_size=rollout_batch_size
- 如果over_sampling_filter开启,则target_data_size=over_sampling_batch_size
- Step2. 确定data size,从dataset中取出over_sampling_batch_size的samples
- Step3. 等到Step2的batch中第一个group结束,对完成的部分进行采样 (同时进行dynmaic filter)
- Step4. 如果整体采样数量不够 (已经获得的有效group数量+剩余正在rollout的group数量<target_data_size),重复Step2&3
- Step5. Abort还在pending的job,如果是partial rollout则回收至buffer
- Step6. 如果使用了over_sampling_filter,则进行filter
generate_rollout_async 函数
async def generate_rollout_async(args, rollout_id: int, data_source) -> list[list[Sample]]: """An example to implement the generate_rollout function for an rule based rm rollout generation. Args: args: the whole args rollout_id: int, the id of the rollout, used for deterministic data generation data_source: the data source to fetch Returns: list[list[Sample]]: a list of samples generated by the rollout, the length of the list is exactly the same as the `rollout_batch_size` """ assert args.rollout_global_dataset state = GenerateState(args) # instantiate data filters dynamic_filter = ( load_function(args.dynamic_sampling_filter_path) if args.dynamic_sampling_filter_path is not None else None ) over_sampling_filter = ( load_function(args.over_sampling_filter_path) if args.over_sampling_filter_path is not None else None ) # target_data_size is the total number of valid samples to get target_data_size = args.over_sampling_batch_size if over_sampling_filter is not None else args.rollout_batch_size data = [] do_print = True pbar = tqdm(total=target_data_size * args.n_samples_per_prompt, desc="Rollout generation") while len(data) < target_data_size: while state.remaining_batch_size < target_data_size: # get samples from the buffer and submit the generation requests. samples = data_source(args.over_sampling_batch_size) state.submit_generate_tasks(samples) # wait for the generation to finish done, state.pendings = await asyncio.wait(state.pendings, return_when=asyncio.FIRST_COMPLETED) for task in done: group: list[Sample] = task.result() if do_print: print( f"First rollout sample: {[group[0].prompt + group[0].response]}, label: {group[0].label}, reward: {group[0].reward}", flush=True, ) do_print = False assert len(group) == args.n_samples_per_prompt if dynamic_filter is not None and not dynamic_filter(args, group): state.remaining_batch_size -= 1 continue # add the samples to the data # NOTE: here we have not stored all the unused samples back to the data buffer. if len(data) < target_data_size: data.append(group) pbar.update(args.n_samples_per_prompt) pbar.close() print( f"Finish rollout: {[data[-1][0].prompt + data[-1][0].response]}, label: {data[-1][0].label}, reward: {data[-1][0].reward}", flush=True, ) # there are still some unfinished requests, abort them aborted_samples = await abort(args, rollout_id) if over_sampling_filter is not None: data = over_sampling_filter(args, data)[: args.rollout_batch_size] assert len(data) == args.rollout_batch_size, f"Got {len(data)} samples, expected {args.rollout_batch_size}" data = sorted(data, key=lambda group: group[0].index) # reset the global state to prevent effects on the next rollout or eval. state.reset() return data, aborted_samples
generate_and_rm_group对样本组进行生成和奖励模型评估.
- 处理
Group: List[Sample]中的每个样本 - 对每sample执行
generate_and_rm操作
generate_and_rm_group 函数
async def generate_and_rm_group(args, group: list[Sample], sampling_params: dict, evaluation=False) -> list[Sample]: """对样本组进行生成和奖励模型评估""" state = GenerateState(args) if state.aborted: return group # 并发生成所有样本 group = await asyncio.gather( *[generate_and_rm(args, sample, sampling_params.copy(), evaluation=evaluation) for sample in group] ) # 对于需要整个组的奖励模型,在这里进行评估 if not state.aborted and args.group_rm: rewards = await batched_async_rm(args, group) for sample, reward in zip(group, rewards): sample.reward = reward return group
generate_and_rm单个样本的生成和奖励模型评估。
- 处理
sample1,sample2等单个样本 - 执行生成和奖励评估
generate_and_rm 函数
async def generate_and_rm(args, sample: Sample, sampling_params: dict, evaluation=False) -> Sample: """单个样本的生成和奖励模型评估""" # 对于已有响应的样本,检查是否完成 if sample.status == Sample.Status.COMPLETED or sample.status == Sample.Status.TRUNCATED: if not args.group_rm: assert sample.reward is not None return sample state = GenerateState(args) # 生成 async with state.semaphore: if state.aborted: sample.status = Sample.Status.ABORTED return sample if args.custom_generate_function_path is not None: custom_generate_func = load_function(args.custom_generate_function_path) sample = await custom_generate_func(args, sample, sampling_params) else: sample = await generate(args, sample, sampling_params) if sample.status == Sample.Status.ABORTED: return sample # 对于需要整个组的奖励模型,不在这里评估 if args.group_rm: return sample # 评估奖励 sample.reward = await async_rm(args, sample) return sample
abort 中断生成过程,收集部分完成的样本。
- post abort_all 到sglang_router
- 如果partial_rollout,将
aborted_samples放入data buffer
abort 函数
async def abort(args, rollout_id: int): """中断生成过程""" aborted_samples = [] state = GenerateState(args) state.aborted = True # 中断所有请求 response = await get(f"http://{args.sglang_router_ip}:{args.sglang_router_port}/list_workers") for url in response["urls"]: await post(f"{url}/abort_request", {"abort_all": True}) # 收集部分完成的样本 while state.pendings: done, state.pendings = await asyncio.wait(state.pendings, return_when=asyncio.FIRST_COMPLETED) for task in done: group = task.result() aborted_samples.append(group) return aborted_samples
生成流程详解:
- 初始化: 设置生成参数和并发控制
- 数据获取: 从数据源获取提示样本
- 任务提交: 将生成任务提交到 SGLang 服务器
- 动态过滤: 应用动态采样过滤器
- 过采样过滤: 应用过采样过滤器选择最终样本
- 清理: 中断未完成的任务并收集结果
filter逻辑
系统架构图中,rollout部分画的是没有开启filter的逻辑,如果enable了filter,具体的rollout flow为:
- 系统首先启动 over_sampling_batch_size=6 个并发的 generate_and_rm_group 任务。target_data_size=over_sampling_batch_size=6
- 当某个group完成时,会通过Dynamic filter检查奖励标准差(Std=0 的组被丢弃)。
- 由于需要 target_data_size=6 个有效group,在检测到已经获得的有效group数量+正在rollout的group数量<target_data_size时,会提交一个新的batch来获得足够的样本。
- 最终收集够 target_data_size=6 个有效group后,通过 finish & abort 操作中断未完成的任务,然后应用Over Sampling filter从 6 个完成的样本组中按奖励标准差排序,选出质量最高的 4 个作为最终的 Completed Samples。
如下: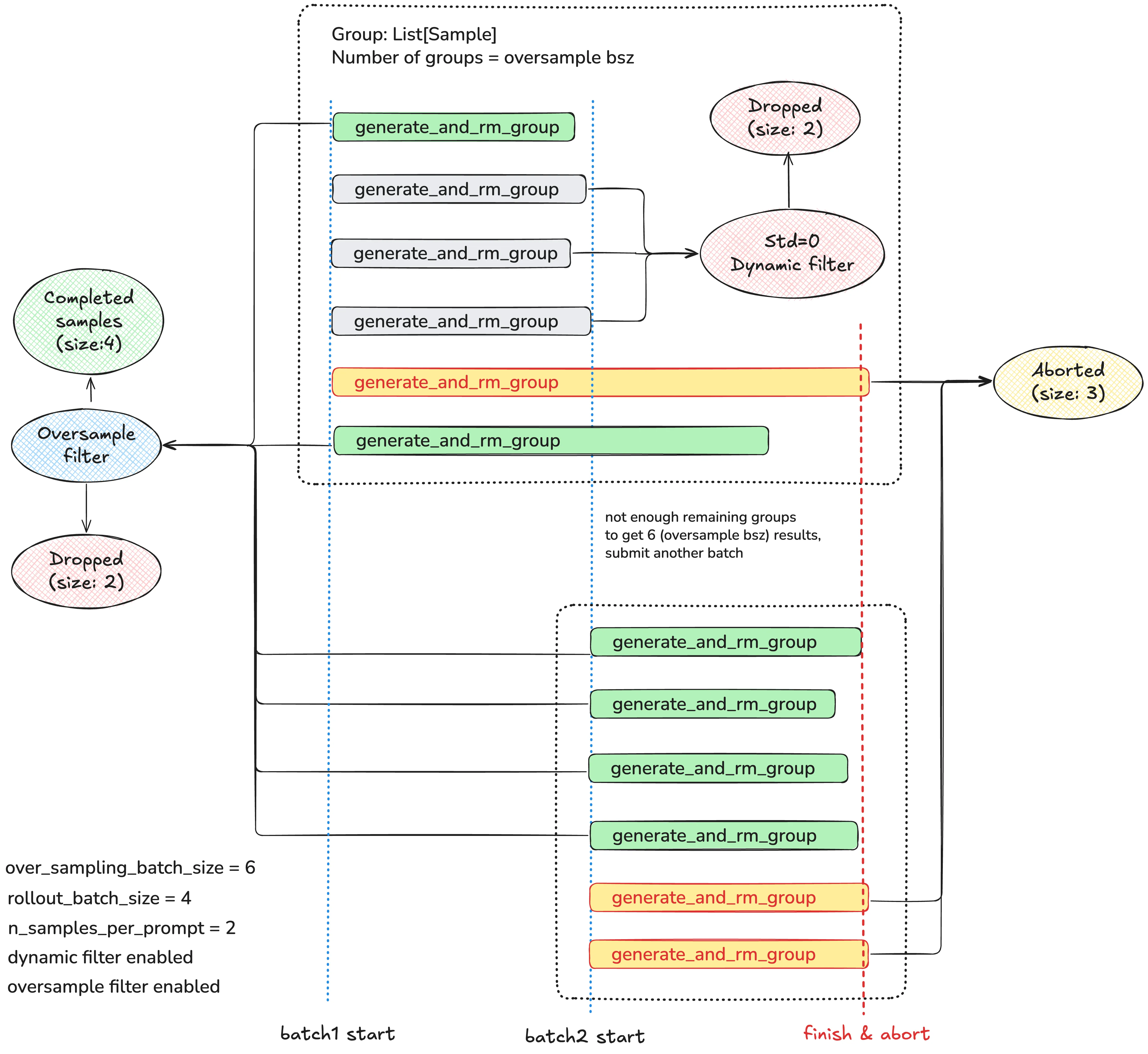
SFT Rollout (sft_rollout.py)
专门用于监督微调(SFT)的样本处理模块。
核心功能:
- 分词处理: 使用 tokenizer 对样本进行分词
- 损失掩码生成: 生成用于训练的损失掩码
- 响应长度计算: 计算响应部分的长度
实现示例:
def generate_rollout(args, rollout_id, data_buffer, evaluation=False): # 获取样本 samples = data_buffer.get_samples(args.rollout_batch_size) for sample in samples: # 生成损失掩码 token_ids, loss_mask = MASK_GENERATOR.get_loss_mask(messages) response_length = MASK_GENERATOR.get_response_lengths([loss_mask])[0] # 设置样本属性 sample.tokens = token_ids sample.response_length = response_length sample.reward = 0 sample.loss_mask = loss_mask[-response_length:] return samples
过滤器系统 (filter_hub/)
过滤器系统在架构图中体现为动态过滤和过采样过滤机制,用于确保样本质量。
动态采样过滤器 (dynamic_sampling_filters.py)
动态采样过滤器详解
功能: 过滤掉奖励标准差为0的样本组(删除全0/1样本组)
def check_reward_nonzero_std(args, samples: list[Sample], **kwargs): """ 检查样本组的奖励标准差是否大于0 Args: args: 全局参数 samples: 样本列表 **kwargs: 额外参数 Returns: bool: 如果标准差大于0返回True,否则返回False """ rewards = [sample.get_reward_value(args) for sample in samples] return torch.tensor(rewards, dtype=torch.float).std() > 0.0
作用:
- 确保选择的样本组具有足够的多样性
- 避免选择所有样本奖励都相同的组
- 提高训练数据的质量
在系统架构图中的角色:
- 在生成过程中实时应用
- 过滤掉不合格的样本组
- 确保样本组具有奖励多样性
过采样过滤器 (over_sampling_filters.py)
过采样过滤器详解
功能: 按奖励标准差对样本组进行排序,优先选择方差大的样本组
def sort_by_reward_std(args, samples: list[list[Sample]], **kwargs) -> list[list[Sample]]: """ 按奖励标准差对样本组进行排序 Args: args: 全局参数 samples: 样本组列表 **kwargs: 额外参数 Returns: list[list[Sample]]: 按标准差降序排序的样本组 """ samples_with_std = [] for group in samples: rewards = [item.reward for item in group] std = torch.tensor(rewards, dtype=torch.float).std() samples_with_std.append((group, std)) # 按标准差降序排序(python sort是稳定的) samples_with_std.sort(key=lambda x: x[1], reverse=True) return [item[0] for item in samples_with_std]
作用:
- 优先选择奖励分布更加多样化的样本组
- 这些样本组通常包含更有价值的训练信号
- 提高模型学习的效率
在系统架构图中的角色:
- 在所有候选样本生成完成后应用
- 从候选样本中选择最优的子集
- 确保最终样本具有高质量的训练信号
奖励模型集合 (rm_hub/)
奖励模型集合在架构图中体现为对生成样本的评估机制,支持多种评估方式。
支持的奖励模型类型:
- DeepScaler: 基于规则的奖励模型
- DAPO: 数学问题评估模型
- Math: 数学答案验证模型
- F1: F1分数计算模型
- Remote RM: 远程奖励模型接口
核心函数:
async_rm 函数详解
根据配置的奖励模型类型评估单个样本。
async def async_rm(args, sample: Sample, **kwargs): """ 异步评估单个样本的奖励 Args: args: 全局参数 sample: 待评估的样本 **kwargs: 额外参数 Returns: float: 奖励值 """ if args.custom_rm_path is not None: rm_function = load_function(args.custom_rm_path) return await rm_function(args, sample, **kwargs) rm_type = args.rm_type response = sample.response label = sample.label # 处理特殊前缀 if rm_type.startswith("boxed_"): response = extract_boxed_answer(response) or "" rm_type = rm_type[len("boxed_"):] # 根据类型选择奖励模型 if rm_type == "remote_rm": return await remote_rm(args, sample) elif rm_type == "deepscaler": return get_deepscaler_rule_based_reward(response, label) elif rm_type == "dapo": return compute_score_dapo(response, label) elif rm_type == "math": return 1 if grade_answer_verl(response, label) else 0 elif rm_type == "f1": return f1_score(response, label)[0] else: raise NotImplementedError(f"Rule-based RM for {rm_type} is not implemented.")
在系统架构图中的角色:
- 在
generate_and_rm函数中被调用 - 评估单个样本的奖励值
- 支持多种评估策略
batched_async_rm 函数详解
批量评估多个样本的奖励,提高评估效率。
async def batched_async_rm(args, samples: list[Sample], **kwargs) -> list[Union[int, float]]: """ 批量异步评估多个样本的奖励 Args: args: 全局参数 samples: 样本列表 **kwargs: 额外参数 Returns: list[Union[int, float]]: 奖励值列表 """ if args.custom_rm_path is not None: rm_function = load_function(args.custom_rm_path) return await rm_function(args, samples, **kwargs) tasks = [async_rm(args, sample, **kwargs) for sample in samples] rewards = await asyncio.gather(*tasks) return rewards
在系统架构图中的角色:
- 在
generate_and_rm_group函数中被调用 - 支持组级奖励模型评估
- 提高批量评估效率
工作流程详解
完整系统工作流程
根据架构图,整个系统的工作流程如下:
训练循环 (train.py) ↓ RolloutManager (ray/rollout.py) ↓ RolloutController (ray/buffer.py) ↓ RolloutDataSourceWithBuffer (ray/rollout_data_source.py) ↓ generate_rollout (rollout/sglang_rollout.py) ↓ SGLang Router → SGLang Servers → TP Ranks ↓ 样本生成 → 奖励评估 → 过滤选择 ↓ completed_samples → 训练循环
训练循环详细流程
训练循环步骤详解
-
rollout samples:
- 调用
RolloutManager.async_generate(rollout_id) - 触发
RolloutController.generate(rollout_id) - 执行样本生成流程
- 调用
-
offload sglang:
- 调用
RolloutManager.async_offload() - 释放 SGLang 相关内存,为训练腾出空间
- 调用
-
model training:
- 使用生成的样本进行模型训练
- 更新模型参数
-
offload megatron:
- 释放 Megatron 相关内存
- 为 SGLang 恢复做准备
-
resume sglang weight:
- 调用
RolloutManager.async_onload() - 恢复 SGLang 权重
- 调用
-
weight sync:
- 同步模型权重
- 确保各组件状态一致
-
resume sglang kv cache:
- 恢复 SGLang KV 缓存
- 为下一轮生成做准备
-
回到 rollout samples:
- 开始下一轮样本生成
- 形成完整的训练循环
SGLang 分布式生成流程
SGLang 生成流程详解
-
Router 路由:
- 中央 Router 接收生成请求
- 根据负载均衡策略分发到不同的 SGLang Server
-
SGLang Server 处理:
- 每个 SGLang Server 处理分配到的请求
- 支持多个 Server 并行处理
-
Tensor Parallelism (TP) 并行:
- 每个 Server 内部使用 TP0-TP3 进行张量并行
- 提高大模型的推理效率
-
样本生成和评估:
- 执行
generate_and_rm_group操作 - 生成样本并进行奖励评估
- 支持 "start" 和 "abort" 控制点
- 执行
-
结果返回:
- 完成的样本返回为
completed_samples - 中断的样本返回为
aborted_samples
- 完成的样本返回为
数据流和缓冲机制
数据流详解
-
数据获取流程:
RolloutDataSourceWithBuffer.get_samples() ├── 首先尝试从 buffer 获取样本 ├── 如果 buffer 不够,调用父类 get_samples() └── 返回足够的样本组 -
样本生成流程:
generate_rollout_async() ├── 提交生成任务到 SGLang ├── 等待生成完成 ├── 应用动态过滤器 └── 应用过采样过滤器 -
结果处理流程:
生成结果 ├── completed_samples → 返回给训练循环 └── aborted_samples → 添加到 RolloutDataSourceWithBuffer.buffer -
缓冲管理:
RolloutDataSourceWithBuffer ├── buffer: 存储中断的样本 ├── add_samples(): 添加样本到缓冲区 └── get_samples(): 从缓冲区获取样本
配置参数详解
关键配置参数
| 参数 | 说明 | 架构图中的体现 | 影响 |
|---|---|---|---|
rollout_batch_size |
每批次生成的样本数量 | 最终返回的样本数量 | 控制生成效率 |
over_sampling_batch_size |
过采样批次大小 | 生成过程中的样本数量 | 控制样本选择范围 |
n_samples_per_prompt |
每个提示生成的样本数量 | Group 中的样本数量 | 控制多样性 |
dynamic_sampling_filter_path |
动态过滤器路径 | 动态过滤机制 | 实时过滤不合格样本 |
over_sampling_filter_path |
过采样过滤器路径 | 过采样过滤机制 | 选择最优样本子集 |
rollout_num_gpus_per_engine |
每个引擎的GPU数量 | SGLang Server 配置 | 控制并行度 |
rollout_num_gpus |
总GPU数量 | 系统规模 | 影响整体性能 |
sglang_server_concurrency |
SGLang 服务器并发数 | 并发控制 | 影响生成速度 |