Chapter6.AdaGrad
文档摘要
第六章 AdaGrad 6.1 vanilla gradient descent    梯度下降法是最基础的优化算法,同时也存在如下问题。 学习率太小,损失函数下降过慢,迭代次数多。(蓝色的折线) 学习率过大,损失函数下降快,容易在局部极值点附近振荡。(绿色的折线) 学习率太大,会直接越过局部最优值。(黄色的折线) png    为此,我们是否可以设计一种算法会在根据梯度或者当前周期数就更新学习率呢?AdaGrad(Adaptive Subgradient Methods)正是出于这样思路进行设计的。
第六章 AdaGrad
6.1 vanilla gradient descent
梯度下降法是最基础的优化算法,同时也存在如下问题。
- 学习率太小,损失函数下降过慢,迭代次数多。(蓝色的折线)
- 学习率过大,损失函数下降快,容易在局部极值点附近振荡。(绿色的折线)
- 学习率太大,会直接越过局部最优值。(黄色的折线)
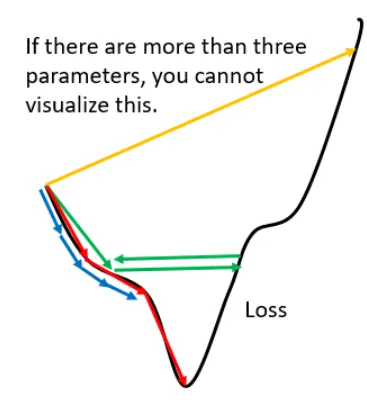
为此,我们是否可以设计一种算法会在根据梯度或者当前周期数就更新学习率呢?AdaGrad(Adaptive Subgradient Methods)正是出于这样思路进行设计的。
假设模型参数为\theta,\theta^t 表示为第 t 个周期的模型参数,同时损失函数为 f(\theta^t)。AdaGrad的迭代格式如下:
其中 \circ 是哈达玛积,用于两个向量的对应元素相乘。由于 g^i\circ g^i 依旧是向量,实际上,AdaGrad算法中模型参数 \theta 的分量都有其自己的学习率。接下来,我们将在假设条件下证明AdaGrad的收敛性。
6.2 收敛性
在机器学习算法应用中,特别是商业落地项目,样本量往往都是上百万甚至上亿,这些数据是无法被一次性放入机器中去的,或者,有一些模型是线上部署的,服务器会实时地搜集用户数据并输入到模型中,这些数据由于时空限制都是无法一次性放入内存中,所以只能分批次去加载这些数据,根据每批次的数据进行优化模型,这就是在线学习。
假设 f_t(\theta) 是第 t 个批次的损失函数,一共有 T 个批次的数据,则
对于这种在线算法,我们从regret的角度去证明其收敛性。
6.2.1 基本假设和参数设置
对于在线学习,我们追求一个low regret,定义如下:
其中 f_t(\theta) 是convex function,t 表示在第 t 周期的损失函数。
当 T \rightarrow \infty ,R(T)的平均值\displaystyle \frac{R(T)}{T}\rightarrow 0 ,该算法收敛,即 \displaystyle \theta^* = arg \min_{\theta} \sum_{t=1}^T f_t(\theta)。
在证明之前,我们先进行一些假设:
假设一
假设 \theta\in \mathbb{R}^d 是模型参数,并且可行域有界,即对于向量 \theta 中分量 \forall \theta_i,\hat{\theta_i},存在一个常数 D_i>0,使得下式成立
假设二
假设 \displaystyle g^t := \frac{\partial f_t}{\partial \theta} |_{\theta^t}(如果 f_t 不可导,可以使用次梯度),另存在常数 G_i >0,对于梯度的每个分量对 \forall t 满足
6.2.2 证明过程
假设 \displaystyle \theta^* = arg \min_{\theta} \sum_{t=1}^T f_t(\theta),
由于f_t(\theta) 是convex函数,所以
上式是convex函数的First-order condition,详细定义和证明可参考文献[3]的3.1.3小节。
然后,我们可以得到
代入到 R(T),得
同时
最后我们可以得到
同时,已知 \theta^{t+1} = \theta^t - \alpha^t_i g^t_i, 其中\displaystyle \alpha^t_i = \frac{\eta}{\displaystyle \sum_{j=0}^t (g^j_i)^2}.
因此可以得到
同时
那么
代入\alpha^t_i的定义,最后可以得到
又根据假设二,可以得到
所以
最后,证明得到
6.2.3 总结
显而易见的,随着时间的增长,\displaystyle \sqrt{\sum_{i=0}^{t} g^i\odot g^i} 会导致越来越大,导致梯度下降法中的步长越来越小,很可能在未找到极小值之前就停止了。
6.3 代码
import torch import numpy as np import matplotlib.pyplot as plt import torch.nn as nn torch.cuda.is_available() # generate dataset for training and testing test_nums = 16 interval = [0,2*np.pi] # interval x_train = np.arange(interval[0],interval[1],0.05) y_train = np.sin(x_train) x_test = np.random.random_sample(test_nums)*interval[1] + interval[0] y_test = np.sin(x_test) # show dataset plt.scatter(x_train,y_train,s=1, label="train") plt.scatter(x_test,y_test,s=1, label="test") plt.legend() plt.show()
from torch.utils import data class Mydataset(data.Dataset): def __init__(self,x,y): self.x = x self.y =y def __len__(self): return self.x.shape[0] def __getitem__(self,idx): x = torch.tensor(self.x[idx]).unsqueeze(0).to(torch.float32) y = torch.tensor(self.y[idx]).unsqueeze(0).to(torch.float32) return x,y Train_dataset = Mydataset(x_train,y_train) Test_dataset = Mydataset(x_test,y_test) # constructe the model class Mymodel(nn.Module): def __init__(self): super(Mymodel,self).__init__() self.layer=nn.Sequential( nn.Linear(1,32), nn.ReLU(inplace=True),#do the operation in-place # nn.Sigmoid(),#do the operation in-place # nn.Linear(2,2), # nn.ReLU(inplace=True), nn.Linear(32,1), ) def forward(self,x): y_hat = self.layer(x) return y_hat from torchvision import datasets,transforms from torch.utils.data import DataLoader from torch import optim # set the hyperparameters batch_size = 16 epoch_num = int(1e5) lr = 0.01 #learning rate loss_func = nn.MSELoss() # loss function Train_loader = DataLoader(Train_dataset,batch_size=batch_size,shuffle=True) Test_loader = DataLoader(Test_dataset,batch_size=batch_size,shuffle=False,drop_last=True) device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model = Mymodel().to(device) # 参数的具体可以参考官网 optimizer=optim.Adagrad(model.parameters(),lr=lr,lr_decay=0, weight_decay=0, initial_accumulator_value=0) for epoch_item in range(epoch_num): temporary_loss = 0 for i, (inputs,outputs) in enumerate(Train_loader): inputs,outputs=inputs.to(device),outputs.to(device) optimizer.zero_grad() outputs_hat = model(inputs) # print(inputs.size(),outputs.size(),outputs_hat.size()) loss=loss_func(outputs,outputs_hat).to(device) temporary_loss += loss.item() # calculate the gradient which backpropagation needs loss.backward() # update the values by gradient descent optimizer.step() if epoch_item % 1000 ==0: print("epoch: %d,loss:%f"%(epoch_item,temporary_loss/(i+1)))
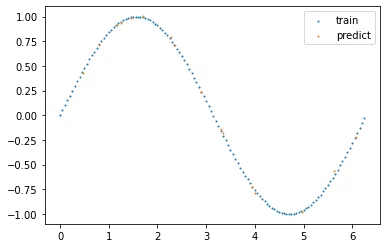
测试模型的效果
Test_loss = 0 y_hat= [] with torch.no_grad(): for i, (inputs,outputs) in enumerate(Test_loader): inputs,outputs=inputs.to(device),outputs.to(device) optimizer.zero_grad() outputs_hat = model(inputs) y_hat.append(outputs_hat.cpu().numpy()) loss=loss_func(outputs,outputs_hat).to(device) Test_loss += loss.item() break print("test loss:%f"%(Test_loss/test_nums)) plt.scatter(x_train,y_train,s=1, label="train") plt.scatter(x_test,y_hat,s=1, label="predict") plt.legend() plt.show()
参考文献
【1】
【2】收敛性证明
【3】Convex Optimization
【4】FIRST-ORDER METHODS IN OPTIMIZATION
【5】AdaGrad收敛性证明论文