第一章 LangChain与LangGraph框架认知
文档摘要
第一章 LangChain与LangGraph框架认知 前言 欢迎进入easy-langent的学习之旅。作为我们的第一节的内容,核心不是让大家立刻写出复杂的智能体,而是帮大家建立对两个核心框架的基本认知——搞明白它们是什么、能解决什么问题,再亲手把开发环境搭起来,跑通第一个简单案例。就像我们学任何一门新技术一样,先“认识它”,再“上手摸一摸”,基础打扎实了,后面的学习才会更轻松。 所以这一章结束后,你需要做到这几件事: 理解AI Agent开发中会遇到的麻烦,知道LangChain和LangGraph各自的定位; 能独立搭好开发环境;能运行两个框架的基础案例,感受到它们的用法差异。 带着这些目标,我们开始今天的学习吧。 1.
第一章 LangChain与LangGraph框架认知
前言
欢迎进入easy-langent的学习之旅。作为我们的第一节的内容,核心不是让大家立刻写出复杂的智能体,而是帮大家建立对两个核心框架的基本认知——搞明白它们是什么、能解决什么问题,再亲手把开发环境搭起来,跑通第一个简单案例。就像我们学任何一门新技术一样,先“认识它”,再“上手摸一摸”,基础打扎实了,后面的学习才会更轻松。
所以这一章结束后,你需要做到这几件事:
- 理解AI Agent开发中会遇到的麻烦,知道LangChain和LangGraph各自的定位;
- 能独立搭好开发环境;能运行两个框架的基础案例,感受到它们的用法差异。
带着这些目标,我们开始今天的学习吧。
1.1 为什么需要LangChain和LangGraph
在正式开始前,先跟大家确认下前置知识——不需要你是Python大神,只要能看懂基础的变量、函数,会用终端输入简单命令就行;对大模型有个模糊的概念(比如知道LLM是大语言模型)就足够了,不用深入了解原理。如果这些基础你都具备,那我们可以直接出发;如果有些遗忘也没关系,遇到相关知识点可以去搜索相关的资料,帮你回忆起来。
我们先从一个常见的开发场景说起:假设你想做一个“智能论文助手”,功能很简单,就是帮用户总结论文内容、解答论文里的疑问。如果现在没有任何框架,全靠自己写代码,你会发现要解决一堆麻烦事。
首先,你得自己写代码调用OpenAI、Anthropic这些大模型的API,而且不同厂商的API参数不一样,换个模型就要改一次代码;其次,如果用户问了多个问题,助手要记住之前的对话内容,这部分“对话历史管理”得自己实现;再往后,如果想让助手查最新的文献(也就是工具调用),你还得自己写代码连接文献数据库,还要处理查询结果的解析;要是功能再复杂点,比如让助手分步骤总结论文——先提取核心观点,再整理逻辑,最后生成摘要,这整个流程的管控、中间结果的保存,都会让代码变得特别繁琐。
这就是传统开发模式的三个核心痛点:重复造轮子(每次开发都要重写模型调用、对话管理这些通用代码)、流程管控复杂(多步骤任务容易出错)、状态维护困难(中间数据不好保存和传递)。
而LangChain和LangGraph,就是为了解决这些麻烦而生的工具。你可以把它们理解成“开发大模型应用的工具箱”和“复杂应用的设计图”——它们把那些通用的、繁琐的功能都封装好了,你不用再纠结底层实现,只要专注于自己的业务场景(比如“论文助手”的核心逻辑)就行。这也是我们要学这两个框架的核心原因:提高开发效率,让智能体开发变得更简单。
1.2 LangChain与LangGraph的定义与核心区别
接下来我们逐个认识这两个框架。先记住一个核心结论:它们不是竞争关系,而是互补的——一个帮你快速搭基础,一个帮你管控复杂流程。
1.2.1 LangChain:大模型应用的“基础设施工具箱”
LangChain的定位很明确:帮你快速搭建简单到中等复杂度的大模型应用。我更愿意把它比作“乐高积木”——里面有各种各样现成的“积木块”,比如调用大模型的组件、管理对话历史的组件、连接工具的组件等等。你不用自己造积木,只要根据需求把这些积木拼起来,就能快速做出一个简单的应用。
它的核心价值就是降低入门门槛、提高开发效率。比如你想快速做一个文本生成工具,或者一个简单的文档问答工具,用LangChain就能很快实现,不用从零开始写代码。
具体来说,这几种场景用LangChain就很合适:简单的LLM调用(比如生成文本、翻译)、基础的RAG(让模型结合本地文档回答问题)、单步骤的工具调用(比如让模型调用一次计算器)、快速验证想法(比如想试试“用大模型做错题分析”是否可行,用LangChain能快速做出原型)。
LangChain 从 1.0 之后被拆成了三层:
| 模块 | 职责 |
|---|---|
langchain_core |
核心抽象(Runnable、BaseParser 等) |
langchain |
高级工程组件(Chains / Parsers / Memory) |
langchain_openai |
第三方模型适配 |
LangChain 的三层架构可以直观地理解为:langchain-core是地基和规则,langchain是用地基上的标准构件搭建好的功能房间,而 langchain-openai等集成包则是连接外部服务的门窗和管线。
为何要这样分层?
这种架构的核心优势在于关注点分离和生态系统的健康发展。
- 核心团队可以更专注:LangChain的核心团队只需维护好langchain-core的稳定性和抽象能力,而不必陷入对海量第三方服务API变更的维护工作中。
- 社区可以更开放地共建:任何第三方服务都可以按照langchain-core定义的规范,开发自己的集成包(如langchain-google-genai, langchain-community等),共同丰富LangChain的生态。
- 开发者可以更灵活:你可以根据需要选择性地安装和更新特定集成,避免了安装一个庞然大物般的单体包。这种模块化设计也使得整个框架更易于维护和扩展。
1.2.2 LangGraph:复杂应用的“架构设计框架”
如果说LangChain是“乐高积木”,那LangGraph就是“建筑设计图”。当你想搭建“高楼大厦”——也就是复杂的大模型应用时,光有积木不够,还需要设计图来规划积木的摆放顺序、结构逻辑。LangGraph就是基于LangChain的这个“设计图”,专门处理那些多步骤、需要协作的复杂任务。
它的核心价值是支持状态管理、复杂流程管控和多智能体协作,正好弥补了LangChain处理复杂任务的短板。比如刚才说的“分步骤总结论文”,从上传论文到提取观点,再到整理逻辑、生成摘要,整个流程的顺序管控、中间结果的保存,用LangGraph就能很清晰地实现。
这些场景适合用LangGraph:多步骤流程(比如刚才说的论文总结多步骤任务)、需要保存中间结果的场景(比如记住用户上一步的需求)、多智能体协作(比如让一个“检索Agent”找文献,一个“分析Agent”总结观点,再用一个“协调Agent”分配任务)、需要人机交互的流程(比如执行到某一步需要用户确认信息,再继续往下走)。
1.2.3 两个框架的核心关系
最后再帮大家理清两者的关系,避免混淆:首先是从属关系,LangGraph不是独立于LangChain的,它是LangChain生态的进阶扩展,依赖LangChain的核心组件(比如模型调用、工具这些“积木”),只是在流程管控、状态管理上做了增强;其次是互补关系,简单的任务用LangChain(快、简单),复杂的任务用LangGraph(稳、可控),实际开发中我们经常会把它们融合起来用——用LangChain搭好基础组件,再用LangGraph设计复杂的流程。
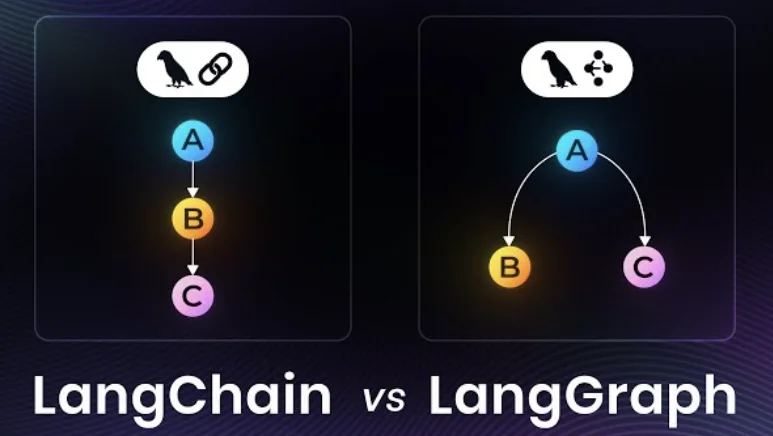
再用一个形象的类比帮大家记住:
- 用LangChain开发,像用积木快速拼一个小房子(简单、快);
- 用LangGraph开发,像用积木+设计图建一栋高楼(复杂、但结构清晰、可扩展)。
1.3 实操环节:搭建开发环境
讲完了理论认知,接下来就是最关键的实操环节——搭开发环境。
这一步是所有后续学习的基础,跟着教程一步步操作,遇到问题不用慌,可以寻求大模型来帮忙解决。
1.3.1 环境要求
- Python版本:3.10及以上(推荐3.10,兼容性最好);
- 网络:能访问互联网(需要下载依赖、调用大模型API);
- 编辑器:推荐PyCharm(专业版/社区版均可)或VS Code(需安装Python插件)。
1.3.2 具体步骤(Windows/Mac通用)
1.3.2.1 步骤1:创建虚拟环境(避免依赖冲突)
在开始项目之前,请务必先创建虚拟环境,避免不同项目之间的 Python 依赖相互污染。
方式一:使用 venv(Python 自带,通用方案)
打开终端/命令行,执行以下命令:
# 1.新创建一个文件夹 easy-langent # Windows python -m venv langent-env # Mac / Linux python3 -m venv langent-env # 2. 激活虚拟环境 # Windows(cmd) langent-env\Scripts\activate # Windows(PowerShell) .\langent-env\Scripts\Activate.ps1 # Mac / Linux source langent-env/bin/activate
方式二:使用 Conda
# 1. 创建虚拟环境(建议 Python 3.10) conda create -n langent-env python=3.10 -y # 2. 激活虚拟环境 conda activate langent-env
方式三:使用 uv
uv 是新一代 Python 包管理器,由 Rust 编写,拥有超快的安装速度和跨平台支持。相比 Conda,uv 更轻量、依赖解析更智能,是 Agent 开发中推荐的环境管理工具。
uv 优势:
- ⚡ 极速安装:比 pip 快 10-100 倍
- 智能依赖解析:自动处理依赖冲突
- 统一管理:同时管理项目依赖和虚拟环境
- 多版本 Python:轻松切换不同 Python 版本
初始化项目
打开终端并导航到对应目录
# 创建项目目录和虚拟环境 # 全系统通用 uv init easy-langent --python 3.10 cd easy-langent uv venv
后续操作
运行脚本:使用 uv run xxx.py 替代 python xxx.py
包管理:使用 uv pip 代替 pip 命令
激活虚拟环境:
# Windows(cmd) .venv\Scripts\activate # Windows(PowerShell) .\.venv\Scripts\Activate.ps1 # Mac / Linux source .venv/bin/activate
可选:配置国内镜像源(提升安装速度)
国内网络安装 Python 包较慢时,建议配置 PyPI(pip) 国内镜像源。
说明:本文以清华镜像为例,也可根据网络状况替换为中科大或其他国内PyPI镜像。
无论使用 venv 还是 Conda 环境,课程中统一使用pip安装依赖,只需配置 pip 镜像。Conda 提供了原生的包管理能力(
conda install),为避免混用产生冲突,此处不作深入介绍,了解即可。
1. pip(venv / Conda 环境通用)
设为默认(永久配置,推荐)
# 清华镜像 pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple # 中科大镜像(备选,二选一) # pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/simple
临时使用(仅当前命令生效):
# 清华镜像 pip install 包名 -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple # 中科大镜像(备选) # pip install 包名 -i https://mirrors.ustc.edu.cn/pypi/simple # 替换实际要安装的包名,比如: # pip install langchain -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
2. uv(uv 环境专用)
编辑或创建配置文件
Linux/Unix:在 ~/.config/uv/uv.toml 或者 /etc/uv/uv.toml
Windows:在 %AppData%\uv\uv.toml 或者 %ProgramData%\uv\uv.toml
填写如下内容
[[index]] url = "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/" default = true
中科大镜像(备选,二选一)
[[index]] url = "https://mirrors.ustc.edu.cn/pypi/simple" default = true
⚠️ 注意事项:
- 一个项目 只使用一种虚拟环境方式(venv、conda或uv)
- 后续所有
pip install/python xxx.py操作,都必须在已激活的虚拟环境中进行 - uv 使用
uv run xxx.py替代python xxx.py和使用uv pip代替pip命令不需要手动激活虚拟环境
1.3.2.2 步骤2:安装核心依赖
在激活的虚拟环境中,执行以下命令安装LangChain、LangGraph及常用依赖:
常规python/conda 安装依赖
# 安装LangChain核心库 pip install langchain # 安装LangGraph pip install langgraph # 安装OpenAI依赖(用于调用OpenAI模型,我们案例用这个) pip install openai pip install langchain_openai # 安装其他辅助依赖 pip install python-dotenv # 用于管理环境变量(存储API密钥) pip install ipykernel # 用于在Jupyter Notebook中运行代码
uv 安装依赖
如果下载速度很慢记得上方添加国内源
uv add langchain langchain-openai langgraph langchain-community ipykernel
安装成功验证
激活虚拟环境,在终端输入python,进入Python交互环境,依次执行以下代码无报错即可:
import langchain import langgraph import openai import importlib from dotenv import load_dotenv load_dotenv() # 如按本文前面步骤操作,此时 `load_dotenv()` 函数返回 `False` 是正常的 print("LangChain版本:", langchain.__version__) print("LangGraph版本:", importlib.metadata.version("langgraph")) print("OpenAI版本:", openai.__version__)
运行结果示例(版本以实际为准)
False LangChain版本: 1.2.15 LangGraph版本: 1.1.6 OpenAI版本: 2.31.0
注意: LangChain 和 LangGraph 必须安装1.0.0以后的版本,1.0.0以前的版本与1.0.0以后的版本不兼容,会对学习产生比较大的影响!!!
1.3.2.3 步骤3:配置API密钥
我们的案例需要调用大模型,可以通过官网购买deepseek、qwen或者chatgpt等模型服务提供商的服务以获取api key,也可以使用硅基流动的云端模型服务。特别注意,api key请妥善保存,最好不要泄露给别人。
| 服务商 | 官网 |
|---|---|
| DeepSeek | https://platform.deepseek.com/usage |
| 通义千问(Qwen) | https://bailian.console.aliyun.com/ |
| ChatGPT(OpenAI) | https://chatgpt.com/ |
| 智谱 AI(GLM) | https://bigmodel.cn/ |
| 硅基流动 | https://cloud.siliconflow.cn/ |
本教程选择的是deepseek官网的api,可以根据个人情况选择不同的底座模型
在项目文件夹(easy-langent)中新建一个文件,命名为".env"(注意前面有个点),或者直接复制根目录下的 .env.example 模板文件,然后修改文件名为 .env。
Tips: windows系统会存在隐藏扩展名的问题,新建
.env时,需要点击【查看】->【显示】->勾选【文件扩展名】,才能看到隐藏扩展名。
步骤3.1:编辑.env文件
用编辑器打开.env文件,写入以下内容(替换成你的API密钥):
API_KEY="YOUR_API_KEY" BASE_URL="YOUR_BASE_URL"
步骤3.2:在Python代码中调用环境变量
from dotenv import load_dotenv import os load_dotenv() API_KEY = os.getenv("API_KEY") BASE_URL = os.getenv("BASE_URL") # API地址,使用你的模型对应的地址(如DeepSeek: https://api.deepseek.com)
在配置调用大模型服务时,通常需要输入 API Key、Token 或各类平台密码,为了安全起见一般是将这类密码配置到环境变量中,而不是直接写到代码中,密钥被恶意盗用,将会导致严重的经济损失或隐私泄露。
1.3.3 常见错误解决
- 错误1:“pip不是内部或外部命令”——解决:检查Python是否添加到系统环境变量,或用“python -m pip”代替“pip”;
- 错误2:安装依赖时超时——解决:用国内镜像源,见1.3.2.1可选配置;
- 错误3:激活虚拟环境失败(PowerShell)——解决:以管理员身份打开PowerShell,执行“Set-ExecutionPolicy RemoteSigned”,选择“Y”允许;
1.4 上手体验:两个框架的“Hello World”案例
环境搭建完成后,我们用两个最简单的案例体验LangChain和LangGraph的核心用法——不用纠结复杂逻辑,先跑通代码,感受框架的使用流程。
1.4.1 LangChain案例:简单文本生成
功能:调用OpenAI模型,生成一段“AI学习建议”。
# 1. 导入模块 import os from dotenv import load_dotenv from langchain_openai import ChatOpenAI # 2. 加载 .env 环境变量 load_dotenv() # 3. 配置 API Key API_KEY = os.getenv("API_KEY") BASE_URL = os.getenv("BASE_URL") if not API_KEY: raise ValueError("未检测到 API_KEY,请检查 .env 文件是否配置正确") # 4. 初始化大模型 llm = ChatOpenAI( api_key=API_KEY, base_url=BASE_URL, model="deepseek-chat", # 注意:根据你使用的模型修改名称!!!! 后面章节不再继续说明 temperature=0.3 ) # 5. 构造 Prompt(教学阶段用字符串更直观) prompt = "请写一段50字左右的 AI 学习建议,语言简洁、实用,适合初学者。" # 6. 调用模型 response = llm.invoke(prompt) # 7. 输出结果 print("生成的学习建议:") print(response.content)
代码解释:
- ChatOpenAI:LangChain封装的OpenAI对话模型接口,不用我们自己写HTTP请求调用API;
- invoke:模型调用方法,传入格式化后的提示词,返回生成结果。
运行结果示例:
生成的学习建议: 1. 先动手:从简单项目开始,跑通代码比纯理论更重要。 2. 重基础:掌握Python、线性代数和概率论核心概念。 3. 读代码:多分析经典开源项目,理解实现逻辑。 4. 常复现:尝试复现论文基础模型,训练调试能力。 5. 保持好奇:关注AI动态,用实践验证新想法。 (注:共50字,聚焦可执行步骤,避免抽象建议。)
1.4.2 LangGraph案例:基础工作流执行
功能:实现一个简单的“两步工作流”——第一步生成学习建议,第二步对建议进行精简。
# 1. 导入需要的模块 import os from langchain_openai import ChatOpenAI from langgraph.graph import StateGraph, START, END from typing import TypedDict from dotenv import load_dotenv # 2. 加载API密钥 load_dotenv() # 3. 配置 API Key API_KEY = os.getenv("API_KEY") BASE_URL = os.getenv("BASE_URL") if not API_KEY: raise ValueError("未检测到 API_KEY,请检查 .env 文件是否配置正确") # 4. 初始化大模型(和LangChain案例一样) llm = ChatOpenAI( api_key=API_KEY, base_url=BASE_URL, model="deepseek-chat", # 注意:根据你使用的模型修改名称!!!! 后面章节不再继续说明 temperature=0.3 ) # 5. 定义 State class WorkflowState(TypedDict, total=False): user_role: str # 存储用户角色 original_advice: str # 存储原始学习建议 simplified_advice: str # 存储精简后的建议 # 6. 定义节点 def generate_advice(state: WorkflowState): prompt = f"给{state['user_role']}写一段50字左右的 AI 学习建议。" result = llm.invoke(prompt) return {"original_advice": result.content} def simplify_advice(state: WorkflowState): prompt = f"把下面的学习建议精简到30字以内:{state['original_advice']}" result = llm.invoke(prompt) return {"simplified_advice": result.content} # 7. 构建工作流 workflow = StateGraph(WorkflowState) workflow.add_node("generate", generate_advice) workflow.add_node("simplify", simplify_advice) workflow.add_edge(START, "generate") workflow.add_edge("generate", "simplify") workflow.add_edge("simplify", END) app = workflow.compile() # 8. 执行 result = app.invoke({"user_role": "高校学生"}) # 9. 输出 print("原始学习建议:") print(result["original_advice"]) print("\n精简后学习建议:") print(result["simplified_advice"])
代码解释(重点理解LangGraph核心概念):
- State(状态):WorkflowState类定义的结构,相当于工作流的“共享数据容器”,用于传递和存储中间结果(比如第一步的原始建议、第二步的精简建议);
- Node(节点):每个节点对应一个函数,负责完成一个具体任务(生成建议、精简建议),函数接收状态作为输入,处理后返回更新后的状态;
- Edge(边):定义节点的执行顺序(START→generate→simplify→END),相当于工作流的“流程规划图”;
- compile(编译):把状态图、节点、边的定义,转换成可执行的工作流实例;
- invoke(执行):传入初始状态,工作流会按定义的顺序执行节点,最终返回完整的状态(包含所有中间结果和最终结果)。
运行结果示例:
原始学习建议: AI时代,学习建议:掌握基础数学与编程,动手实践项目;保持批判思维,关注伦理;善用AI工具辅助学习,但别依赖;持续跟进前沿,加入社群交流。最重要的是,保持好奇与热情。 精简后学习建议: 学基础,重实践,持批判,善用AI,追前沿,保热情。
对比LangChain案例:这个案例的核心是“流程管控”——我们明确定义了“生成→精简”的顺序,并且用状态存储了中间结果,这就是LangGraph处理多步骤任务的优势。
1.5 本章小结
- 核心认知:LangChain是“基础工具包”(快速搭简单应用),LangGraph是“架构框架”(管控复杂流程),两者互补融合;
- 实操重点:开发环境搭建(虚拟环境+依赖+API密钥)是后续所有学习的基础,必须跑通;
- 框架核心:LangChain的核心是“组件拼接”,LangGraph的核心是“状态+节点+流程”。
1.6 本章练习
- 复现本章两个案例的代码,确保能成功运行;
- 修改LangChain案例的Prompt,把“AI学习建议”改成“LangChain学习建议”,观察生成结果;
- 修改LangGraph案例的工作流,添加一个“第三步节点”(比如“把精简后的建议翻译成英文”),重新编译并执行;
- 思考:如果要开发一个“智能问答机器人”(只需要简单对话,不用多步骤),应该用LangChain还是LangGraph?为什么?