第 9 章 最小原子工具集——用 9 个工具覆盖完整能力环
文档摘要
第 9 章 最小原子工具集——用 9 个工具覆盖完整能力环 在前面的章节中,我们建立了 GA 的第一性原理——上下文信息密度最大化(第 7 章),并从全局视角了解了 GA 的系统架构和四大核心机制的协作方式(第 8 章)。从本章开始,我们将沿着信息生命周期的顺序,逐一深入每个核心机制。 第一站,是信息进入上下文之前的第一道关口:最小原子工具集(Minimal Atomic Toolset)。工具定义是上下文中每轮都要重复支付的固定成本——在任务执行开始之前,这些定义就已经占据了宝贵的上下文预算。因此,工具层的设计直接决定了上下文的"先天信息密度"。 一个很自然的问题是:既然 Agent 需要与外部世界交互,那为什么不给它尽可能多的工具?工具越多,能力不就越强吗? 9.1 工具膨胀的代价 9.
第 9 章 最小原子工具集——用 9 个工具覆盖完整能力环
在前面的章节中,我们建立了 GA 的第一性原理——上下文信息密度最大化(第 7 章),并从全局视角了解了 GA 的系统架构和四大核心机制的协作方式(第 8 章)。从本章开始,我们将沿着信息生命周期的顺序,逐一深入每个核心机制。
第一站,是信息进入上下文之前的第一道关口:最小原子工具集(Minimal Atomic Toolset)。工具定义是上下文中每轮都要重复支付的固定成本——在任务执行开始之前,这些定义就已经占据了宝贵的上下文预算。因此,工具层的设计直接决定了上下文的"先天信息密度"。
一个很自然的问题是:既然 Agent 需要与外部世界交互,那为什么不给它尽可能多的工具?工具越多,能力不就越强吗?
9.1 工具膨胀的代价
9.1.1 直觉理解
想象你走进一家五金店。你需要拧一颗螺丝,店员递给你一本 200 页的工具目录,里面有 53 种不同的螺丝刀——十字的、一字的、六角的、带棘轮的、电动的、可弯曲的……你需要先花 10 分钟翻阅目录,理解每种螺丝刀的区别,然后才能做出选择。
而另一家店只给你一把通用螺丝刀和一个万能批头套装。你拿起来就能干活。
对于 LLM Agent 来说,"翻阅工具目录"的代价远比你想象的大。因为每一轮对话中,所有可用工具的定义都会被注入到上下文中。工具越多,这些定义占用的 token 就越多——而且这是每轮都要重复支付的固定成本。
9.1.2 深入理解:工具膨胀的两层代价
论文指出,工具膨胀在两个层面同时产生系统性的负面影响:
第一,提示词层面(Prompt Level)的上下文预算挤占。 每增加一个工具,就需要在上下文中注入该工具的 Schema(名称、描述、参数类型、约束说明)和相关指令。在多轮交互中,这些开销每轮累积,直接挤占了本应留给任务信息的有效上下文预算。以 Claude Code 为例,53 个工具的 Schema 可能消耗数千甚至上万 token——这还不包括伴随的使用说明文本。
第二,策略层面(Policy Level)的决策复杂度增长。 每增加一个工具,就扩大了模型的动作空间,增加了工具选择时的歧义性。比如,FileReadTool 和 GrepTool 都可以读取文件内容,BashTool 也可以通过 cat 命令实现同样的效果。模型需要理解这三个工具的微妙差异才能做出正确选择。这种歧义会削弱工具使用模式的稳定性,增加执行错误和不必要重试的概率。
这两层代价共同作用的结果,可以从实验数据中直观看到。即使暴露了几十个工具,真正被频繁调用的往往只是少数几个:
| Agent 系统 | 工具总数 | 最常用工具及占比 |
|---|---|---|
| Claude Code | 53 个 | AgentTool (50.4%)、WebFetchTool (22.1%)、FileReadTool (10.6%) |
| OpenClaw | 18 个工厂 | browser (32.5%)、exec (20.5%)、web_fetch (15.7%) |
| GA | 9 个 | code_run (34.4%)、file_read (31.2%)、update_working_checkpoint (17.2%) |
Claude Code 虽然暴露了 53 个工具,但超过 80% 的调用集中在仅仅 3 个工具上,剩余 47 个工具几乎从不被使用。这意味着这 47 个工具的 Schema 每轮都在消耗上下文预算,却几乎不贡献决策价值——这正是上下文信息密度的反面。
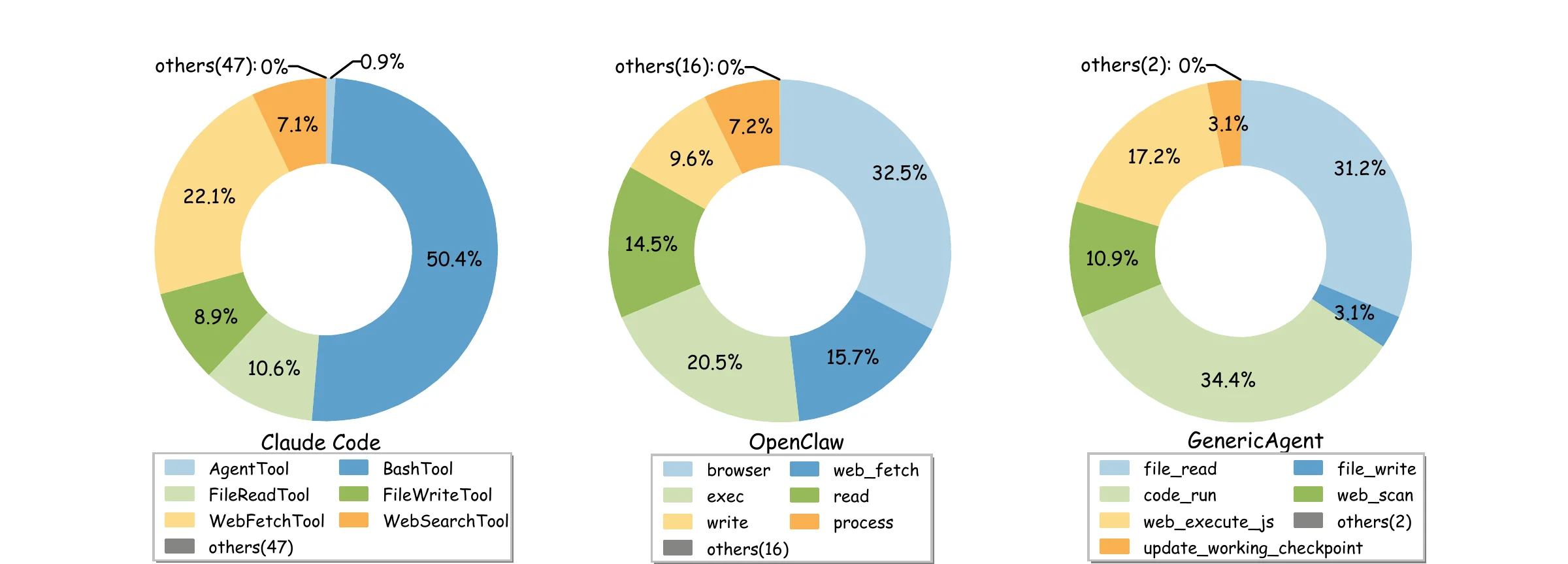
图 9-1:Claude Code、OpenClaw 和 GA 的工具使用分布。尽管 Claude Code 和 OpenClaw 暴露了数十个工具,但实际调用高度集中于少数几个。GA 将这个"活跃工具环"显式化为 9 个原子工具,消除了长尾浪费。(来源:论文 Figure 3)
论文的结论非常明确:工具最小化不仅仅是一种节俭策略,而是一个更优的运行点(a better operating point)——它同时降低了提示词开销和决策复杂度。
那么,GA 如何解决这个问题?答案出奇地简单:只保留 9 个工具。
9.2 GA 的 9 个原子工具
9.2.1 直觉理解:乐高积木而非瑞士军刀
GA 的工具设计哲学可以用一个类比来概括:不要瑞士军刀,要乐高积木。
瑞士军刀为每种功能设计了一个专用部件——开瓶器、剪刀、锯子、锉刀……虽然功能多,但每个部件都是固定形态,无法组合。而乐高积木只有几种基本形状的砖块,却可以通过组合搭建出无限可能。
GA 的 9 个工具就是 9 块"乐高积木"。论文指出,工具选择必须满足两个条件:
- 原子性(Atomicity):每个工具被约束为不可再分的原始能力(irreducible primitive capability),执行单一职责,工具之间不存在功能重叠
- 组合泛化(Compositional Generalization):复杂行为通过原子工具的序列组合来实现,而非通过引入新的专用接口
换句话说,GA 通过组合而非枚举来获取能力:少量原子工具作为可复用的原语(reusable primitives),复杂行为从它们的组合中涌现。
9.2.2 深入理解:五大能力类与九大原子工具
GA 将 Agent 与外部世界的所有交互归纳为五大能力类(Capability Classes),每个能力类下放置 1–3 个原子工具:
┌─────────────────────────────────────────────────────────┐ │ GA 原子工具集架构 │ ├──────────────┬──────────────────────────────────────────┤ │ 能力类 │ 工具 │ ├──────────────┼──────────────────────────────────────────┤ │ 文件操作 │ file_read · file_patch · file_write │ │ 代码执行 │ code_run │ │ 网页交互 │ web_scan · web_execute_js │ │ 记忆管理 │ update_working_checkpoint │ │ │ start_long_term_update │ │ 人机协作 │ ask_user │ └──────────────┴──────────────────────────────────────────┘
论文指出,每个工具维持单一职责,这些工具共同构成了一个完整的循环,覆盖状态观测、动作执行、上下文保持和干预请求四个环节:
- 状态观测(State Observation):
file_read读取文件内容,web_scan扫描网页信息——让 Agent 能"看见"外部世界的状态 - 动作执行(Action Execution):
file_patch/file_write修改文件,code_run执行代码,web_execute_js操作浏览器——让 Agent 能"改变"外部世界 - 上下文保持(Context Preservation):
update_working_checkpoint维护短期工作记忆,start_long_term_update触发长期记忆蒸馏——让 Agent 能"记住"重要信息 - 干预请求(Intervention Request):
ask_user在需要人类决策时请求介入——让 Agent 知道自己的能力边界
在第一部分的应用篇中,我们已经实际使用过这些工具。本章的重点不是"怎么用",而是理解"为什么是这 9 个,为什么不多也不少"。
9.2.3 关键工具的设计细节
每个原子工具都经过了面向执行效率的专门优化。论文指出,这些优化的目标不仅是压缩单次工具输出,更是通过在每一步提供更精确、更完整的反馈,来减少后续轮次中的冗余探测和重试,从而在多轮交互中降低整体 token 消耗。我们来看几个典型例子:
file_read:精准读取,拒绝"全文搬运"
file_read 不是简单的"把整个文件内容返回"。它支持分段读取(start/count)、关键词锚定(keyword)和行号输出,使 Agent 只获取"当前决策需要的那几行代码",而不是把一个 5000 行的文件全部塞入上下文。
# 模式 1:指定范围读取——只读文件的第 100-120 行 file_read(path="main.py", start=100, count=20) # 模式 2:关键词锚定——跳到包含 "def train" 的位置 file_read(path="main.py", keyword="def train")
file_patch:唯一匹配,拒绝"沉默错误"
file_patch 要求 old_content 参数在目标文件中恰好匹配一处。如果匹配零处(内容不存在)或多处(存在歧义),工具会直接报错而非静默执行。这种快速失败(Fail-Fast) 设计避免了"改错位置"的沉默错误——在 Agent 自主运行的场景下,沉默错误比报错更危险,因为它可能在很多步之后才被发现。
web_scan:语义提取,拒绝"原始 DOM"
web_scan 是优化最激进的一个工具。它不是简单地返回网页的 HTML 源码,而是执行了一套布局分析算法(layout-analysis algorithm):
- 克隆当前页面的 DOM 树
- 计算每个元素的可见性
- 通过叠加分析和区域划分,将区域分类为"主要内容"和"非核心区域"(导航栏、侧边栏、广告等)
- 移除被遮挡或隐藏的元素
- 序列化为结构化的精简文本
论文指出,这套处理将 token 消耗降低了一个数量级——一个原始 DOM 可能包含数万个 token,而经过 web_scan 处理后通常只剩几千个 token,且关键信息完整保留。
web_execute_js:操作结果 + 页面变化观测
web_execute_js 在返回操作结果的同时,还会附带页面变化的观测信息。这意味着很多工作流无需再发起一次完整的 web_scan 就能继续推进——减少了一轮完整的"扫描→分析"循环。
code_run:一轮一次,观察后再行动
code_run 被限制为每轮只能调用一次。这不是任意的约束,而是一种执行纪律:确保每次代码执行的结果都被模型观察和评估后,才能决定下一步行动。这种"先看结果再行动"的节奏,防止了模型在没有反馈的情况下连续发起多个可能相互冲突的操作。
一个关键视角:论文指出,理论上 Agent 可以仅凭
code_run一个工具完成所有任务——通过编写自定义脚本,它能复制其他每个工具的功能。因此,其余 8 个工具的存在不是为了扩展 Agent 的能力边界,而是作为专用快捷方式(specialized shortcuts) 来降低决策成本和操作开销。论文将这种设计称为工具脚手架(harness)——它让 Agent 专注于高效解决问题,而不必为每个简单操作都从头编写代码。
这是"上下文信息密度最大化"原则在工具层的直接体现:同样是"看网页",返回原始 HTML 是低信息密度的(大量标签、样式、脚本),返回结构化摘要是高信息密度的。
9.3 能力边界与执行纪律
工具不仅是"能力"的体现,也是"权限"的边界。论文将这种设计称为能力边界与执行纪律(Capability Boundaries and Execution Discipline):Agent 的能力范围严格由注入的工具集定义,每个工具的能力范围严格有界且互不重叠。
9.3.1 直觉理解
这就好比一个公司的权限管理系统。每个员工的操作权限由管理员在系统中配置,员工不能自己给自己加权限。但管理员可以提前给某些员工配置"受控提权通道"——比如 IT 人员可以通过特定审批流程获得服务器的临时管理员权限。
在 GA 中,工具形成了一个从低风险到高风险的权限层级:
- 只读工具(
file_read、web_scan)只能观察,不能修改——Agent 可以看到文件内容和网页信息,但无法改变任何状态 - 编辑工具(
file_patch、file_write)可以修改文本,但受严格的参数约束——file_patch必须精确匹配,file_write必须指定完整内容 - 执行工具(
code_run、web_execute_js)可以触发真实的系统动作——这是风险最高的工具,但也是能力最强的
所有交互都通过统一分发器返回结构化输出,这提升了可控性、降低了操作风险,并确保了每一个动作的完全可追溯性。
9.3.2 深入理解:声明、调用与分发
GA 的所有工具通过一套统一的Schema 契约(Schema Contract) 来定义。每个工具声明其名称、描述和参数(以 JSON Schema 格式描述),统一使用 type: function 格式:
{ "type": "function", "function": { "name": "file_read", "description": "Read file content with optional range and keyword anchoring", "parameters": { "type": "object", "properties": { "path": {"type": "string"}, "start": {"type": "integer"}, "count": {"type": "integer"}, "keyword": {"type": "string"} }, "required": ["path"] } } }
在运行时,这些 Schema 被注入到模型的上下文中。模型根据 Schema 生成结构化的工具调用请求(tool_use call),然后由统一分发器(Unified Dispatcher) 将请求路由到对应的本地执行器。分发器还负责执行前后的处理和结果返回管理,实现了声明、调用和执行的清晰分离。
这种分离意味着模型只需要知道"工具能做什么"和"参数格式是什么",不需要知道工具的具体实现方式。9 个工具的 Schema 开销远小于 53 个工具——这是工具最小化在提示词层面最直接的收益。
9.4 工具组合的威力:实验印证
理论上讲,9 个原子工具覆盖了完整的能力环。但在实践中,它们真的能替代拥有几十个专用工具的系统吗?论文 Section 4.2 的实验数据给出了令人信服的回答。
9.4.1 能力覆盖:专用工具 → 原子组合
论文的 Table 11 展示了具体的替代案例——每个专用工具的功能都可以通过少量原子工具的组合来实现:
| 原系统 | 专用工具 | 代表性任务 | GA 替代方案 | 替代原理 |
|---|---|---|---|---|
| Claude Code | GlobTool |
文件模式匹配 | code_run |
文件模式匹配可通过通用代码执行完成 |
| Claude Code | GrepTool |
文本搜索定位 | code_run + file_read |
文本搜索可通过通用执行与文件读取的组合实现 |
| Claude Code | WebFetchTool |
网页抓取与摘要 | web_scan + web_execute_js + code_run |
网页抓取、清洗和摘要可通过浏览器原语与代码后处理的组合重构 |
| Claude Code | AgentTool |
信息提取 | file_read + code_run + update_working_checkpoint |
显式的子 Agent 委派可通过记忆中存储的子 Agent 策略加通用执行来近似 |
| Claude Code | WebSearchTool |
在线搜索 | web_execute_js + web_scan |
在线搜索可通过浏览器交互加网页读取完成 |
| Claude Code | NotebookEditTool |
Jupyter 检查 | file_read + code_run |
读取 .ipynb 的 JSON 结构并执行解析脚本 |
| OpenClaw | nodes(结构化数据) |
CSV 统计 | code_run |
CSV 统计可通过通用代码执行完成,无需专用结构化数据工具 |
论文的关键论点是:GA 不是试图逐一复制这些专用工具,而是证明了许多基准能力可以通过少量原子工具的短序列组合来重构。
9.4.2 效率对比:更少的工具,更低的成本
在 5 个长链复杂任务(包括 PDF/PPT 制作、SQL 副驾驶、实验分析报告撰写等)上的对比实验中:
| 指标 | Claude Code (53 工具) | GA (9 工具) | OpenClaw (18 工厂) |
|---|---|---|---|
| 任务成功率 | 100% | 100% | 80% |
| 总 Token 消耗 | 537,413 | 188,829 | 633,101 |
| 平均请求数 | 32.6 | 11.0 | 15.0 |
| 平均工具调用数 | 22.6 | 12.8 | 16.6 |
GA 在保持 100% 任务成功率的同时,Token 消耗仅为 Claude Code 的 35.1%、OpenClaw 的 29.8%。请求数从 32.6 降至 11.0,工具调用数从 22.6 降至 12.8。论文指出,这些结果表明 GA 的优势来自更低的上下文和工具流程开销,而非牺牲成功率。
这些数据直观地印证了第 7 章的核心论点:上下文信息密度的提升直接转化为效率的提升。当上下文中每个 token 都更"有用"时,模型需要更少的轮次就能做出正确决策。
9.5 故障升级:工具执行失败时的应对
在实际运行中,工具调用并不总是成功的——代码可能报错、文件可能不存在、网页可能加载失败。为了防止 Agent 陷入错误动作的无限循环,GA 引入了一个分阶段故障升级机制(Staged Escalation Mechanism)。
当任务执行失败时,GA 通过一个清晰的三步渐进恢复流程来处理:
- 局部修正:分析当前错误信息,做小幅定向调整后重试
- 策略切换:如果失败持续,放弃当前方案,强制切换到全新策略或搜索环境中缺失的信息
- 人类介入:如果所有自动化尝试均失败,暂停执行并请求人类干预
这个结构化设计防止了 Agent 盲目重复同样的错误。通过触发渐进增强的纠正动作,它确保 Agent 能够突破死胡同,使长期学习保持在正确的轨道上。
故障升级与工具最小化的关系在于:9 个原子工具的清晰边界(如
file_patch的快速失败、code_run的一轮一次)使得失败原因更容易诊断。当动作空间小且工具语义明确时,Agent 更容易定位问题并选择正确的恢复策略。
9.6 本章小结
本章深入分析了 GA 最小原子工具集的设计原理。核心要点:
- 工具膨胀在两个层面产生代价:提示词层面挤占上下文预算,策略层面增加决策复杂度。实验数据表明,大量工具中真正被使用的只是少数几个
- 工具选择遵循两个条件:原子性(每个工具是不可再分的原始能力)和组合泛化(复杂行为通过原子工具的序列组合涌现)
- 9 个原子工具覆盖五大能力类,形成完整的状态观测-动作执行-上下文保持-干预请求循环
code_run是万能原语,理论上可以完成所有任务;其余 8 个工具是降低决策成本的专用快捷方式(harness)- 实验验证:GA 在保持 100% 任务成功率的同时,Token 消耗仅为 Claude Code 的 35.1%
论文还指出了工具最小化的一个深层价值:由于保留的操作知识自然表达为少量通用原语的可复用组合序列,而非新的任务专用接口,工具最小化为后续的经验沉淀(experience consolidation)创造了有利条件。换句话说,工具越少、越通用,过去的经验就越容易被压缩为可复用的 SOP——这正是第 12 章"自我进化"机制得以高效运作的前提。
在下一章中,我们将深入 GA 的另一个核心机制——分层记忆架构。如果说工具集解决的是"Agent 能做什么"的问题,那么记忆系统解决的是一个更根本的问题:Agent 如何"记住"跨任务的经验,又不让过往记忆淹没当前决策?