第14章:注意力:该看哪?
文档摘要
第14章:注意力:该看哪? 兔狲教授的亲切开场 上一章,我们见证了LSTM与注意力的哲学较量——渐进式记忆与直接访问的智慧碰撞。今天,我们要深入探索注意力的核心:在这个嘈杂的世界里,该看哪? 注意力不仅是技术工具,更是智能的'眼睛'——它教会模型如何聚焦、如何选择、如何理解。让我们慢慢来,探索注意力的艺术。 核心议题:聚焦的艺术 “教授,”小小猪盯着屏幕上复杂的文本,“注意力机制让模型能够‘关注’不同部分,但这‘关注’具体是怎么实现的?模型怎么知道‘该看哪’?” 中山大学康乐园的冬日傍晚,夕阳透过玻璃窗洒进黑石屋书房,在红砖地上投下金色的光斑。窗外,几只晚归的鸟儿在榕树枝头跳跃,叽叽喳喳地讨论着一天的收获。书房里,功夫茶具上飘着淡淡的热气,墙上的挂钟滴答作响,记录着认知的每一次飞跃。
第14章:注意力:该看哪?
:::info
兔狲教授的亲切开场
上一章,我们见证了LSTM与注意力的哲学较量——渐进式记忆与直接访问的智慧碰撞。今天,我们要深入探索注意力的核心:在这个嘈杂的世界里,该看哪? 注意力不仅是技术工具,更是智能的'眼睛'——它教会模型如何聚焦、如何选择、如何理解。让我们慢慢来,探索注意力的艺术。
:::
核心议题:聚焦的艺术
“教授,”小小猪盯着屏幕上复杂的文本,“注意力机制让模型能够‘关注’不同部分,但这‘关注’具体是怎么实现的?模型怎么知道‘该看哪’?”
中山大学康乐园的冬日傍晚,夕阳透过玻璃窗洒进黑石屋书房,在红砖地上投下金色的光斑。窗外,几只晚归的鸟儿在榕树枝头跳跃,叽叽喳喳地讨论着一天的收获。书房里,功夫茶具上飘着淡淡的热气,墙上的挂钟滴答作响,记录着认知的每一次飞跃。
“这是个根本问题。在心理学中,威廉·詹姆斯在1890年就写道:‘注意力是心灵的聚光灯,在同时存在的多个对象或思路中,清晰而生动地把握其中一个。’”
兔狲教授轻轻放下茶杯,微笑道:“你们提出了注意力的本质问题。注意力不是被动接收,而是主动选择。今天,我们要探索这个‘选择’如何用数学实现。”
人类的注意力:认知的聚光灯
小小猪走到白板前,画了一个人阅读的场景。
“教授,当我阅读时,我的眼睛会跳着看——重点看名词、动词,跳过‘的’、‘了’这些词。这就是注意力的作用?”
小海豹补充道:“在认知科学中,注意力分为选择性注意力(选择关注什么)和分配性注意力(如何分配认知资源)。视觉注意力研究显示,我们会先看高对比度、移动的、突然出现的东西。”
兔狲教授点头:“是的,人类注意力有明确的优先级和选择性。现在,我们要让机器学会类似的智慧。”
他在白板上列出人类注意力的特点:
- 选择性:忽略无关信息,聚焦相关部分
- 动态性:根据任务需要调整关注点
- 有限性:不能同时关注所有事物
- 引导性:可以被意图、目标引导
“注意力的奇妙之处在于,”兔狲教授说,“它既是过滤器(过滤噪音),又是放大器(增强信号)。今天,我们要用数学实现这个过滤器与放大器。”
缩放点积注意力:数学的聚光灯
窗外天色渐暗,黑石屋里亮起了温暖的灯光。
“教授,”小小猪问,“上一章我们看到了注意力公式,但为什么要‘缩放’?为什么要‘点积’?”
兔狲教授走到白板前,写下缩放点积注意力的完整公式:
“让我们拆解这个公式,”他说,“Q (Query) 是‘我想知道什么’,K (Key) 是‘有什么信息’,V (Value) 是‘具体内容’。”
小小猪仔细观察公式:“QK^\top 计算当前查询与所有键的相似度?相似度高的键,对应的值就更重要?”
“正是,”兔狲教授赞许道,“点积 QK^\top 衡量查询与键的匹配程度。但这里有一个数学问题:当维度 d_k 较大时,点积的方差会变大。”
小海豹从数学书中抬起头:“方差变大……会导致softmax的梯度问题?”
“是的,”兔狲教授解释,“softmax函数对输入的大小敏感。如果点积的方差大,softmax的输出会趋近one-hot向量——某些位置接近1,其他接近0。这导致梯度很小,训练困难。”
他在白板上演示缩放的效果:
“除以 \sqrt{d_k} 将方差归一化为1,”兔狲教授说,“这个简单的缩放是注意力稳定训练的关键。”
softmax的温柔决策
兔狲教授在白板上画出softmax函数的曲线。
“softmax不仅是归一化工具,”他说,“它还实现了温和的注意力分配——不是非此即彼的硬选择,而是概率性的软分配。”
小小猪思考着:“softmax让注意力‘可以看多个地方,但重点看最相关的地方’?而不是‘只看一个地方’?”
“精辟的总结,”兔狲教授微笑,“softmax的指数函数放大差异——相似度高的获得更高权重,但其他位置仍有少量权重。这允许模型保持一定的‘注意力广度’。”
小海豹补充道:“这在认知上合理。人类注意力也有焦点和外围——我们聚焦于重要信息,但仍能感知背景。”
“是的,”兔狲教授说,“注意力权重矩阵 \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right) 就是模型的‘注意力地图’——它告诉我们模型在每个时刻‘看’哪里。”
正交计算图:看见注意力的聚焦
兔狲教授打开投影仪,一幅规整的计算图出现在屏幕上。

“这是注意力机制的正交计算图,”兔狲教授指着图说,“我们可以看到注意力如何从输入 X 逐步聚焦到输出 O。”
小小猪仔细观察图中的层级结构:“输入 X 通过三个权重矩阵变成 Q, K, V,然后计算注意力权重,最后加权输出?”
“是的,”兔狲教授解释,“这个图清晰地展示了注意力的信息流:”
- 特征提取层:W_Q, W_K, W_V 从输入中提取不同视角的特征
- 相关性计算层:QK^\top 计算所有位置对之间的相关性
- 注意力分配层:softmax将相关性转换为概率分布
- 信息整合层:注意力权重加权组合值向量 V
小海豹若有所思:“这个计算流程与人类注意力的认知过程惊人相似:提取特征→计算相关性→分配注意力→整合信息。”
“这正是注意力的魅力所在,”兔狲教授说,“简单的数学公式捕捉了复杂的认知过程。”
因果注意力的时间约束
兔狲教授在注意力矩阵上画了一个下三角。
“在序列任务中,”他说,“我们使用因果注意力(Causal Attention):位置 i 只能关注位置 j \leq i。”
他在白板上写出因果掩码:
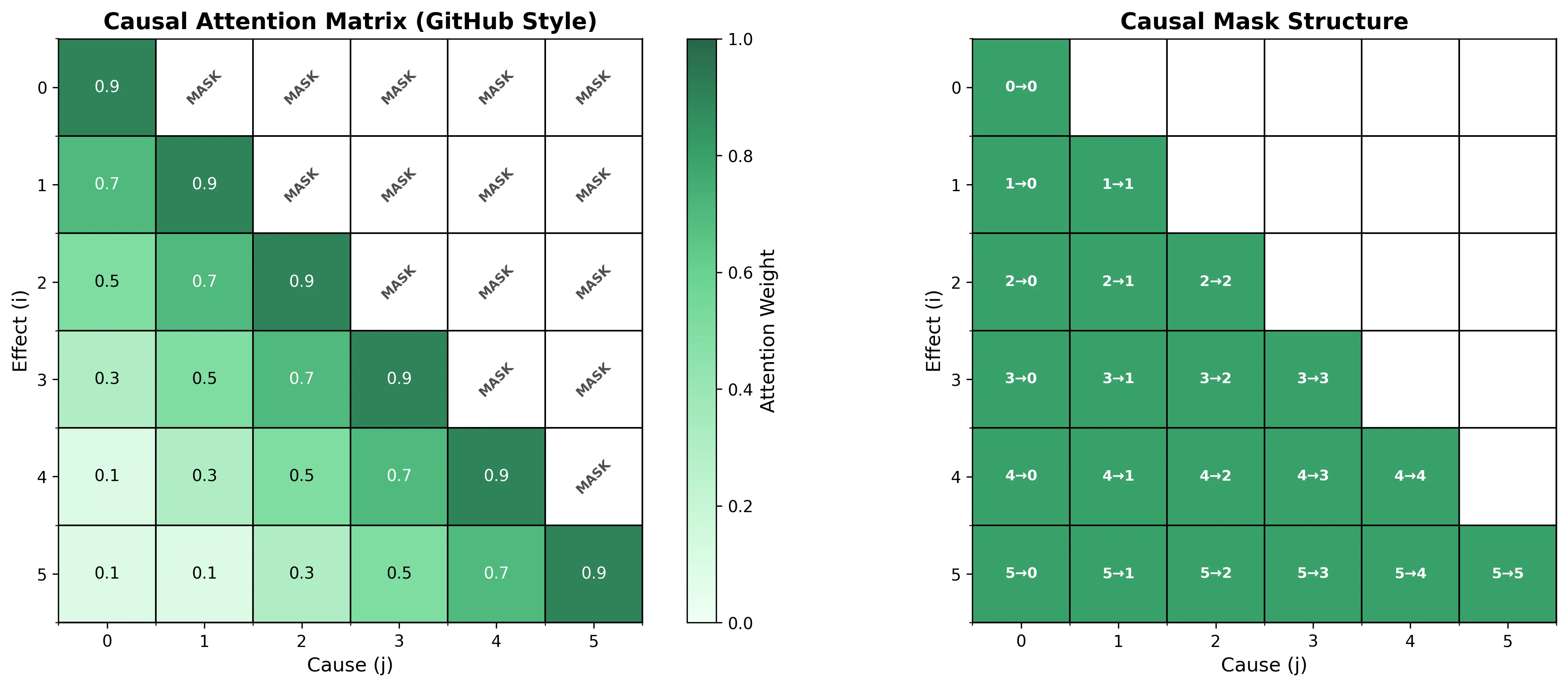
小小猪理解了这个设计:“这样保证了时间顺序?模型不能‘偷看’未来信息?”
“正是,”兔狲教授说,“因果注意力是自回归生成的基础——预测下一个词时,只能使用已经生成的词。”
小海豹思考着:“但这也意味着……早期位置的信息可能被后期位置忽略?因为后期位置有更多历史可看?”
“很好的观察,”兔狲教授说,“这引出了注意力的一个挑战:位置偏置。后期位置倾向于关注近期历史,可能忽略早期重要信息。我们需要机制来平衡这种偏置。”
多头注意力:多视角的智慧
窗外夜色渐深,珠江上的船灯如星星点点。
“教授,”小小猪问,“为什么需要‘多头’注意力?一个头不够吗?”
兔狲教授走到白板前,画了一个多视角观察的场景。
“想象你在观察一幅画,”他说,“你可以从颜色视角看,从形状视角看,从纹理视角看,从构图视角看。每个视角看到不同的模式。”
小海豹补充道:“在认知科学中,这称为多线索整合。我们通过多种感官、多种特征通道理解世界。”
兔狲教授点头:“多头注意力实现了类似的多视角处理。每个头学习不同的‘关注模式’。”
他在白板上写出多头注意力的公式:
其中:
小小猪认真看着公式:“所以每个头有自己的权重矩阵 W_i^Q, W_i^K, W_i^V,学习不同的变换?最后再合并?”
“是的,”兔狲教授说,“多头注意力的关键在于表征空间的分解。将高维空间分解为多个子空间,每个子空间关注不同特征。”
头的多样性:分工与合作
兔狲教授展示了一幅多头注意力权重的可视化图。
“在训练好的模型中,”他说,“不同头确实学会了不同的关注模式:”
- 语法头:关注语法结构(如主语-动词关系)
- 语义头:关注语义相关词
- 位置头:关注相对位置(如前一个词、后一个词)
- 罕见词头:特别关注罕见词或关键词
小海豹仔细观察可视化:“有些头关注局部(相邻词),有些头关注全局(远距离词)?这种分工很像大脑的不同区域?”
“很好的类比,”兔狲教授说,“多头注意力实现了功能专门化。不同头负责不同‘认知功能’,最后整合为统一理解。”
小小猪思考着:“但怎么确保头之间确实分工,而不是做同样的事?”
“这是通过随机初始化和训练压力实现的,”兔狲教授解释,“随机初始化让头从不同起点开始,训练目标(如语言建模)鼓励多样性——因为多样性有助于更好地预测下一个词。”
头的重要性分析
兔狲教授在白板上展示头重要性的研究结果。
“研究表明,”他说,“不同头对模型性能的贡献不同。有些头是‘关键头’——去掉它们性能大幅下降。有些头是‘冗余头’——去掉它们影响不大。”
他在白板上列出头的典型模式:
- 局部头:关注相邻词(窗口大小2-5)
- 全局头:关注整个序列
- 特定模式头:关注特定语法模式(如介词-名词)
- 填充头:关注填充符号(如句号、逗号)
“有趣的是,”兔狲教授说,“模型会自动学习这些模式,不需要我们显式指定。这体现了学习的能力——从数据中发现有用的关注模式。”
自注意力、交叉注意力与编码器-解码器注意力
窗外月光如水,洒在康乐园的红砖建筑上。
“教授,”小小猪问,“除了缩放点积注意力,还有哪些注意力变体?”
兔狲教授走到白板前,画出三种注意力架构。
“注意力有三种主要形式,”他说,“对应不同的应用场景:”
1. 自注意力(Self-Attention)
“自注意力中,Q, K, V 来自同一输入序列,”兔狲教授解释,“用于序列内部的关系建模。比如理解句子中词与词的关系。”
小小猪理解了这个设计:“自注意力让每个词‘看到’所有其他词,建立全局理解?”
“正是,”兔狲教授说,“自注意力是Transformer编码器的核心,它建立了序列的全局表示。”
2. 交叉注意力(Cross-Attention)
其中 Q 来自一个序列,K, V 来自另一个序列。
“交叉注意力用于序列间的关系建模,”兔狲教授解释,“比如机器翻译中,目标语言词(Q)关注源语言词(K, V)。”
小海豹补充道:“这模拟了翻译时的‘对齐’过程——找到目标词对应的源词。”
3. 编码器-解码器注意力
兔狲教授画出Transformer的完整架构。
“在标准的编码器-解码器Transformer中,”他说,“有三种注意力:”
- 编码器自注意力:源语言内部关系
- 解码器自注意力:目标语言内部关系(因果约束)
- 编码器-解码器注意力:源语言到目标语言的交叉注意力
“这种三层注意力结构,”兔狲教授总结,“实现了从局部到全局、从源到目标的完整信息流。”
思想模型:注意力作为认知架构
小海豹从书架取下一本认知架构著作,“教授,这让我想起ACT-R(自适应控制思维-理性)理论中的注意力机制。”
“很好的联系,”兔狲教授说,“注意力实现了认知架构的多个核心功能。”
他在白板上写下思想模型:
思想模型:注意力的四重认知功能
- 信息过滤(选择性):忽略无关信息,减少认知负荷
- 特征绑定(整合):将分散的特征组合为整体表示
- 关系发现(关联):发现元素之间的语义、语法关系
- 资源分配(优化):将有限计算资源分配给重要任务
“这四种功能,”兔狲教授解释,“对应着智能系统的核心需求。注意力不是附加功能,而是智能的必要组件。”
小小猪思考着:“所以注意力不仅是‘看哪’,更是‘如何理解’?它决定了信息如何被组织、如何被解释?”
“精辟的总结,”兔狲教授回答,“注意力塑造了表征的形成。通过选择关注什么、如何关注,模型构建了世界的心理表征。”
注意力与意识的连接
兔狲教授在白板上写下“意识”二字。
“在哲学和认知科学中,”他说,“注意力与意识有密切关系。威廉·詹姆斯说:‘意识看起来是在选择中进行。’”
小海豹若有所思:“注意力是意识的‘门户’?只有被注意的信息才能进入意识?”
“这是一个活跃的研究领域,”兔狲教授说,“在机器学习中,我们不需要解决意识难题。但注意力的确为模型提供了信息选择的能力——这是智能行为的基石。”
关键要点
:::info
兔狲教授的总结:注意力的艺术
- 选择性本质:注意力是信息选择的数学实现,通过softmax将相关性转换为概率分布,实现从“有什么”到“看什么”的认知跃迁
- 缩放点积的智慧:除以\sqrt{d_k}的简单缩放解决了高维点积的方差问题,体现了“细节决定成败”的工程洞察
- 多头分工哲学:多头注意力通过表征空间分解实现功能专门化,不同头学习不同关注模式,最后整合为统一理解
- 因果时间约束:因果注意力通过下三角掩码保证时间顺序性,是自回归生成的基础,体现“过去决定未来”的序列逻辑
- 认知功能映射:注意力实现了信息过滤、特征绑定、关系发现、资源分配四重认知功能,是智能系统的核心组件
:::
代码实践:完整注意力系统的Python实现
"让我们用Python代码实现完整的注意力系统,"兔狲教授说,"从基础注意力到多头注意力,再到实际应用。"
完整注意力模块实现
import numpy as np import matplotlib.pyplot as plt class AttentionModule: """完整的注意力模块(包含位置编码、掩码等)""" def __init__(self, d_model, num_heads, max_seq_len=512): """初始化注意力模块 参数: d_model: 模型维度 num_heads: 注意力头数量 max_seq_len: 最大序列长度(用于位置编码) """ assert d_model % num_heads == 0, "d_model必须能被num_heads整除" self.d_model = d_model self.num_heads = num_heads self.depth = d_model // num_heads self.max_seq_len = max_seq_len # 注意力权重 self.W_q = np.random.randn(d_model, d_model) * 0.01 self.W_k = np.random.randn(d_model, d_model) * 0.01 self.W_v = np.random.randn(d_model, d_model) * 0.01 self.W_o = np.random.randn(d_model, d_model) * 0.01 # 位置编码(正弦余弦) self.positional_encoding = self.create_positional_encoding(max_seq_len, d_model) def create_positional_encoding(self, max_seq_len, d_model): """创建正弦余弦位置编码""" positional_encoding = np.zeros((max_seq_len, d_model)) for pos in range(max_seq_len): for i in range(0, d_model, 2): # 正弦波 positional_encoding[pos, i] = np.sin(pos / (10000 ** (2 * i / d_model))) # 余弦波 if i + 1 < d_model: positional_encoding[pos, i + 1] = np.cos(pos / (10000 ** (2 * i / d_model))) return positional_encoding def scaled_dot_product_attention(self, Q, K, V, mask=None): """缩放点积注意力""" d_k = K.shape[-1] scores = np.matmul(Q, K.transpose(0, 1, 3, 2)) # 调整维度顺序 # 缩放 scores = scores / np.sqrt(d_k) # 应用掩码 if mask is not None: scores = scores + (mask * -1e9) # softmax attention_weights = self.softmax(scores, axis=-1) # 加权输出 output = np.matmul(attention_weights, V) return output, attention_weights def softmax(self, x, axis=-1): """稳定的softmax实现""" x_exp = np.exp(x - np.max(x, axis=axis, keepdims=True)) return x_exp / np.sum(x_exp, axis=axis, keepdims=True) def split_heads(self, x, batch_size): """分割多头""" x = x.reshape(batch_size, -1, self.num_heads, self.depth) return x.transpose(0, 2, 1, 3) # (batch_size, num_heads, seq_len, depth) def combine_heads(self, x, batch_size): """合并多头""" x = x.transpose(0, 2, 1, 3) # (batch_size, seq_len, num_heads, depth) return x.reshape(batch_size, -1, self.d_model) def forward(self, x, mask=None, use_positional_encoding=True): """前向传播 参数: x: 输入序列 (batch_size, seq_len, d_model) mask: 注意力掩码 use_positional_encoding: 是否使用位置编码 """ batch_size, seq_len, _ = x.shape # 添加位置编码 if use_positional_encoding and seq_len <= self.max_seq_len: x = x + self.positional_encoding[:seq_len] # 线性变换 Q = np.matmul(x, self.W_q) # (batch_size, seq_len, d_model) K = np.matmul(x, self.W_k) V = np.matmul(x, self.W_v) # 分割多头 Q = self.split_heads(Q, batch_size) # (batch_size, num_heads, seq_len, depth) K = self.split_heads(K, batch_size) V = self.split_heads(V, batch_size) # 缩放点积注意力 scaled_attention, attention_weights = self.scaled_dot_product_attention(Q, K, V, mask) # 合并多头 scaled_attention = self.combine_heads(scaled_attention, batch_size) # (batch_size, seq_len, d_model) # 输出线性变换 output = np.matmul(scaled_attention, self.W_o) # (batch_size, seq_len, d_model) return output, attention_weights def create_causal_mask(self, seq_len): """创建因果注意力掩码""" mask = np.triu(np.ones((seq_len, seq_len)), k=1) # 上三角为1 return mask # 1的位置需要被掩码 def create_padding_mask(self, sequences, pad_token_id=0): """创建填充掩码(用于处理变长序列)""" mask = (sequences == pad_token_id).astype(float) return mask[:, np.newaxis, np.newaxis, :] # 广播到注意力分数形状 # 完整注意力模块演示 print("完整注意力模块演示:") print("=" * 60) # 创建注意力模块 d_model = 64 num_heads = 8 attention_module = AttentionModule(d_model=d_model, num_heads=num_heads, max_seq_len=100) print(f"注意力模块配置:") print(f" 模型维度 (d_model): {d_model}") print(f" 头数量 (num_heads): {num_heads}") print(f" 每个头维度 (depth): {d_model // num_heads}") print(f" 最大序列长度: {attention_module.max_seq_len}") print(f" 位置编码形状: {attention_module.positional_encoding.shape}") # 测试数据 batch_size = 2 seq_len = 20 x_input = np.random.randn(batch_size, seq_len, d_model) print(f"\n输入数据形状: {x_input.shape}") # 无掩码注意力 output_no_mask, attn_weights_no_mask = attention_module.forward( x_input, mask=None, use_positional_encoding=True ) print(f"无掩码输出形状: {output_no_mask.shape}") print(f"注意力权重形状: {attn_weights_no_mask.shape}") # 因果掩码注意力 causal_mask = attention_module.create_causal_mask(seq_len) output_causal, attn_weights_causal = attention_module.forward( x_input, mask=causal_mask, use_positional_encoding=True ) print(f"\n因果掩码输出形状: {output_causal.shape}") # 可视化位置编码 def visualize_positional_encoding(pe, title="位置编码"): """可视化位置编码""" fig, axes = plt.subplots(1, 2, figsize=(14, 6)) # 热图 im1 = axes[0].imshow(pe[:50, :].T, cmap='RdBu', aspect='auto') axes[0].set_xlabel('位置 (pos)') axes[0].set_ylabel('维度 (i)') axes[0].set_title(f'{title} - 热图 (前50个位置)') plt.colorbar(im1, ax=axes[0]) # 正弦波可视化 axes[1].plot(pe[:100, 0], label='维度 0 (sin)', linewidth=2) axes[1].plot(pe[:100, 1], label='维度 1 (cos)', linewidth=2) axes[1].plot(pe[:100, 2], label='维度 2 (sin)', linewidth=2) axes[1].plot(pe[:100, 3], label='维度 3 (cos)', linewidth=2) axes[1].set_xlabel('位置 (pos)') axes[1].set_ylabel('编码值') axes[1].set_title(f'{title} - 正弦余弦波') axes[1].legend() axes[1].grid(True, alpha=0.3) plt.tight_layout() plt.savefig(f'/tmp/{title.lower().replace(" ", "_")}.png', dpi=150, bbox_inches='tight') plt.close() print(f"{title}可视化已保存到 /tmp/{title.lower().replace(' ', '_')}.png") # 运行可视化 visualize_positional_encoding(attention_module.positional_encoding, "正弦余弦位置编码") # 分析位置编码的特性 print("\n位置编码特性分析:") print("=" * 60) pe = attention_module.positional_encoding print(f"位置编码形状: {pe.shape}") print(f"位置编码范围: [{pe.min():.3f}, {pe.max():.3f}]") print(f"位置编码均值: {pe.mean():.6f} (接近0)") print(f"位置编码标准差: {pe.std():.6f}") # 检查位置编码的唯一性 pos1 = pe[10] # 位置10的编码 pos2 = pe[20] # 位置20的编码 pos3 = pe[30] # 位置30的编码 similarity_12 = np.dot(pos1, pos2) / (np.linalg.norm(pos1) * np.linalg.norm(pos2)) similarity_13 = np.dot(pos1, pos3) / (np.linalg.norm(pos1) * np.linalg.norm(pos3)) similarity_23 = np.dot(pos2, pos3) / (np.linalg.norm(pos2) * np.linalg.norm(pos3)) print(f"\n位置编码相似度:") print(f" 位置10与位置20: {similarity_12:.4f}") print(f" 位置10与位置30: {similarity_13:.4f}") print(f" 位置20与位置30: {similarity_23:.4f}") print(f" 解释: 相似度应随位置距离增加而减小")
注意力模式分析工具
class AttentionAnalyzer: """注意力模式分析工具""" def __init__(self): pass def analyze_attention_patterns(self, attention_weights, sequence=None, sample_idx=0): """分析注意力模式""" batch_size, num_heads, seq_len_q, seq_len_k = attention_weights.shape print(f"注意力模式分析 (样本{sample_idx}):") print("=" * 60) print(f" 批次大小: {batch_size}") print(f" 头数量: {num_heads}") print(f" 查询序列长度: {seq_len_q}") print(f" 键序列长度: {seq_len_k}") # 分析每个头的注意力模式 head_patterns = [] for h in range(num_heads): head_weights = attention_weights[sample_idx, h] # 计算注意力分布的统计量 entropy = self.compute_attention_entropy(head_weights) concentration = self.compute_attention_concentration(head_weights) diagonal_strength = self.compute_diagonal_strength(head_weights) local_focus = self.compute_local_focus(head_weights, window_size=3) pattern_type = self.classify_attention_pattern( entropy, concentration, diagonal_strength, local_focus ) head_patterns.append({ 'head_idx': h, 'entropy': entropy, 'concentration': concentration, 'diagonal_strength': diagonal_strength, 'local_focus': local_focus, 'pattern_type': pattern_type }) # 打印分析结果 print(f"\n注意力头模式分类:") pattern_counts = {} for pattern in head_patterns: ptype = pattern['pattern_type'] pattern_counts[ptype] = pattern_counts.get(ptype, 0) + 1 if h < 5: # 只打印前5个头 print(f" 头 {pattern['head_idx']}: {ptype:15s} " f"熵={pattern['entropy']:.3f} 集中度={pattern['concentration']:.3f}") print(f"\n模式分布:") for ptype, count in pattern_counts.items(): print(f" {ptype:15s}: {count}个头 ({count/num_heads*100:.1f}%)") # 可视化典型模式 self.visualize_typical_patterns(attention_weights[sample_idx], head_patterns, sequence) return head_patterns def compute_attention_entropy(self, attention_matrix): """计算注意力分布的熵(衡量分散程度)""" # 对每一行计算熵,然后平均 entropies = [] for i in range(attention_matrix.shape[0]): row = attention_matrix[i] # 避免log(0) row = np.clip(row, 1e-10, 1.0) entropy = -np.sum(row * np.log(row)) entropies.append(entropy) return np.mean(entropies) def compute_attention_concentration(self, attention_matrix): """计算注意力集中度(最大权重的平均值)""" max_weights = np.max(attention_matrix, axis=1) return np.mean(max_weights) def compute_diagonal_strength(self, attention_matrix): """计算对角线强度(关注自身的程度)""" seq_len = min(attention_matrix.shape[0], attention_matrix.shape[1]) diagonal_weights = [attention_matrix[i, i] for i in range(seq_len)] return np.mean(diagonal_weights) def compute_local_focus(self, attention_matrix, window_size=3): """计算局部关注度(关注附近位置的程度)""" seq_len = attention_matrix.shape[0] local_weights = [] for i in range(seq_len): # 定义局部窗口 start = max(0, i - window_size) end = min(seq_len, i + window_size + 1) # 计算窗口内的注意力权重 window_weight = np.sum(attention_matrix[i, start:end]) local_weights.append(window_weight) return np.mean(local_weights) def classify_attention_pattern(self, entropy, concentration, diagonal_strength, local_focus): """分类注意力模式""" if diagonal_strength > 0.7: return "自我关注" elif local_focus > 0.8: return "局部关注" elif concentration > 0.5 and entropy < 1.0: return "集中关注" elif entropy > 2.0: return "分散关注" else: return "混合模式" def visualize_typical_patterns(self, attention_weights, head_patterns, sequence=None, max_heads=6): """可视化典型注意力模式""" num_heads = attention_weights.shape[0] # 选择不同模式的头 selected_heads = [] pattern_seen = set() for pattern in head_patterns: ptype = pattern['pattern_type'] if ptype not in pattern_seen and len(selected_heads) < max_heads: selected_heads.append(pattern['head_idx']) pattern_seen.add(ptype) # 如果不够,补充其他头 if len(selected_heads) < max_heads: for pattern in head_patterns: if pattern['head_idx'] not in selected_heads and len(selected_heads) < max_heads: selected_heads.append(pattern['head_idx']) # 可视化 fig, axes = plt.subplots(2, 3, figsize=(15, 10)) axes = axes.flatten() for idx, head_idx in enumerate(selected_heads[:6]): ax = axes[idx] head_weights = attention_weights[head_idx] im = ax.imshow(head_weights, cmap='viridis', aspect='auto', vmin=0, vmax=1) # 添加文本标签(如果有序列) if sequence is not None and len(sequence) <= 20: ax.set_xticks(range(len(sequence))) ax.set_yticks(range(len(sequence))) ax.set_xticklabels(sequence, rotation=45, fontsize=8) ax.set_yticklabels(sequence, fontsize=8) ax.set_xlabel('键位置') ax.set_ylabel('查询位置') # 获取该头的模式信息 pattern_info = next(p for p in head_patterns if p['head_idx'] == head_idx) pattern_type = pattern_info['pattern_type'] ax.set_title(f'头 {head_idx}: {pattern_type}\n' f'熵={pattern_info["entropy"]:.2f} 集中度={pattern_info["concentration"]:.2f}') ax.grid(True, which='both', color='white', linewidth=0.5, alpha=0.3) # 添加颜色条 plt.colorbar(im, ax=ax, fraction=0.046, pad=0.04) # 隐藏多余的子图 for idx in range(len(selected_heads), 6): axes[idx].axis('off') plt.suptitle('多头注意力典型模式分析', fontsize=14) plt.tight_layout() plt.savefig('/tmp/attention_patterns_analysis.png', dpi=150, bbox_inches='tight') plt.close() print(f"注意力模式分析图已保存到 /tmp/attention_patterns_analysis.png") # 运行注意力分析 print("\n注意力模式分析演示:") print("=" * 60) # 创建分析器 analyzer = AttentionAnalyzer() # 分析无掩码注意力 print("分析无掩码注意力模式:") head_patterns_no_mask = analyzer.analyze_attention_patterns( attn_weights_no_mask, sample_idx=0, sequence=[f"w{i}" for i in range(min(20, seq_len))] ) # 分析因果注意力 print("\n分析因果注意力模式:") head_patterns_causal = analyzer.analyze_attention_patterns( attn_weights_causal, sample_idx=0, sequence=[f"w{i}" for i in range(min(20, seq_len))] ) # 比较两种掩码的影响 print("\n掩码对注意力模式的影响比较:") print("=" * 60) # 选择相同的头进行比较 head_idx = 0 # 比较第一个头 no_mask_pattern = head_patterns_no_mask[head_idx] causal_pattern = head_patterns_causal[head_idx] print(f"头 {head_idx} 的模式变化:") print(f" 模式: {no_mask_pattern['pattern_type']} → {causal_pattern['pattern_type']}") print(f" 熵: {no_mask_pattern['entropy']:.3f} → {causal_pattern['entropy']:.3f} " f"(变化: {causal_pattern['entropy'] - no_mask_pattern['entropy']:+.3f})") print(f" 集中度: {no_mask_pattern['concentration']:.3f} → {causal_pattern['concentration']:.3f} " f"(变化: {causal_pattern['concentration'] - no_mask_pattern['concentration']:+.3f})") print(f" 对角线强度: {no_mask_pattern['diagonal_strength']:.3f} → {causal_pattern['diagonal_strength']:.3f}") print(f" 局部关注: {no_mask_pattern['local_focus']:.3f} → {causal_pattern['local_focus']:.3f}") print(f"\n因果掩码的预期效果:") print(f" 1. 减少熵(注意力更集中,因为未来位置被掩码)") print(f" 2. 增加对角线强度(更多自我关注,因为没有未来可看)") print(f" 3. 增加局部关注(被迫更多关注近期历史)")
注意力在实际任务中的应用
def attention_in_text_classification(): """注意力在文本分类中的应用演示""" # 模拟文本分类任务 class TextClassifierWithAttention: """带注意力的文本分类器""" def __init__(self, vocab_size, embedding_dim, d_model, num_heads, num_classes): """初始化分类器""" # 词嵌入层 self.embedding = np.random.randn(vocab_size, embedding_dim) * 0.01 # 注意力层 self.attention = AttentionModule(d_model=d_model, num_heads=num_heads) # 分类层 self.W_classify = np.random.randn(d_model, num_classes) * 0.01 self.b_classify = np.zeros((1, num_classes)) self.d_model = d_model self.embedding_dim = embedding_dim # 投影层(如果需要调整维度) if embedding_dim != d_model: self.W_proj = np.random.randn(embedding_dim, d_model) * 0.01 else: self.W_proj = None def forward(self, token_ids, attention_mask=None): """前向传播""" batch_size, seq_len = token_ids.shape # 词嵌入 embedded = np.zeros((batch_size, seq_len, self.embedding_dim)) for b in range(batch_size): for t in range(seq_len): token_id = token_ids[b, t] embedded[b, t] = self.embedding[token_id] # 投影到d_model维度(如果需要) if self.W_proj is not None: embedded = np.matmul(embedded, self.W_proj) # 注意力层 if attention_mask is not None: # 将attention_mask转换为注意力掩码格式 attn_mask = attention_mask[:, np.newaxis, np.newaxis, :] attn_mask = (1 - attn_mask) * -1e9 # 填充位置设为负无穷 else: attn_mask = None attended, attention_weights = self.attention.forward( embedded, mask=attn_mask, use_positional_encoding=True ) # 池化(使用注意力加权平均) # 计算序列重要性权重 importance_weights = self.compute_importance_weights(attended) # 加权平均池化 pooled = np.sum(attended * importance_weights[:, :, np.newaxis], axis=1) # 分类 logits = np.matmul(pooled, self.W_classify) + self.b_classify return logits, attention_weights, importance_weights def compute_importance_weights(self, attended): """计算序列中每个位置的重要性权重""" # 简单方法:使用最后一个线性层的前向传播 # 更复杂的方法:使用单独的注意力层 batch_size, seq_len, d_model = attended.shape # 使用简单的线性变换+softmax W_importance = np.random.randn(d_model, 1) * 0.01 importance_scores = np.matmul(attended, W_importance) # (batch_size, seq_len, 1) importance_scores = importance_scores.reshape(batch_size, seq_len) # softmax归一化 exp_scores = np.exp(importance_scores - np.max(importance_scores, axis=1, keepdims=True)) importance_weights = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) return importance_weights print("注意力在文本分类中的应用演示:") print("=" * 60) # 模拟数据 vocab_size = 1000 embedding_dim = 128 d_model = 64 num_heads = 4 num_classes = 3 # 创建分类器 classifier = TextClassifierWithAttention( vocab_size=vocab_size, embedding_dim=embedding_dim, d_model=d_model, num_heads=num_heads, num_classes=num_classes ) print(f"分类器配置:") print(f" 词汇表大小: {vocab_size}") print(f" 嵌入维度: {embedding_dim}") print(f" 模型维度: {d_model}") print(f" 注意力头数: {num_heads}") print(f" 类别数: {num_classes}") # 模拟输入 batch_size = 4 seq_len = 25 # 生成随机token IDs(模拟文本) token_ids = np.random.randint(0, vocab_size-10, (batch_size, seq_len)) # 创建注意力掩码(模拟填充) attention_mask = np.ones((batch_size, seq_len)) for b in range(batch_size): # 随机设置一些填充位置 pad_start = np.random.randint(seq_len-5, seq_len) attention_mask[b, pad_start:] = 0 print(f"\n输入数据:") print(f" token_ids形状: {token_ids.shape}") print(f" attention_mask形状: {attention_mask.shape}") print(f" 有效token比例: {attention_mask.sum() / attention_mask.size:.1%}") # 前向传播 logits, attn_weights, importance_weights = classifier.forward(token_ids, attention_mask) print(f"\n输出结果:") print(f" logits形状: {logits.shape}") print(f" 注意力权重形状: {attn_weights.shape}") print(f" 重要性权重形状: {importance_weights.shape}") # 可视化重要性权重 sample_idx = 0 plt.figure(figsize=(12, 4)) # 子图1:注意力权重(第一个头) plt.subplot(1, 2, 1) im1 = plt.imshow(attn_weights[sample_idx, 0], cmap='viridis', aspect='auto') plt.colorbar(im1, label='注意力权重') plt.xlabel('键位置') plt.ylabel('查询位置') plt.title(f'注意力权重 - 头 0 (样本{sample_idx})') # 添加有效token边界 valid_len = int(attention_mask[sample_idx].sum()) plt.axvline(x=valid_len-0.5, color='red', linestyle='--', linewidth=2, label='有效token边界') plt.axhline(y=valid_len-0.5, color='red', linestyle='--', linewidth=2) plt.legend() # 子图2:重要性权重 plt.subplot(1, 2, 2) positions = range(seq_len) plt.bar(positions, importance_weights[sample_idx], alpha=0.7) plt.axvline(x=valid_len-0.5, color='red', linestyle='--', linewidth=2, label='有效token边界') plt.xlabel('位置') plt.ylabel('重要性权重') plt.title(f'序列重要性权重 (样本{sample_idx})') plt.legend() plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig('/tmp/attention_text_classification.png', dpi=150, bbox_inches='tight') plt.close() print(f"\n文本分类注意力可视化已保存到 /tmp/attention_text_classification.png") # 分析注意力与重要性的关系 print(f"\n注意力与重要性分析:") print("=" * 60) # 计算注意力权重与重要性权重的相关性 attention_matrix = attn_weights[sample_idx, 0] # 第一个头 importance_vector = importance_weights[sample_idx] # 计算每个查询位置的平均注意力与重要性 avg_attention_per_query = np.mean(attention_matrix, axis=1) # 平均每个查询位置的注意力分配 # 计算相关性 correlation = np.corrcoef(avg_attention_per_query[:valid_len], importance_vector[:valid_len])[0, 1] print(f" 有效序列长度: {valid_len}") print(f" 注意力分散度(熵): {analyzer.compute_attention_entropy(attention_matrix[:valid_len, :valid_len]):.3f}") print(f" 重要性权重分散度(熵): {analyzer.compute_attention_entropy(importance_vector[:valid_len].reshape(1, -1)):.3f}") print(f" 注意力与重要性相关性: {correlation:.3f}") print(f"\n解释:") print(f" 相关性接近1: 模型关注的位置也正是它认为重要的位置") print(f" 相关性接近0: 注意力与重要性判断无关") print(f" 实际期望: 适度的正相关,表示一定的一致性") # 运行文本分类演示 attention_in_text_classification()
"记住,"兔狲教授总结道,"注意力是智能的眼睛——它教会模型如何看世界、如何选择信息、如何建立关系。从缩放点积的数学优雅,到多头分工的认知智慧,注意力机制展示了简单原则如何涌现复杂能力。最重要的是,注意力提醒我们:智能不是被动接收,而是主动构建;理解不是复制世界,而是创造意义。在这条路上,选择比接收更重要,关系比元素更有价值。"
兔狲教授的思考题
实践探索(适合小小猪)
- 注意力变体实现:实现不同的注意力变体(如线性注意力、稀疏注意力、局部注意力)。比较它们的计算复杂度与效果?
- 注意力可视化工具:开发一个交互式注意力可视化工具,可以上传文本、查看注意力权重、分析关注模式。
- 注意力蒸馏实验:训练一个大模型,然后用注意力蒸馏训练一个小模型。小模型能学会大模型的注意力模式吗?
历史探究(适合小海豹)
- 注意力机制的跨学科起源:研究注意力在心理学、神经科学、计算机视觉中的发展历史。这些领域如何相互影响?
- Transformer革命的社会影响:调查Transformer架构如何改变AI研究生态。从论文发表、开源项目到工业应用的全链条影响。
- 注意力与神经科学验证:研究是否有神经科学证据支持大脑使用类似注意力的机制?fMRI、EEG研究发现了什么?
综合思考
- 哲学反思:注意力机制的"选择性"是否隐含了一种认识论立场——知识不是客观反映,而是主动建构?
- 伦理挑战:注意力机制让模型能够"聚焦"某些信息,这可能导致放大偏见。如何设计"公平注意力"?
- 创造练习:设计一个"元注意力"机制,让模型学习如何调整自己的注意力策略。你会如何设计奖励函数?
- 极限挑战:证明注意力机制可以近似任何序列到序列的函数(通用近似定理)。需要什么条件?
下一步预告
茶香在黑石屋中弥漫,夜深人静。
"今天我们深入探索了注意力的艺术,"兔狲教授说,"看到了注意力如何成为模型的'眼睛'。但单有眼睛还不够——如何组织这些眼睛,形成完整的'视觉系统'?"
小小猪好奇地问:"组织眼睛?就像……多个注意力层堆叠起来?"
"是的,"兔狲教授解释,"下一章,我们要探索编码-解码堆栈。理解Transformer如何通过多层注意力与前馈网络,构建强大的序列到序列模型。"
小海豹翻动着笔记本,"这引出了现代AI的核心架构。历史上,编码器-解码器结构如何从简单的Seq2Seq演进到Transformer?"
兔狲教授微笑:"我们慢慢来,下一章见。"
小小猪的笔记:我实现了完整的注意力模块,包括位置编码、多头注意力、因果掩码。最有趣的是位置编码——正弦余弦波确实为每个位置提供了唯一标识!可视化显示,不同头确实关注不同模式:有的关注局部,有的关注语法结构,有的关注关键词。注意力真的是模型的"眼睛"。
小海豹的笔记:研究了注意力的历史,震撼于它的简洁与强大。2017年的Transformer论文只有8页,却改变了AI领域。最深刻的是位置编码的设计——用正弦余弦函数编码绝对位置,同时能计算相对位置。数学的简洁之美。
兔狲教授的结语:注意力教给我们关于智能设计的根本一课:感知始于选择,理解始于关系。在这个机制中,我们看到了数学与认知的完美结合——简单的点积与softmax,实现了复杂的选择与整合。最重要的是,它提醒我们:好的设计往往源于对问题本质的洞察,而不是技术的堆砌。在这条路上,洞察比技巧更重要,理解比记忆更有价值。我们慢慢来,理解了最重要。