第3章:从符号到向量——表示空间的第一次解放
文档摘要
第3章:从符号到向量——表示空间的第一次解放 把”国王”减去”男人”加上”女人”,你得到”女王”。这是推理还是算术? 一、那句话 2013 年,Tomas Mikolov 在一篇论文里写下了一个方程,后来这个方程被引用的频率,大概超过了那个时代任何一篇 NLP 论文: $$ \vec{\text{King}} - \vec{\text{Man}} + \vec{\text{Woman}} \approx \vec{\text{Queen}} $$ 意思是:如果你把”国王”的词向量减去”男人”的词向量,再加上”女人”的词向量,最近邻的词向量是”女王”。 这不是一个被精心设计出来的例子——这是实验跑出来的结果。算法学会了这个关系,没有人告诉它”国王之于男人,犹如女王之于女人”。
第3章:从符号到向量——表示空间的第一次解放
把”国王”减去”男人”加上”女人”,你得到”女王”。这是推理还是算术?
一、那句话
2013 年,Tomas Mikolov 在一篇论文里写下了一个方程,后来这个方程被引用的频率,大概超过了那个时代任何一篇 NLP 论文:
意思是:如果你把”国王”的词向量减去”男人”的词向量,再加上”女人”的词向量,最近邻的词向量是”女王”。
这不是一个被精心设计出来的例子——这是实验跑出来的结果。算法学会了这个关系,没有人告诉它”国王之于男人,犹如女王之于女人”。
这一刻,AI 研究界集体倒吸了一口气。
为什么?因为这看起来像是机器在做类比推理。不是规则推理,不是逻辑演绎,而是更接近人类直觉的那种东西:抓住了关系的本质,然后把它迁移到新的对象上。
然后问题来了:它真的在推理吗?
这一章讲的就是这件事——什么是向量表示,它为什么比符号更强大,以及它的力量从哪里来,又止步于哪里。
二、符号的问题,重说一遍
在上一章,我们看到符号 AI 的核心困境:知识必须被显式地写出来,而世界的知识写不完。
但还有另一个问题我没有强调,那就是符号的语义是外挂的。
在专家系统里,"是哺乳动物" 这个字符串,对机器来说只是一个 token——一个无法进一步分解的原子。它不知道”哺乳动物”和”动物”的关系,不知道”哺乳动物”和”爬行动物”有多近,不知道”猫”比”鲸鱼”更像是一个典型的哺乳动物。
所有这些关系,都需要被显式地写进规则。
IF 是哺乳动物 THEN 是动物 [R_base_1] IF 是哺乳动物 AND 不是鲸类 THEN 通常有腿 [R_mammal_legs]
每一种关系,都要对应一条规则。而关系是无限的,规则写不完。
这个问题的根源在于:符号系统用离散的 token 表示概念,而概念之间的关系是连续的、是有程度的、是嵌套的。“猫”和”狗”之间的距离,不能被离散的 If-Then 规则捕获——你只能说”猫是哺乳动物,狗是哺乳动物”,但你说不出”猫比蛇更接近狗”。
向量表示解决了这个问题。不是完全解决,但解决了核心的部分。
三、分布假设:意义藏在邻居里
向量表示的思想,最早可以追溯到语言学家 J.R. Firth 在 1957 年说的一句话:
“你可以通过它交往的朋友来认识一个词。”(You shall know a word by the company it keeps.)
这个直觉,叫做分布假设(Distributional Hypothesis):词的意义,由它在语料库里的上下文分布所决定。
出现在相似上下文里的词,意义相近。“猫”和”狗”都频繁出现在”我养了一只___“、”给它喂食”、“它叫了”这样的上下文里,所以它们在语义上是近邻。
这个直觉可以被机械化。你建立一个矩阵,行是词,列是上下文词(或文档),每个格子记录共现次数(或其变换)。然后,每一行就是那个词的一个向量表示。意义相近的词,对应的向量就在高维空间里彼此接近。
这是向量表示的原始版本,叫做分布语义模型(Distributional Semantic Models,DSM),从 1990 年代开始就有了。它有效,但有两个问题:维度太高(可能有几十万维),向量非常稀疏(大多数格子是零)。
:::details 分布语义模型(DSM):词义藏在共现矩阵里
分布语义模型是一类把词意义表示为向量的方法,核心思路是:建一张"词×上下文"的大表,记录每个词和哪些词经常一起出现,然后把这张表的每一行当作该词的向量。
- 高维:如果语料里有 10 万个不同的词,矩阵就有 10 万列,每个词的向量就是 10 万维的——非常长
- 稀疏:大多数词对很少或从不共现,所以矩阵里大部分是 0,存储极浪费
Word2Vec(Mikolov 2013)解决了这个问题:不直接建矩阵,而是训练神经网络来隐式地压缩这种共现信息到 100-300 维的稠密向量里。
:::
Mikolov 2013 年的论文,做的是一件更激进的事。
四、Word2Vec:用预测来压缩语义
Word2Vec 不构建共现矩阵。它训练一个神经网络,任务是:给定一个词,预测它的上下文词(Skip-gram),或者给定上下文词,预测中心词(CBOW)。
:::details Skip-gram 和 CBOW:Word2Vec 的两种训练方式
Word2Vec 有两个变体,区别在于预测任务的方向:
- Skip-gram:输入中心词,预测它周围的词。例如句子"我喜欢吃苹果",输入"吃",预测"喜欢""苹果"。适合小数据集,对低频词效果更好。
- CBOW(Continuous Bag of Words):输入周围词,预测中心词。输入"喜欢""苹果",预测"吃"。训练速度更快,适合大数据集。
两种方式都只是手段,真正的目标是学到词的向量表示(嵌入)。训练完成后,预测头被丢弃,只保留词嵌入矩阵。
:::
这听起来很平凡。但副产品是重点。
当你训练这个网络时,你把每个词映射到一个低维向量(通常是 100 到 300 维)。为了让预测任务完成得好,这些向量必须编码词的某种本质——因为只有理解了词与词之间的关系,才能准确预测哪些词会共同出现。
网络训练完成之后,你扔掉预测头,只保留词嵌入矩阵。这就是你的词向量。
这里有一个深刻的事情值得停一下想:
你没有教网络”国王”和”女王”的关系。你没有告诉它任何语义规则。你只是让它预测文本序列。然后,在它学会预测之后,你发现”国王-男人+女人≈女王”这样的关系自发地涌现了。
为什么会这样?因为在自然语言里,“国王”出现的地方,“女王”也会以某种平行的方式出现——只是出现在相应的女性语境里。网络为了预测准确,必须把这种平行关系编码进向量里。“皇室”是一个语境轴,“性别”是另一个语境轴。这两个轴在向量空间里对应两个方向。减去”男人”的向量,再加上”女人”的向量,就是在性别轴上做了一次移位。
语义,从分布中涌现了。
五、几何中的浅层逻辑
让我们更仔细地看这个类比等式。
国王 - 男人 + 女人 ≈ 女王 巴黎 - 法国 + 日本 ≈ 东京 走 - 走 + 游泳 ≈ 游泳 (或者:walk - walked + swam ≈ swim,过去式关系也被编码了)
每一个类比,都对应向量空间里的一次平移。“男人→女王”和”国王→女王”之间的差,是一个固定的向量方向,代表”性别维度上的移动”。
这是一种非常干净的几何结构。语义关系,变成了方向。
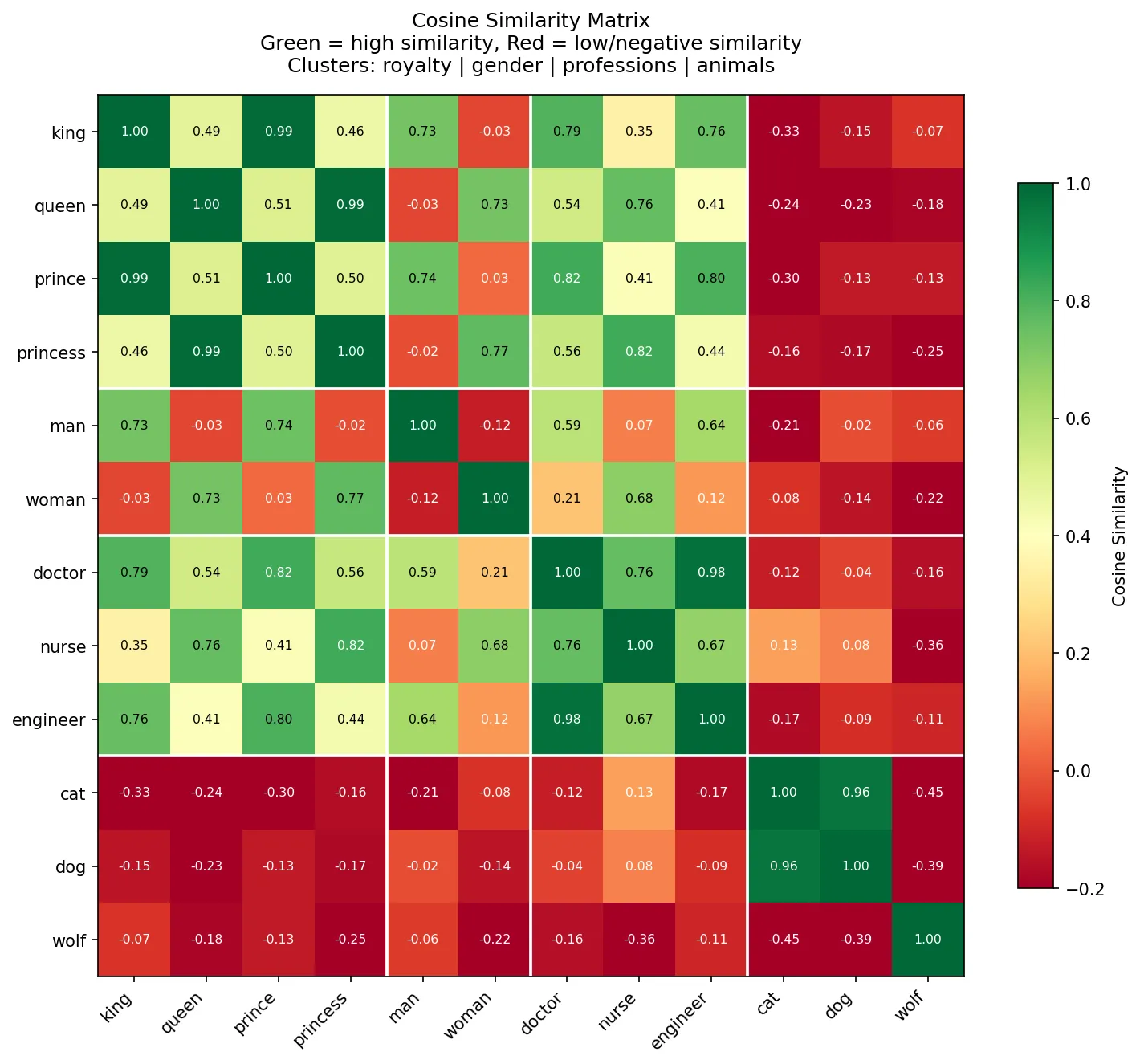
*图4:12 个词的两两余弦相似度矩阵。绿色=高相似,红色=低/负相似。白线划定了四个语义簇的边界(皇室、性别、职业、动物)。观察:同簇内相似度显著高于跨簇;动物簇与其他三簇几乎没有重叠。这正是”语义相近的词在向量空间里相邻”的可视化证明。*
六、向量的偏见:语料即世界观
Word2Vec 学到的不是语言的真相,而是语料库的统计规律。而语料库,是人类写作的产物——它带着人类的偏见、历史的偏见、文化的偏见。
这不是一个边缘问题,这是分布假设的核心代价。
Bolukbasi et al. (2016) 的实验
他们发现,Google News 训练的 Word2Vec 里:
"男人之于医生,如同女人之于护士"——这个类比在向量空间里成立,因为它在训练语料里统计上成立。
更直接的测试:
不是"女程序员",而是"家庭主妇"。
这不是算法的 bug,这是算法正确地学到了语料库中的统计规律。Bug 在于:我们误把统计规律当成了语义真相。
偏见来自哪里?
分布假设说:词的意义藏在它的邻居里。但如果邻居的分布本身是有偏的——
- 新闻报道里,"CEO"的邻居词更多是"他的决定",而不是"她的决定"
- 历史文本里,"科学家"更多和男性名字共现
- 小说里,情感词的性别分布不均匀
Word2Vec 忠实地学到了这些规律。它是一面镜子,照出的是语料,不是世界。
这揭示了分布假设的一个根本性限制:
向量空间学到的是描述性的(descriptive)统计规律,而推理需要的是规范性的(normative)真值。"在语料中,X 和 Y 经常共现"不等于"X 和 Y 在世界上有因果关系",也不等于"这种共现是正确的"。
你可以对词向量做去偏见处理(Bolukbasi 的论文就提出了一种线性投影方法),但这是在隔靴搔痒——治标不治本。根本问题是:从统计相关性出发,无法抵达语义的真值。
这个限制,在 Transformer 和大语言模型时代依然存在。规模更大的语料,偏见更大,覆盖也更广——但分布假设的底层逻辑没有变。
七、类比的幻觉
让我回到那个方程:
这真的是推理吗?
让我们拆开来想。
这个等式成立,意味着在词向量空间里,“国王”和”男人”的向量差,近似等于”女王”和”女人”的向量差。
这是什么?这是一个关于向量偏移方向一致的陈述。是几何上的规律性,不是逻辑上的推理。
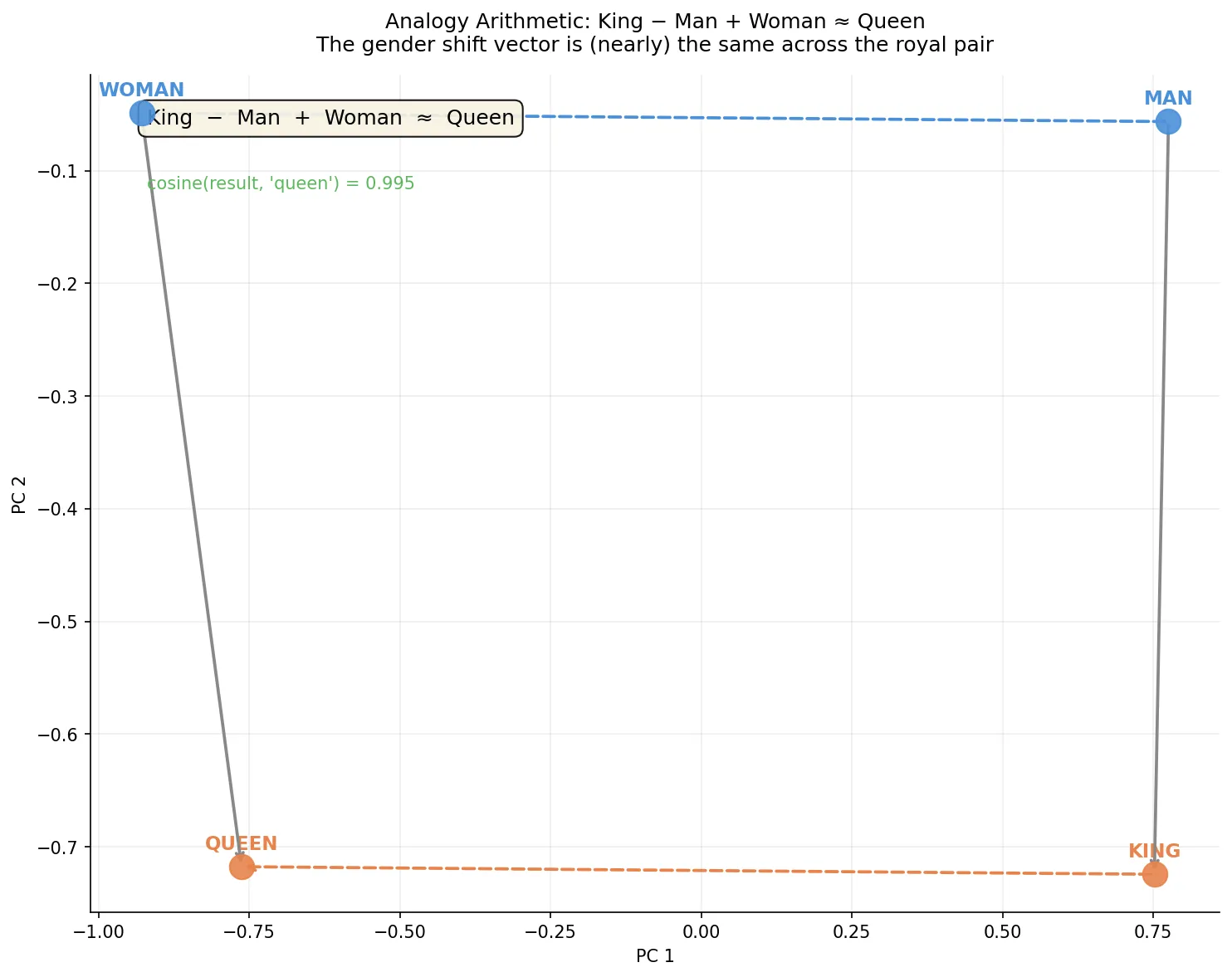
图2:向量类比的几何可视化。四个词在 PCA 二维空间中形成一个近似平行四边形——man→king 和 woman→queen 是两条近似平行的边,而 man→woman 和 king→queen 是另一对近似平行的边。这就是”性别移位向量在皇室词对上保持一致”的意思。King − Man + Woman 的余弦相似度接近 0.995。
在逻辑里,推理需要规则 + 事实 → 结论。“所有国王都是男人”加上”伊丽莎白是女王”,推出”伊丽莎白不是国王”——这是推理,因为有传递性,有变量绑定,有量词。
向量算术没有这些。它只是在说:这些词在语义空间里的相对位置,展现出某种平行结构。
更重要的是,这个等式在很多情况下不成立。
Fournier et al.(2020)系统性地分析了类比测试的局限性,发现:所谓的”类比等式”大量依赖于一个取巧的评估方式——在答案中排除了输入词本身,而最近邻往往就是输入词之一。改变评估方式之后,大量”类比能力”的统计结果显著下降 → [Fournier et al., 2020, arXiv:2010.03446]。
还有一个更直接的例子。你试试这个类比:
医生 - 男人 + 女人 ≈ ?
在某些训练语料上,你得到的不是”女医生”,而是”护士”。
因为在那些语料里,“医生”更频繁地和男性上下文共现,“护士”更频繁地和女性上下文共现。模型学到的不是”医生”这个职业的中立含义,而是它在特定语料里的统计偏见。
向量表示不捕获真理。它捕获语料的统计分布。语料里有偏见,向量里就有偏见。这不是 bug,这是它的工作原理。

图3:左图,皇室类比成功——King − Man + Woman 的结果向量高度接近 Queen(余弦 ≈ 0.995),平行四边形结构清晰。右图,职业类比失败——Doctor − Man + Woman 不指向”女医生”,而指向 Nurse(余弦 ≈ 0.865)。这是因为训练语料中 Doctor 倾向于男性上下文,Nurse 倾向于女性上下文。同一个算术,不同的偏见结果。
八、分布假设的上限
让我们更深入地想一下分布假设的边界在哪里。
分布假设说:意义由上下文分布决定。这在大量情况下是对的。但它意味着:如果两个词在文本里的上下文分布完全相同,模型会认为它们意思相同。
“我喜欢猫”和”我喜欢狗”——这两句话的结构完全对称,所以”猫”和”狗”在分布上高度相似。确实,它们在语义上很接近,模型是对的。
但是:
“地球绕太阳转”和”太阳绕地球转”
这两句话,如果你只看词的分布,“地球”和”太阳”会出现在非常相似的上下文里——它们经常出现在关于天文、引力、公转的句子里。但这两句话,一个是真的,一个是假的。
分布语义模型没有关于真值的概念。它不知道哪些命题是真的,哪些是假的。它知道的,是哪些词出现在哪些上下文里——这是一种统计规律,不是关于世界的因果模型。
这就是为什么向量表示尽管在很多任务上表现良好,却没有解决推理问题。它解决的是表示问题:用一种更丰富、更连续的方式来表示概念,使得相似的概念在几何上相近。但”相近”不等于”有逻辑关系”,“统计共现”不等于”因果相关”。
Wittgenstein 说过一句话,在这里显得很应景:语言的意义是它的用法。分布假设抓住了这个直觉的一部分——词的意义确实体现在它的用法里。但用法是统计性的,而理解是不是也是统计性的?这是个悬而未决的问题。
九、从词向量到句子,代价的累积
Word2Vec 给出的是静态词向量——每个词对应一个固定的向量,不管它出现在什么上下文里。
“银行”这个词,在”我去银行取钱”和”河岸(bank)上长满了野花”里,静态词向量是同一个。这是它的根本局限之一。
ELMo(2018)和后来的 BERT(2018)引入了上下文化词向量——同一个词在不同上下文里有不同的向量表示。这是一个重大进步。但它带来了另一个代价:你不再有一个简洁的、可以离线查表的词向量,你需要每次都跑完整个网络。
:::details ELMo 和 BERT:什么是上下文化词向量?
静态词向量(如 Word2Vec):每个词只有一个向量,不管它出现在哪里。"苹果"不管是指水果还是 Apple 公司,向量都一样。
上下文化词向量(ELMo、BERT):同一个词在不同句子里有不同的向量,因为整个句子都被送入网络,词的表示受上下文影响。
- ELMo(2018,Allen AI):用双向 LSTM 生成上下文敏感的词向量,作为特征给下游任务用
- BERT(2018,Google):用 Transformer Encoder 做双向语言模型预训练,fine-tune 到下游任务
代价:不能再查表,每次推理都要跑完整网络,计算量大幅提升。这是精度与效率之间永恒的权衡。
:::
更根本的问题是:句子的意义,不等于词向量的简单组合。
“猫咬了狗”和”狗咬了猫”,如果你对词向量做平均,你会得到几乎相同的句子向量——因为用的是同样的三个词。但这两句话描述的是完全相反的事件。
词的意义可以被向量编码,但句子的意义依赖于结构——谁是主语,谁是宾语,动词的论元关系。纯粹的向量运算,没有捕获结构。
这个问题推动了 Transformer 的发明——用注意力机制来动态地处理词与词之间的关系,而不是简单地叠加。但这是第九章的故事。
十、一个小小的停顿
让我梳理一下。
从符号到向量,这是一次真正的范式跃迁。它解决了符号 AI 的一个核心问题:语义的表示。概念不再是无意义的原子,它们在向量空间里有了位置,有了距离,有了方向。相似的概念相互接近,关系被编码成方向上的偏移。
这带来了真实的能力:语义检索、类比推理(某种形式的)、语义聚类、迁移学习的基础。
但它没有解决推理问题,因为三个原因:
第一,它捕获统计规律,不捕获因果结构。语料里有偏见,向量里就有偏见。语料里有相关性,向量里就有相关性。但相关性不是因果,分布不是真值。
第二,它没有组合性。词向量的简单线性组合,无法捕获句子的结构语义。“猫咬狗”和”狗咬猫”对词袋模型是相同的,这是根本性的缺陷。
第三,类比等式看起来像推理,但不是推理。它是几何上的平行结构,不是逻辑上的传递推导。在它不成立的时候(比如带有社会偏见的类比),它会安静地给出一个错误的答案,没有任何警告。
向量表示是推理的前提条件之一,但不是推理本身。
十一、还有一个更深的问题
分布假设的深层预设是:语言能够承载意义,而且意义可以从语言使用模式中被提取。
这是一个可以被质疑的预设。
John Searle 的中文房间思想实验(1980)是这个方向上最著名的攻击。想象一下:一个完全不懂中文的人被关在房间里,他手里有一本厚厚的规则手册,告诉他看到什么汉字符号就输出什么汉字符号。从外面看,他好像懂中文,能回答中文问题——但他完全不知道那些符号的意义,只是在机械地执行规则。
:::info
兔狲教授的评语
这个思想实验像一面镜子,照出了符号操作的尴尬真相:你可以完美地模仿理解,却完全不理解。词向量模型做的事情,在某种意义上很像这个中文房间——它从大量文本里提取出极其精细的统计模式,这些模式在很多任务上产生了正确的行为。但它是否”理解”了那些词的意义?这个问题没有简单的答案,因为我们首先需要定义什么叫”理解”。
:::
但有一个更实际的测试:分布偏移。如果你把模型放到训练分布之外,让它处理训练语料里从未见过的组合方式,它的行为会怎样?如果它的表现崩塌,你有理由怀疑它只是记住了分布,而不是真正理解了语言。
这是第五章的核心问题。现在,先记住这个悬念。
向量捕获了相似性,但不捕获因果。下一章,我们将进入高维空间的几何——流形假设揭示了为什么数据不是随机分布的。
悬而未决
-
类比等式
vec(King) - vec(Man) + vec(Woman) ≈ vec(Queen)是推理的证据,还是统计的巧合?它对某些类比成立,对另一些类比失败——这种不一致性告诉了我们什么? -
分布假设的边界在哪里?存在不能从文本分布中被学到的意义吗?颜色?疼痛?身体感知?
-
词向量捕获了社会偏见——这是它的缺陷,还是它的功能?删除了偏见的词向量,是否也丢失了某些真实的世界结构?
-
如果你用纯粹的噪声文本训练 word2vec,你会得到什么?这个思想实验说明了什么?
自己动手:用向量算术戳破类比的幻觉
这一章说了一件重要的事:类比等式看起来像推理,但它只是几何上的平行结构。你要亲手验证这个区别,不是读懂它,是感受它崩溃的那一刻。
你需要访问一个预训练词向量模型。最简单的选项:用 Python 的 gensim 库加载 Google 发布的 word2vec 模型,或者用 fasttext 的预训练向量。
第一步:验证那个著名的等式
从最经典的类比开始:
用本章第五节给出的逻辑实现:
import numpy as np # 假设 model 是已加载的 gensim KeyedVectors 对象 # 加载方式示例: # from gensim.models import KeyedVectors # model = KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True) def analogy_query(model, positive_word, minus_word, plus_word, topn=5): """ 执行向量类比查询:vec(positive_word) - vec(minus_word) + vec(plus_word) model: gensim KeyedVectors 对象 返回:最近邻词及其余弦相似度分数的列表 """ # 计算目标向量:vec("king") - vec("man") + vec("woman") target_vector = (model[positive_word] - model[minus_word] + model[plus_word]) # 在词汇表中找到与目标向量余弦相似度最高的词 # gensim 的 similar_by_vector 会自动排除输入词(通过 negative 参数控制) results = model.similar_by_vector( target_vector, topn=topn + 3 # 多取几个,以便手动过滤输入词 ) # 排除 positive_word、minus_word、plus_word 本身 exclude = {positive_word.lower(), minus_word.lower(), plus_word.lower()} filtered = [(word, score) for word, score in results if word.lower() not in exclude][:topn] return filtered # ── 运行经典类比:king - man + woman ≈ ? ─────────────────────── results = analogy_query(model, "king", "man", "woman") print("类比查询:king - man + woman ≈ ?") print("─" * 35) for rank, (word, score) in enumerate(results, 1): print(f" 第{rank}名: {word:15s} 余弦相似度 = {score:.4f}")
你应该得到 “queen”,余弦相似度接近 0.7 到 0.9。
你的第一个问题: 这个结果让你感到惊讶吗?把你的直觉记录下来:这看起来"像推理"还是"像算术"?在你回答之前,不要往下读。
第二步:系统性地验证,然后找反例
从以下四类类比中,每类选 3 对,依次测试:
第一类:性别类比 - man → woman 类比适用于:国王、医生、教授、护士、工程师……
第二类:首都关系 - 法国 → 巴黎,类比适用于:中国、日本、德国、美国……
第三类:时态变换 - go → went 类比适用于:run、swim、eat、think……
第四类:反义词 - good → bad 类比适用于:big、hot、fast、happy……
对每个测试案例,记录: - 预期答案是什么 - 实际输出的前 5 个最近邻是什么 - 余弦相似度是多少
你的第二个问题: 哪一类类比成功率最高?哪一类最低?你能推测为什么吗——是训练语料的问题,还是这种关系本来就不适合用线性偏移来编码?
第三步:亲手复现职业偏见实验
测试本章第七节里描述的那个失败案例:
医生 - 男人 + 女人 ≈ ?
然后扩展测试: - 工程师 - 男人 + 女人 ≈ ? - 护士 - 女人 + 男人 ≈ ? - CEO - 男人 + 女人 ≈ ? - 清洁工 - 女人 + 男人 ≈ ?
记录每个结果。
你的第三个问题: 对于输出结果有明显偏见的词对,你的解释是什么?这些偏见,是词向量系统的 bug,还是训练语料真实统计结构的如实反映?如果是后者,"去偏见"意味着什么?
第四步:找到类比等式的几何条件
做一个更精确的测试:类比等式什么时候会精确成立,什么时候会严重失败?
构造下面的实验:
对于一组你选择的类比对,计算以下两个量:
import numpy as np def cosine_similarity(v1, v2): """计算两个向量之间的余弦相似度。""" return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2)) def analogy_precision(model, analogies): """ 批量测量类比精度。 analogies: 列表,每项为 (A, B, C, D),表示 A:B :: C:D 的类比关系。 返回:每条类比的详细测量结果。 """ results = [] for (A, B, C, D) in analogies: # 计算预测向量:vec(B) - vec(A) + vec(C) predicted_vector = model[B] - model[A] + model[C] # 获取整个词汇表按相似度排序的结果(排除输入词) exclude = {A.lower(), B.lower(), C.lower()} neighbors = model.similar_by_vector(predicted_vector, topn=len(model.key_to_index)) # 过滤掉输入词,得到带排名的词表 filtered_neighbors = [(word, score) for word, score in neighbors if word.lower() not in exclude] # 实际最近邻排名:词汇表中按相似度排序后 D 的位置 rank_of_D = None for idx, (word, score) in enumerate(filtered_neighbors, 1): if word.lower() == D.lower(): rank_of_D = idx break # 计算偏移向量一致性:vec(B) - vec(A) 和 vec(D) - vec(C) 的余弦相似度 # 这直接衡量两对词之间的"关系方向"是否一致 offset_AB = model[B] - model[A] offset_CD = model[D] - model[C] offset_consistency = cosine_similarity(offset_AB, offset_CD) results.append({ "analogy": f"{A}:{B} :: {C}:{D}", "top1_hit": rank_of_D == 1, # D 是否出现在前 1 名(精确命中) "top5_hit": rank_of_D is not None and rank_of_D <= 5, # D 是否出现在前 5 名 "rank_of_D": rank_of_D, "offset_consistency": offset_consistency, # 偏移向量一致性(几何层面的测量) }) return results # ── 示例测试 ──────────────────────────────────────────────────── test_analogies = [ ("man", "king", "woman", "queen"), # 性别 × 皇室 ("france", "paris", "japan", "tokyo"), # 国家 × 首都 ("go", "went", "run", "ran"), # 动词时态 ("good", "bad", "big", "small"), # 反义词 ("man", "doctor", "woman", "nurse"), # 职业偏见案例 ] precision_results = analogy_precision(model, test_analogies) print(f"{'类比':30s} {'精确命中':^8s} {'前5命中':^8s} {'排名':^6s} {'偏移一致性':^10s}") print("─" * 70) for r in precision_results: print(f"{r['analogy']:30s} " f"{'✓' if r['top1_hit'] else '✗':^8s} " f"{'✓' if r['top5_hit'] else '✗':^8s} " f"{str(r['rank_of_D']):^6s} " f"{r['offset_consistency']:^10.4f}")
你的第四个问题(核心问题): 类比失败的时候,"偏移向量一致性"分数是高还是低?也就是说,几何结构(偏移方向相同)是否成立,但最近邻检索却失败了?如果是这样,失败的原因在几何,还是在检索方式?这说明了第七节的哪个论点?
第五步:构造一个让余弦相似度撒谎的例子
余弦相似度衡量方向,不衡量长度。找两个词,它们的余弦相似度很高,但你直觉上认为它们语义差距很大——或者反过来,余弦相似度低,但你认为它们语义应该很近。
def find_counterintuitive_similarities(model, word, topn=20, low_threshold=0.3): """ 对于给定词 W: 1. 找余弦相似度最高的 topn 个词,从中寻找"违和感"词 2. 找余弦相似度低于 low_threshold 的词,检查有无语义上相关但几何距离远的词 model: gensim KeyedVectors 对象 """ print(f"=== 词 '{word}' 的余弦相似度分析 ===\n") # 找余弦相似度最高的 topn 个词 top_neighbors = model.most_similar(word, topn=topn) print(f"余弦相似度最高的 {topn} 个词(寻找让你感到违和的词):") for w, score in top_neighbors: print(f" {w:20s} 相似度 = {score:.4f}") print() # 找余弦相似度较低的词中是否有语义上你认为相关的 # 方法:对一组候选词直接计算相似度 candidate_words = ["science", "art", "mathematics", "philosophy", "literature", "music", "history", "biology"] print(f"候选词的余弦相似度(相似度低于 {low_threshold} 但你认为语义相关?):") for candidate in candidate_words: if candidate in model: sim = model.similarity(word, candidate) flag = " ← 语义相关但距离远?" if sim < low_threshold else "" print(f" {candidate:20s} 相似度 = {sim:.4f}{flag}") # ── 示例运行 ──────────────────────────────────────────────────── find_counterintuitive_similarities(model, word="physics", topn=20, low_threshold=0.3)
你的第五个问题: 余弦相似度没有捕获到的语义关系,是什么类型的关系?这和本章第八节"分布假设的上限"有什么联系?
检验标准
完成这个练习,你应该有以下三样东西:
-
一张表格:你测试过的所有类比,成功/失败,和你的解释
-
一个偏见案例:亲手复现的、让你感到不舒服的结果,和你对这个结果的立场
-
一个反直觉的余弦相似度案例:向量几何和语言直觉之间,真实存在的裂缝
第三样最重要。这条裂缝,就是向量表示和真正推理之间的距离。
延伸阅读
-
Mikolov et al. (2013). Efficient Estimation of Word Representations in Vector Space — word2vec 原始论文,CBOW 与 Skip-gram 架构,
→ [arXiv:1301.3781] -
Mikolov et al. (2013). Distributed Representations of Words and Phrases and their Compositionality — 负采样、短语向量与组合性,
→ [arXiv:1310.4546] -
Fournier, Dupoux & Dunbar (2020). Analogies minus analogy test — 对类比测试的批判性分析,表明标准评估有缺陷,
→ [arXiv:2010.03446] -
Firth, J.R. (1957). A synopsis of linguistic theory 1930-55 — 分布假设的哲学起点,“你可以通过交往的朋友来认识一个词”
-
Searle, J. (1980). Minds, Brains, and Programs — 中文房间思想实验,对符号操作能否产生理解的哲学攻击
-
Bolukbasi et al. (2016). Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings — 词向量偏见问题的经典实证研究