第7章:复杂度的真相:不是快慢,是结构
文档摘要
第7章:复杂度的真相:不是快慢,是结构 P≠NP(如果成立)告诉我们的不是”有些问题很难”,而是”宇宙本身有某种不对称性”。 一、一个不对称 2023年,当DeepSeek-R1和GPT-4在各种推理任务上刷新记录时,研究者们开始测试它们在NP完全问题上的表现。结果令人震惊。 \[Zixi Li, 2025a\]设计了OpenXOR测试——一个基于约束满足的诊断工具。任务很简单:给定一组XOR风格的约束满足实例,判断是否存在满足所有约束的赋值。注意,这里说的不是线性代数里可以高斯消元的纯XOR-SAT,而是被设计成具有组合搜索结构的OpenXOR诊断任务:它保留了“异或关系”的局部迷惑性,同时把求解推入NP难搜索的相变区域。
第7章:复杂度的真相:不是快慢,是结构
P≠NP(如果成立)告诉我们的不是”有些问题很难”,而是”宇宙本身有某种不对称性”。
一、一个不对称
2023年,当DeepSeek-R1和GPT-4在各种推理任务上刷新记录时,研究者们开始测试它们在NP完全问题上的表现。结果令人震惊。
[Zixi Li, 2025a]设计了OpenXOR测试——一个基于约束满足的诊断工具。任务很简单:给定一组XOR风格的约束满足实例,判断是否存在满足所有约束的赋值。注意,这里说的不是线性代数里可以高斯消元的纯XOR-SAT,而是被设计成具有组合搜索结构的OpenXOR诊断任务:它保留了“异或关系”的局部迷惑性,同时把求解推入NP难搜索的相变区域。
:::details NP 完全问题:为什么它比普通难题难得多?(兔狲原创研究:OpenXOR, Zixi Li 2025)
NP(Nondeterministic Polynomial):一类问题的集合——给你一个候选答案,你可以在多项式时间内验证它是否正确。比如 3-SAT:给你一组变量赋值,你可以很快检查它是否满足所有子句。
P(Polynomial):另一类问题的集合——你可以在多项式时间内直接找到答案。比如排序、最短路径(Dijkstra)。
NP 完全(NP-complete):NP 里最难的一批问题,难到什么程度?如果你能高效解决其中任意一个,你就能高效解决所有 NP 问题。
P = NP? 这是计算机科学最著名的未解问题。大多数人相信 P ≠ NP——即验证远比搜索容易,这两种能力有根本区别。但没有人能证明它。
为什么 LLM 不能解 NP 完全问题? 因为 LLM 的推理是多项式时间的(有限的前向传播步骤),而 NP 完全问题需要指数级的搜索——规模扩大就会崩溃,这是架构的根本限制,不是参数量的问题。
:::
测试结果令人震惊。DeepSeek-R1的任务完成率是0%。GPT-4的任务完成率也是0%。而一个只有100k参数的符号求解器OpenLM,准确率达到了76%。
注意,这不是0%准确率,而是0%任务完成率——模型要么拒绝回答(37-42%),要么触碰上下文限制(28-31%),要么产生幻觉约束(18-22%)。它们甚至没有尝试去解决问题。
这个结果揭示了一个深刻的事实:规模不是问题的关键,架构才是。
但为什么?千亿参数的模型,为什么连一个100k参数的符号求解器都能做对的问题都搞不定?
这里有一个关键事实:LLM的前向传播是多项式时间的——无论模型多大,一个前向pass里的计算量被层数L和序列长度N的乘积限制在O(LN^2)。而OpenXOR的测试实例不是随便挑的:它们的约束密度被精心控制在\alpha \approx 4.26附近——一个我们稍后会详细讨论的相变临界点。在这个点上,3-SAT实例从"几乎总可解"骤变为"几乎总不可解",求解器恰好卡在最难搜索的区域。
符号求解器OpenLM用了回溯和传播——本质上在做指数级搜索,被100k参数高效组织。LLM没有搜索,只有前向传播。多项式时间的架构,碰上了指数级难度的问题,结果就是0%的任务完成率。 规模可以让你在多项式时间内做更复杂的模式匹配,但无法把多项式时间变成指数时间。这是架构边界,不是算力边界。
让我们从最基础的地方开始理解这个不对称。
二、验证与搜索:一个简单的实验
拿出一张纸,写下这个3-SAT实例:
(x₁ ∨ ¬x₂ ∨ x₃) ∧ (¬x₁ ∨ x₂ ∨ ¬x₄) ∧ (x₂ ∨ x₃ ∨ x₄) ∧ (¬x₁ ∨ ¬x₃ ∨ x₄)
现在我告诉你一个候选解:x₁=真, x₂=假, x₃=真, x₄=真。
验证它是否满足所有子句:
第一个子句:x₁=真,满足。
第二个子句:¬x₁=假,x₂=假,¬x₄=假… 等等,这个子句不满足。
所以这不是一个解。整个验证过程花了你多久?10秒?20秒?
现在,不看答案,从零开始找一个满足所有子句的赋值。
你可能会尝试:
-
x₁=真, x₂=真, x₃=真, x₄=真 检查 不满足
-
x₁=真, x₂=真, x₃=真, x₄=假 检查 不满足
-
x₁=真, x₂=真, x₃=假, x₄=真 检查 不满足
-
…
4个变量有2⁴=16种可能。如果运气不好,你可能需要尝试所有16种才能找到解(或确认无解)。
这就是验证与搜索的不对称。验证一个候选解需要O(m)时间,m是子句数量,线性时间。但搜索一个解需要O(2ⁿ × m)时间,n是变量数量,指数时间。
当n=10时,搜索空间是1024。当n=100时,搜索空间是2¹⁰⁰ \approx 10³⁰——比宇宙中的原子数还多。
这不是工程问题,这是数学事实。
三、自己动手:体验指数墙
让我们做一个更直观的实验。
步骤1:构造一个小规模3-SAT实例
变量:x₁, x₂, x₃, x₄(4个布尔变量)
子句:
(x₁ ∨ ¬x₂ ∨ x₃) (¬x₁ ∨ x₂ ∨ ¬x₄) (x₂ ∨ x₃ ∨ x₄) (¬x₁ ∨ ¬x₃ ∨ x₄)
步骤2:验证一个候选解
给定赋值:x₁=T, x₂=F, x₃=T, x₄=T
逐个检查子句(每个子句至少一个文字为真即可):
-
子句1:x₁=T,满足
-
子句2:x₂=F,满足
-
子句3:x₂=F, x₃=T,满足
-
子句4:¬x₁=F, ¬x₃=F, x₄=T,满足
验证通过!用时:O(4)=常数时间。
步骤3:搜索所有可能解
现在不看答案,枚举2⁴=16种赋值:
from itertools import product # 定义4变量3-SAT实例 # 每个子句是一个文字列表;正数 i 表示 x_i,负数 -i 表示 ¬x_i clauses = [ [1, -2, 3], # (x₁ ∨ ¬x₂ ∨ x₃) [-1, 2, -4], # (¬x₁ ∨ x₂ ∨ ¬x₄) [2, 3, 4], # (x₂ ∨ x₃ ∨ x₄) [-1, -3, 4], # (¬x₁ ∨ ¬x₃ ∨ x₄) ] def check_clause(clause, assignment): """检查单个子句是否满足:至少一个文字为真""" for lit in clause: # lit > 0 表示正文字,lit < 0 表示否定文字 val = assignment[abs(lit) - 1] if (lit > 0 and val) or (lit < 0 and not val): return True return False def check_sat(clauses, assignment): """检查所有子句是否同时满足""" return all(check_clause(c, assignment) for c in clauses) # 枚举所有 2^4 = 16 种赋值(False=0, True=1) print(f"{'x₁':^5}{'x₂':^5}{'x₃':^5}{'x₄':^5}{'满足?':^8}") print("-" * 35) solutions = [] for bits in product([False, True], repeat=4): sat = check_sat(clauses, bits) mark = "是" if sat else "否" vals = ["T" if b else "F" for b in bits] print(f"{vals[0]:^5}{vals[1]:^5}{vals[2]:^5}{vals[3]:^5}{mark:^8}") if sat: solutions.append(bits) print(f"\n共找到 {len(solutions)} 个满足赋值:") for sol in solutions: print(" ", {f"x{i+1}": ("T" if v else "F") for i, v in enumerate(sol)})
体验指数增长:
-
5个变量 32种赋值
-
10个变量 1024种赋值
-
20个变量 1,048,576种赋值
步骤4:思考题
如果变量数增加到100,穷举需要多久?
假设每秒检查10⁹个赋值(现代CPU的速度),需要:
宇宙年龄是138亿年。你需要宇宙年龄的万分之一来解决一个100变量的3-SAT实例。
这就是指数墙。
四、相变:问题最难的地方
但并非所有3-SAT实例都一样难。
这听起来像是废话。当然不一样难——10个变量的实例比100个变量的实例简单。但我说的不是这个。
我说的是:即使变量数量相同,不同的3-SAT实例,难度也可能天差地别。而这个差别,不是随机的,而是有规律的。
考虑两个极端。第一个极端是欠约束的情况:10个变量,20个子句,子句密度\alpha = 2。约束很少,解的空间很大。你随机扔一个赋值进去,很可能就碰到了一个解。求解器几乎不需要回溯。
第二个极端是过约束的情况:10个变量,80个子句,子句密度\alpha = 8。约束太多,矛盾很快暴露。求解器走几步就发现”这条路走不通”,迅速剪枝,换一条路。虽然没有解,但证明无解的速度很快。
这两个极端都不难。
但在\alpha \approx 4.26附近,发生了奇怪的事情。
[Xu & Li, 2000]在2000年的开创性工作中发现:当子句密度\alpha = m/n从2增加到8时,可满足概率不是平滑下降。
它在\alpha \approx 4.26处发生了剧烈相变。
从接近1,骤降到接近0。不是渐进的衰减,而是断崖式的坠落。
这不是第一次在计算问题里看到相变。但每次看到,都让人不安。因为这意味着,问题的性质在某个临界点发生了质的改变。就像水在0°C从固态变为液态,磁铁在居里温度失去磁性,3-SAT在\alpha \approx 4.26从”几乎总可解”变为”几乎总不可解”。
更重要的是,这个相变点恰好是问题最难求解的地方。
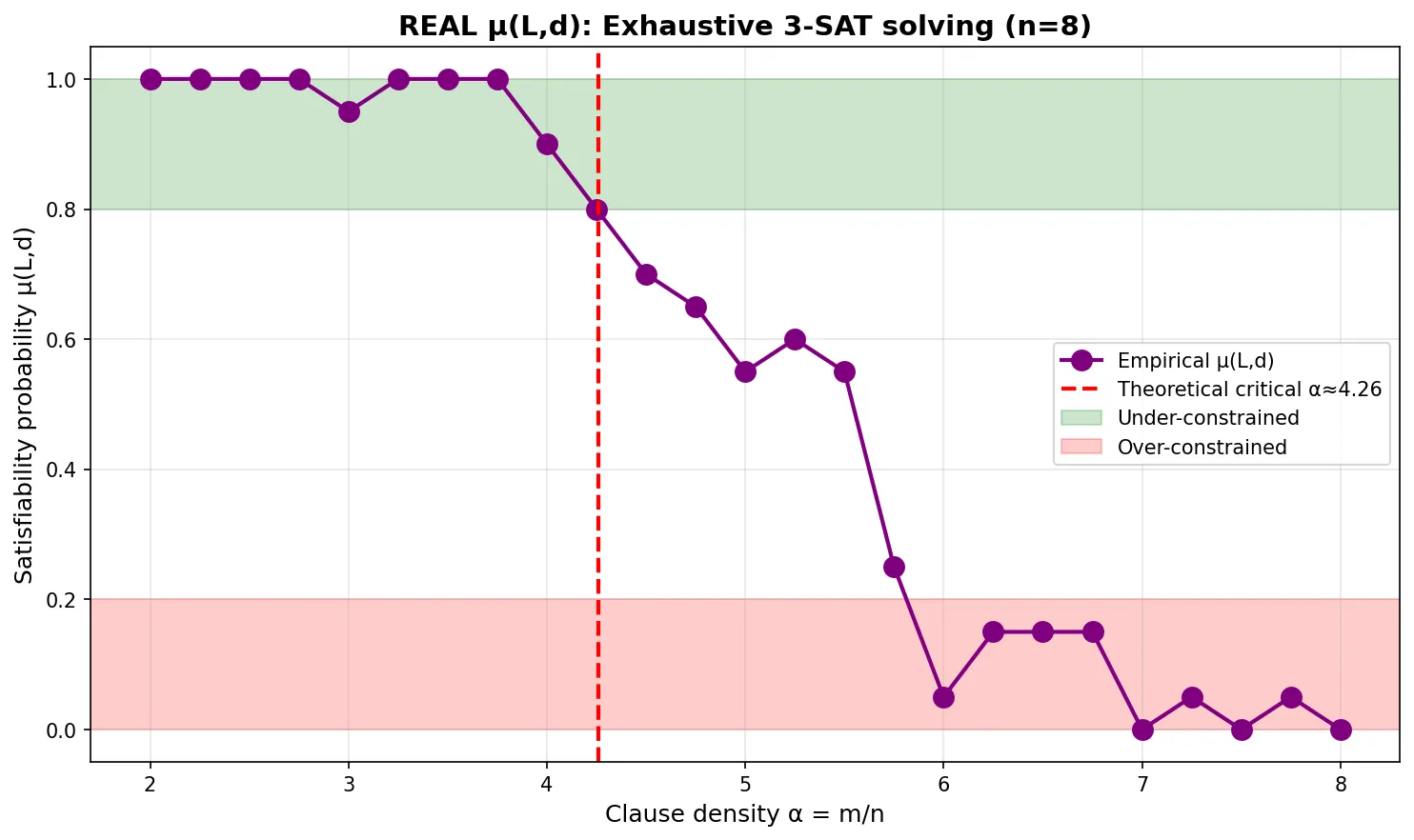 横轴是子句密度\alpha = m/n,纵轴是随机实例的可满足概率。S型曲线在\alpha \approx 4.26处发生陡峭相变。绿色阴影区域(\alpha < 4.2)是欠约束区,几乎总可解。红色阴影区域(\alpha > 4.3)是过约束区,几乎总不可解。临界点附近(黄色区域)是最难求解的区域。
横轴是子句密度\alpha = m/n,纵轴是随机实例的可满足概率。S型曲线在\alpha \approx 4.26处发生陡峭相变。绿色阴影区域(\alpha < 4.2)是欠约束区,几乎总可解。红色阴影区域(\alpha > 4.3)是过约束区,几乎总不可解。临界点附近(黄色区域)是最难求解的区域。
为什么临界点最难?
让我先说两个极端的情况。
在欠约束区,解的数量很多。随机搜索很容易碰到一个。求解器不需要太聪明,只需要运气不太差。
在过约束区,矛盾很快暴露。求解器走几步就发现”这条路不通”,回溯,剪枝,换一条路。虽然最终证明无解,但这个过程很快。
但在临界点,求解器陷入了一个微妙的平衡。
解的数量很少,但不是零。所以你不能放弃搜索。矛盾不够明显,所以回溯树变得巨大。搜索空间既不稀疏也不密集,恰好处于最难导航的状态——你既找不到捷径,也无法快速排除错误的方向。
这是一种最糟糕的困境。
[Zhan, 2026]用离散几何模型解释了这个现象。他将3-SAT映射到N维布尔超立方体的组合拓扑,推导出最小不可满足极限为\alpha = 8/N,最大可满足极限为\alpha = 7/6(N-1)(N-2)。
这解释了为何可满足性阈值猜想仅”几乎必然”成立——在有限规模下,相变不是绝对的,而是概率性的。
五、μ(L,d):将离散边界连续化
传统复杂度理论的问题在于,它只告诉我们一个问题”属于”P还是NP,却无法量化一个具体实例有多难。
3-SAT是NP完全的——这是一个二元判决。但这不意味着所有3-SAT实例都一样难。一个10变量、20子句的实例和一个100变量、420子句的实例,难度天差地别。
[Zixi Li, 2025a]的OpenXOR框架突破了这个限制。它将NP问题的可解性从二元判决转化为连续相图。
对于规模L、约束密度d的实例,定义可解概率μ(L,d):
其中临界约束密度满足对数标度律:
这个公式的美妙之处在于三点。第一,普适性:所有不同规模的相变曲线坍缩为单一核函数。第二,可预测性:给定L和d,可以预测可解概率,无需实际求解。第三,连续性:\mu \in [0,1],不是”可解”或”不可解”的二元判决。
实验验证:在22,000个OpenXOR实例上,这个公式的均方误差MSE~10⁻³。
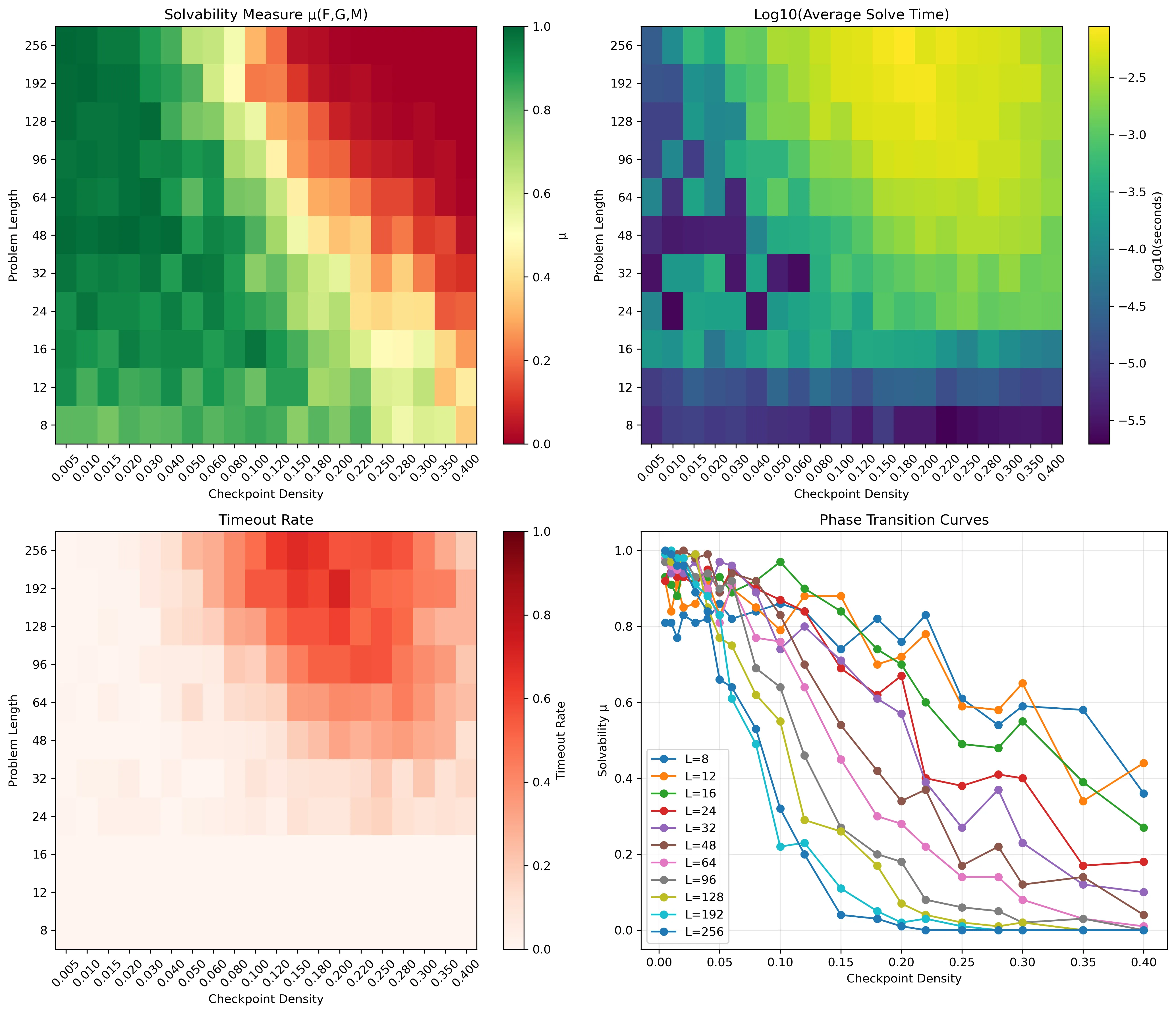
OpenXOR相图:横轴是约束密度d,纵轴是问题规模L。颜色表示可解概率\mu(L,d),从深蓝(\mu \approx 0,几乎不可解)到深红(\mu \approx 1,几乎总可解)。白色曲线是临界边界d_c(L),沿着这条线\mu \approx 0.5。相变核函数将离散的P/NP边界变为连续的概率景观。
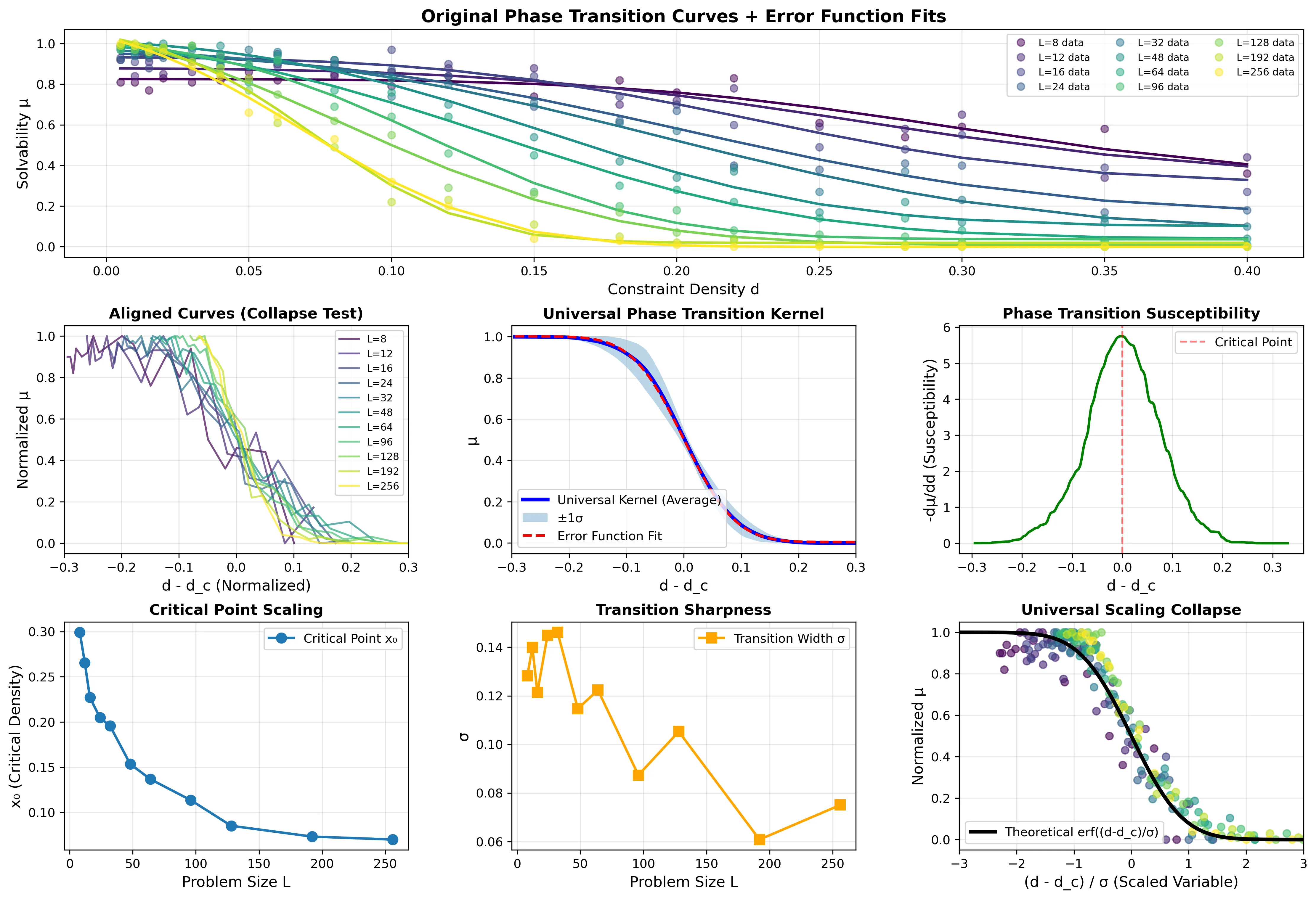
所有不同规模的相变曲线坍缩为单一误差函数核。这个普适性表明,相变的"形状"是规模无关的,只有临界点位置随ln(L)移动。
这揭示了一个哲学转变:可计算性不是二元的,而是概率性的。
传统复杂度理论像一张行政地图:这个问题属于P,那个问题属于NP,边界画得很清楚。但真实的实例分布更像气象图。你不能只问“这里属于哪个国家”,还要问“这里的能见度是多少、风暴在哪个方向移动、温度是否正在穿过临界点”。
\mu(L,d) 做的事情,就是把行政地图改成气象图。它不推翻P/NP的分类,而是在分类内部补上一层读者真正需要的东西:一个具体实例到底有多接近崩塌边缘。
:::details 为什么 \mu(L,d) 比“这是NP完全”更有信息量?
“3-SAT是NP完全”只告诉你最坏情况下没有已知高效算法。它不告诉你一个具体实例会不会很快被求解器解决。
L 表示规模,d 表示约束密度,d_c(L) 表示这个规模下的临界密度。于是:
- 当 d \ll d_c(L):约束太少,解很多,随机搜索都容易撞上答案;
- 当 d \gg d_c(L):约束太多,矛盾很快暴露,剪枝很有效;
- 当 d \approx d_c(L):解稀少但不消失,矛盾存在但不显眼,搜索树最大。
所以最难的不是“最大”的实例,而是“最接近相变”的实例。OpenXOR 的意义就在这里:它不是拿规模吓唬模型,而是把模型放在复杂度景观最薄、最危险的冰面上。
:::
NP不是一堵墙,而是一片有梯度的雾。在雾的边缘(\mu \approx 0.5),问题处于可解与不可解的量子叠加态。微小的参数变化就能导致质的飞跃。
六、NP完全性:Cook-Levin定理与归约
P vs NP 是一个存在性问题——我们不知道答案。但在这个问题悬而未决的情况下,数学家做了一件聪明的事:证明某些问题"和所有NP问题一样难"。
这就是 NP 完全性。
6.1 Cook-Levin定理:SAT是NP完全的
1971年,斯蒂芬·库克(Stephen Cook,和独立工作的列昂尼德·列文 Leonid Levin)证明了一个惊人的定理:
SAT(布尔可满足性问题)是 NP 完全的。
SAT 问的是:给定一个布尔公式(AND/OR/NOT 组成的逻辑表达式),是否存在一组变量赋值使它为真?
比如:(x_1 \lor \neg x_2) \land (\neg x_1 \lor x_3) \land (\neg x_2 \lor \neg x_3)
是否存在 x_1, x_2, x_3 的赋值使整个公式为真?
Cook-Levin 定理说的是两件事:
第一,SAT 属于 NP:给定一组赋值,验证它是否满足公式,只需要 O(n) 时间。验证很容易,搜索(找赋值)可能很难。
第二,所有 NP 问题都可以归约到 SAT:对于任意 NP 问题 X,任意 X 的实例都可以在多项式时间内转化为一个 SAT 实例,使得:原实例有解 \iff SAT 实例可满足。
这个归约方向是关键:不是说 SAT 和 X 一样难,而是说SAT 至少和 X 一样难——因为你可以用 SAT 求解器来解 X。
如果有人发明了多项式时间的 SAT 算法,那他同时解决了所有 NP 问题。
Cook 在 1971 年做了一件比证明 P≠NP 更聪明的事。他不知道 P 和 NP 是否相等——到今天也没人知道。但他证明了 SAT 是所有 NP 问题的天花板。如果你能捅破 SAT 这层天花板,整个 NP 大厦都会塌成 P。
这就是归约的力量:你不需要一个个打倒所有 NP 问题——3-SAT、旅行商、背包问题、图着色……每一个都不同,每一个都难。但归约告诉你,它们共享同一种"难度结构"。打倒一个,就是打倒全部。
6.2 多项式归约:难度的传递
NP 完全性的核心工具是多项式时间归约(polynomial-time reduction)。
问题 A 多项式归约到问题 B(记作 A \leq_p B),意思是:
存在一个多项式时间算法 f,使得 x \in A \iff f(x) \in B。
直觉:如果你能解 B,你能用 f 把 A 的实例转化成 B 的实例,然后用 B 的算法求解,再把答案翻译回来。代价只是多项式的转化时间。
归约链:Cook 证明了 SAT 是 NP 完全的。此后,理查德·卡普(Richard Karp, 1972)给出了21个经典问题的归约链:
每一步归约都证明了新问题是 NP 完全的。
这个归约链有一个哲学意义:这些看起来毫无关联的问题,在计算难度上是等价的。图论、组合优化、逻辑推理……它们底层共享同一种"难度结构"。
6.3 为什么这对推理有意义
NP 完全性告诉我们:
如果 P≠NP,那么不存在通用的高效推理算法。
定理证明、计划问题、约束满足……这些推理任务大多是 NP 完全的。这意味着:
- 精确算法在最坏情况下是指数级的
- 启发式(第8章)和近似算法(也是第8章)是唯一实际可行的路径
- 没有任何算法能同时做到:通用、高效、精确
这三者,你只能选两个。这不是工程限制,是数学定理。
七、停机问题:计算的根本禁区
如果说P vs NP是关于"难度"的问题,那么停机问题则是关于"可能性"的问题。
这两个边界有本质区别。P vs NP 问的是:搜索比验证难多少?即使 P≠NP,你仍然可以暴力搜索,只是要花指数级时间——它在时间维度上画了一条线。停机问题问的是:这个程序会停下来吗?即使给你无限的时间和无限的内存,也没有任何算法能回答——它在逻辑维度上封死了答案。
一个用时间丈量,一个用逻辑封死。计算的两种边界,互不重叠。
它不是说某些问题很难解决,而是说某些问题根本无法解决。
停机问题问的是:给定一个程序P和它的输入x,能否判断P(x)是否会停机(而不是无限循环)?
图灵在1936年用对角化论证证明了这个问题不可判定。让我们重现这个证明。
假设:存在一个停机判定器H(P, x),它能判断程序P在输入x上是否停机。
构造:定义一个新程序D:
矛盾:现在问D(D)会停机吗?
-
如果H(D, D)返回”停机”,那么D(D)会进入无限循环,不停机
-
如果H(D, D)返回”不停机”,那么D(D)会立即返回,停机
无论哪种情况,H的判断都是错的。所以H不可能存在。
这个证明的深刻之处不在于技巧,而在于它揭示的结构性限制。
停机问题不可判定,不是因为: - 我们还没找到足够聪明的算法 - 计算机还不够快 - 我们需要更多内存
而是因为任何算法都无法解决它。这是逻辑必然,不是技术限制。
[Hamkins & Nenu, 2024]对图灵原始论文进行了细致的历史分析。他们指出,虽然图灵1936年的论文确实包含了不可判定性的核心思想,但现代形式的停机问题表述是后来逐步完善的。这提醒我们,即使是最基础的理论结果,其历史演化也比我们想象的复杂。
停机问题划定了计算的终极边界。在这个边界之外,不是”难”,而是”不可能”。
八、复杂度的哲学意义
复杂度理论告诉我们的不仅仅是”哪些问题难”,而是宇宙的计算结构。
P vs NP问的是:验证与搜索之间的不对称性是本质的吗?如果P≠NP成立,那意味着宇宙中存在一种根本的不对称——知道答案比找到答案容易,而且这个差距无法被任何算法弥补。
这不是技术问题,而是关于知识本质的问题。为什么验证比发现容易?为什么理解比创造容易?这个不对称性暗示了什么?
相变核函数μ(L,d)则告诉我们,这个不对称不是绝对的,而是渐进的。在相变点附近,问题处于可解与不可解的临界状态。微小的参数变化就能导致质的飞跃——从”几乎总可解”到”几乎总不可解”。
停机问题则划定了计算的终极边界。有些问题不是”难”,而是”不可能”。这不是技术限制,而是逻辑必然。任何足够强大的计算系统都会遇到这个边界。
有些问题太难,不可能精确求解。下一章,我们将看到启发式算法如何用"明确代价的近似"绕开这堵墙——以及这个近似需要遵守什么契约。
悬而未决
-
P≠NP能被证明吗? 还是它本身就是一个不可判定命题?如果P≠NP不可证明,那意味着什么?
-
相变核函数能否推广? μ(L,d)框架能否推广到其他复杂度类,如PSPACE、EXP?不同问题的相变是否遵循统一的数学结构?
-
自然界的计算相变 蛋白质折叠、神经网络训练、生物进化——这些自然计算过程是否也遵循类似的相变规律?
-
LLM的架构缺陷 为什么100k参数的符号求解器能达到76%准确率,而千亿参数的LLM却0%任务完成率?差距在哪里?
延伸阅读
-
[Zixi Li, 2025a] — QMCB/OpenXOR, NP可解性连续相图
-
[Xu & Li, 2000] — 3-SAT相变的开创性工作
-
[Zhan, 2026] — 3-SAT的离散几何模型
-
[Istrate, 2000] — 计算复杂性与相变的理论联系
-
[Hamkins & Nenu, 2024] — 停机问题的历史澄清