第十九章:小型语言模型在生成式人工智能中的简介
文档摘要
小型语言模型在生成式人工智能中的简介 生成式人工智能是一个引人入胜的人工智能领域,专注于创建能够生成新内容的系统。这些内容可以是文本、图像,甚至是音乐和虚拟环境。生成式人工智能最令人兴奋的应用之一在于语言模型。 什么是小型语言模型? 小型语言模型(SLM)是一种大型语言模型(LLM)的缩放版本,采用了许多与LLM相同的架构原则和技术,但计算足迹显著减少。SLM是语言模型的一个子集,旨在生成类似人类的文本。与较大的模型(如GPT-4)相比,SLM更紧凑且高效,使其适用于计算资源有限的应用场景。尽管其规模较小,它们仍然可以执行各种任务。通常,SLM通过压缩或蒸馏LLM来构建,旨在保留原始模型的功能和语言能力的一部分。这种模型规模的减小降低了整体复杂性,使SLM在内存使用和计算需求方面更加高效。
小型语言模型在生成式人工智能中的简介
生成式人工智能是一个引人入胜的人工智能领域,专注于创建能够生成新内容的系统。这些内容可以是文本、图像,甚至是音乐和虚拟环境。生成式人工智能最令人兴奋的应用之一在于语言模型。
什么是小型语言模型?
小型语言模型(SLM)是一种大型语言模型(LLM)的缩放版本,采用了许多与LLM相同的架构原则和技术,但计算足迹显著减少。SLM是语言模型的一个子集,旨在生成类似人类的文本。与较大的模型(如GPT-4)相比,SLM更紧凑且高效,使其适用于计算资源有限的应用场景。尽管其规模较小,它们仍然可以执行各种任务。通常,SLM通过压缩或蒸馏LLM来构建,旨在保留原始模型的功能和语言能力的一部分。这种模型规模的减小降低了整体复杂性,使SLM在内存使用和计算需求方面更加高效。
尽管进行了这些优化,SLM仍能执行广泛的自然语言处理(NLP)任务:
- 文本生成:创建语法正确且上下文相关的句子或段落。
- 文本补全:基于给定提示预测并完成句子。
- 翻译:将文本从一种语言转换为另一种语言。
- 摘要:将长篇文本压缩成较短、更易消化的摘要。
- 与较大的模型相比,某些性能或理解深度方面的权衡是不可避免的。
小型语言模型如何工作?
SLM在大量文本数据上进行训练。在训练过程中,它们学习语言的模式和结构,从而使生成的文本既语法正确又上下文相关。训练过程包括:
- 数据收集:从各种来源收集大量文本数据集。
- 预处理:清理和组织数据,使其适合训练。
- 训练:使用机器学习算法教模型如何理解和生成文本。
- 微调:调整模型以提高其在特定任务上的性能。
SLM的发展顺应了对可以在资源受限环境中部署的模型的需求增加,例如移动设备或边缘计算平台,在这些环境中,全尺寸LLM可能由于其巨大的资源需求而不切实际。通过注重效率,SLM平衡了性能和可访问性,使其能够在各个领域广泛应用。

学习目标
在这节课中,我们希望介绍SLM的知识,并将其与Microsoft Phi-3结合起来,了解在文本内容、视觉和混合专家(MoE)中的不同应用场景。到这节课结束时,你应该能够回答以下问题:
- 什么是SLM
- SLM与LLM有什么区别
- 什么是Microsoft Phi-3/3.5系列
- 如何推理Microsoft Phi-3/3.5系列
让我们开始吧。
大型语言模型(LLMs)和小型语言模型(SLMs)的区别
LLMs和SLMs都基于概率机器学习的基础原理,其架构设计、训练方法、数据生成过程和模型评估技术相似。然而,这两种模型有几个关键因素的不同之处。
小型语言模型的应用
SLMs具有广泛的应用场景,包括:
- 聊天机器人:提供客户服务并与用户进行对话。
- 内容创作:帮助作者生成想法甚至撰写整篇文章。
- 教育:帮助学生完成写作作业或学习新语言。
- 可访问性:为残疾人创建工具,例如文本转语音系统。
尺寸
LLMs和SLMs之间的一个主要区别在于模型的规模。LLMs,如ChatGPT(GPT-4),可以包含大约1.76万亿个参数,而开源SLMs如Mistral 7B则设计为具有显著较少的参数——大约70亿个。这种差异主要是由于模型架构和训练过程的不同。例如,ChatGPT采用了一种在编码器-解码器框架内的自注意力机制,而Mistral 7B使用滑动窗口注意力,这使得在仅解码器模型中更有效地训练成为可能。这种架构上的差异对这些模型的复杂性和性能有着深远的影响。
理解能力
SLMs通常针对特定领域的性能进行优化,使其高度专业化,但在跨多个知识领域提供广泛上下文理解方面可能有限。相比之下,LLMs旨在在一个更全面的层面上模拟类人的智能。经过大规模、多样化的数据集训练,LLMs被设计为在各种领域表现良好,提供了更大的多样性和适应性。因此,LLMs更适合于广泛的下游任务,如自然语言处理和编程。
计算资源
LLMs的训练和部署是资源密集型的过程,通常需要大量的计算基础设施,包括大规模GPU集群。例如,从零开始训练一个像ChatGPT这样的模型可能需要数千个GPU并持续较长的时间。相反,SLMs由于其较小的参数数量,在计算资源方面更具可及性。像Mistral 7B这样的模型可以在配备适度GPU能力的本地机器上进行训练和运行,尽管训练仍需要多个GPU进行数小时的处理。
偏见
偏见是LLMs的一个已知问题,主要由于训练数据的性质。这些模型通常依赖于互联网上公开可用的原始数据,这可能会低估或错误地表示某些群体,引入错误标记,或反映受方言、地理差异和语法规则影响的语言偏见。此外,LLM架构的复杂性可能会无意中加剧偏见,如果没有仔细的微调,这些偏见可能不被察觉。相比之下,SLMs在更受约束、领域特定的数据集上进行训练,因此本质上不太容易受到此类偏见的影响,尽管它们并不完全免疫。
推理
SLMs的减小规模为其在推理速度方面提供了显著优势,使其能够在本地硬件上高效生成输出,而无需大量的并行处理。相比之下,由于其规模和复杂性,LLMs通常需要大量的并行计算资源才能达到可接受的推理时间。多个并发用户的出现进一步减慢了LLMs的响应时间,尤其是在大规模部署时。
总结来说,虽然LLMs和SLMs都基于机器学习的基本原理,但它们在模型大小、资源需求、上下文理解、偏见敏感性和推理速度方面存在显著差异。这些差异反映了它们各自适用于不同用例的能力,LLMs更加通用但资源密集,而SLMs提供更专业的领域效率,同时减少了计算需求。
注意:在这一章节中,我们将使用Microsoft Phi-3/3.5作为例子来介绍SLM。
介绍Phi-3/Phi-3.5系列
Phi-3/3.5系列主要针对文本、视觉和代理(MoE)应用情景:
Phi-3/3.5指令
主要用于文本生成、聊天完成和内容信息提取等。
Phi-3-mini
3.8B语言模型可在Microsoft Azure AI Studio、Hugging Face和Ollama上获取。Phi-3模型在关键基准测试中显著优于同等规模及更大规模的语言模型(请参阅下表中的基准数字,数值越高越好)。Phi-3-mini在双倍大小模型面前表现出色,而Phi-3-small和Phi-3-medium也超过了较大的模型,包括GPT-3.5。
Phi-3-small & medium
Phi-3-small仅使用7B参数就在多种语言、推理、编程和数学基准测试中击败了GPT-3.5T。Phi-3-medium拥有14B参数,延续了这一趋势,并且优于Gemini 1.0 Pro。
Phi-3.5-mini
我们可以将其视为Phi-3-mini的升级版。虽然参数保持不变,但它提升了支持多种语言的能力(支持20多种语言:阿拉伯语、中文、捷克语、丹麦语、荷兰语、英语、芬兰语、法语、德语、希伯来语、匈牙利语、意大利语、日语、韩语、挪威语、波兰语、葡萄牙语、俄语、西班牙语、瑞典语、泰语、土耳其语、乌克兰语)并且增强了对长上下文的支持。Phi-3.5-mini拥有3.8B参数,在相同规模的语言模型面前表现出色,并与双倍大小的模型相当。
Phi-3/3.5视觉
我们可以将Phi-3/3.5的指令模型视为Phi的理解能力,而视觉则赋予Phi“眼睛”来理解世界。
Phi-3-Vision
Phi-3-vision仅使用4.2B参数,延续了这一趋势,并在一般视觉推理任务、OCR和表格与图表理解任务中超越了更大的模型,如Claude-3 Haiku和Gemini 1.0 Pro V。
Phi-3.5-Vision
Phi-3.5-Vision也是Phi-3-Vision的升级版,增加了对多张图片的支持。你可以认为这是在视觉上的改进,不仅可以看图片,还可以看视频。Phi-3.5-vision在OCR、表格和图表理解任务以及一般视觉知识推理任务上超越了更大的模型,如Claude-3.5 Sonnet和Gemini 1.5 Flash。支持多帧输入,即对多个输入图像进行推理。
Phi-3.5-MoE
***混合专家(MoE)***使模型能够在计算资源有限的情况下进行预训练,这意味着你可以用与密集模型相同的计算预算大幅扩展模型或数据集的规模。特别是,MoE模型应该在预训练期间比其密集对应物更快地达到相同的质量。Phi-3.5-MoE包含16个3.8B专家模块。Phi-3.5-MoE仅使用6.6B活动参数即可实现与更大模型相似的推理、语言理解和数学水平。
我们可以根据不同的场景使用Phi-3/3.5系列模型。与LLM不同,你可以在边缘设备上部署Phi-3/3.5-mini或Phi-3/3.5-Vision。
如何使用Phi-3/3.5系列模型
我们希望在不同的场景中使用Phi-3/3.5。接下来,我们将根据不同场景使用Phi-3/3.5。

推理差异
云API
GitHub Models
GitHub Models
请注意,输出中的图片链接在翻译后可能无法直接显示,因为它们指向外部资源。如果需要,可以手动添加这些链接以查看对应的图片。
以下是翻译后的文本,保持了Markdown格式:
是最快捷的方式。您可以通过GitHub Models快速访问Phi-3/3.5-Instruct模型。结合Azure AI Inference SDK / OpenAI SDK,您可以通过代码访问API来完成Phi-3/3.5-Instruct调用。您还可以通过Playground测试不同的效果。 - Demo:比较Phi-3-mini和Phi-3.5-mini在中文场景中的效果 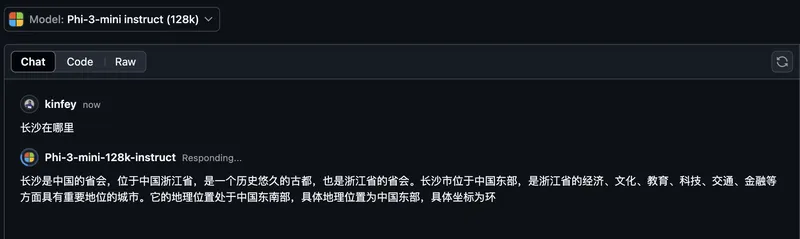 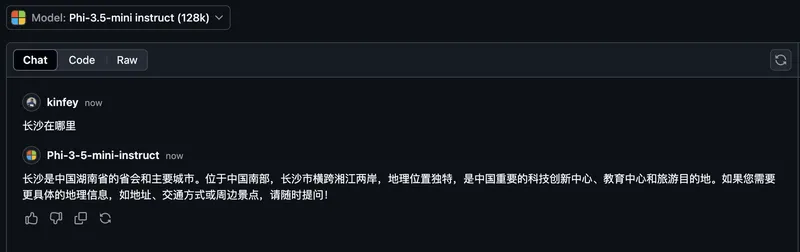 **Azure AI Studio** 或者,如果我们想使用视觉和MoE模型,您可以使用Azure AI Studio来完成调用。如果您感兴趣,可以阅读Phi-3 Cookbook以了解如何通过Azure AI Studio调用Phi-3/3.5 Instruct、Vision和MoE。 [点击这里](https://github.com/microsoft/Phi-3CookBook/blob/main/md/02.QuickStart/AzureAIStudio_QuickStart.md?WT.mc_id=academic-105485-koreyst) **NVIDIA NIM** 除了Azure和GitHub提供的基于云的Model Catalog解决方案,您还可以使用[Nivida NIM](https://developer.nvidia.com/nim?WT.mc_id=academic-105485-koreyst)来完成相关调用。您可以在NIVIDA NIM中完成Phi-3/3.5系列的API调用。 NVIDIA NIM(NVIDIA Inference Microservices)是一组加速推理微服务,旨在帮助开发者在各种环境中高效部署AI模型,包括云、数据中心和工作站。以下是NVIDIA NIM的一些关键特性: - **易于部署:** NIM允许您通过一条命令部署AI模型,使其轻松集成到现有工作流中。 - **优化性能:** 它利用了NVIDIA预先优化的推理引擎,如TensorRT和TensorRT-LLM,以确保低延迟和高吞吐量。 - **可扩展性:** NIM支持在Kubernetes上自动扩展,使其能够有效处理不同的工作负载。 - **安全性和控制:** 组织可以通过在其自有管理的基础架构上托管NIM微服务来维护对其数据和应用程序的控制。 - **标准API:** NIM提供了行业标准API,使得构建和集成像聊天机器人、AI助手等AI应用程序变得容易。 NIM是NVIDIA AI Enterprise的一部分,旨在简化AI模型的部署和运维,确保它们在NVIDIA GPU上高效运行。 - Demo: 使用Nividia NIM调用Phi-3.5-Vision-API [[点击这里](./python/Phi-3-Vision-Nividia-NIM.ipynb?WT.mc_id=academic-105485-koreyst)] ### 在本地环境中进行Phi-3/3.5推理 与Phi-3或任何语言模型(如GPT-3)相关的推理是指根据输入生成响应或预测的过程。当您向Phi-3提供一个提示或问题时,它会使用其训练过的神经网络通过分析其训练数据中的模式和关系来推断最可能和相关的响应。 **Hugging Face Transformers** Hugging Face Transformers是一个强大的库,用于自然语言处理(NLP)和其他机器学习任务。以下是一些关于它的关键点: 1. **预训练模型:** 它提供了数千个预训练模型,可用于各种任务,如文本分类、命名实体识别、问答、摘要、翻译和文本生成。 2. **框架互操作性:** 该库支持多种深度学习框架,包括PyTorch、TensorFlow和JAX。这允许您在一个框架中训练模型并在另一个框架中使用它。 3. **多模态能力:** 除了NLP,Hugging Face Transformers还支持计算机视觉(例如图像分类、对象检测)和音频处理(例如语音识别、音频分类)的任务。 4. **易于使用:** 该库提供了API和工具,使下载和微调模型变得容易,使其对初学者和专家都易于使用。 5. **社区和资源:** Hugging Face拥有活跃的社区和广泛的文档、教程和指南,帮助用户入门并充分利用该库。 [官方文档](https://huggingface.co/docs/transformers/index?WT.mc_id=academic-105485-koreyst) 或他们的 [GitHub仓库](https://github.com/huggingface/transformers?WT.mc_id=academic-105485-koreyst)。 这是最常用的方法,但这也需要GPU加速。毕竟,视觉和MoE等场景需要大量的计算,如果不量化,在CPU上将非常有限。 - Demo: 使用Transformer调用Phi-3.5-Instuct [点击这里](./python/phi35-instruct-demo.ipynb?WT.mc_id=academic-105485-koreyst) - Demo: 使用Transformer调用Phi-3.5-Vision [点击这里](./python/phi35-vision-demo.ipynb?WT.mc_id=academic-105485-koreyst) - Demo: 使用Transformer调用Phi-3.5-MoE [点击这里](./python/phi35_moe_demo.ipynb?WT.mc_id=academic-105485-koreyst) **Ollama** [Ollama](https://ollama.com/?WT.mc_id=academic-105485-koreyst) 是一个平台,旨在使您更容易在本地机器上运行大型语言模型(LLMs)。它支持各种模型,如Llama 3.1、Phi 3、Mistral和Gemma 2等。该平台通过捆绑模型权重、配置和数据为一个包,简化了过程,使其更易于用户自定义和创建自己的模型。Ollama适用于macOS、Linux和Windows。如果您希望实验或部署LLMs而不依赖于云服务,这是一个很好的工具。 Ollama是最直接的方式,您只需要执行以下语句。 ```bash ollama run phi3.5
ONNX Runtime for GenAI
ONNX Runtime 是一个跨平台的推理和训练机器学习加速器。ONNX Runtime for Generative AI (GENAI) 是一个强大的工具,可以帮助您在各种平台上高效地运行生成式AI模型。
什么是ONNX Runtime?
ONNX Runtime是一个开源项目,可以实现高性能的机器学习模型推理。它支持Open Neural Network Exchange (ONNX) 格式的模型,这是一种表示机器学习模型的标准。ONNX Runtime推理可以实现更快的客户体验和更低的成本,支持来自深度学习框架(如PyTorch和TensorFlow/Keras)以及经典机器学习库(如scikit-learn、LightGBM、XGBoost等)的模型。ONNX Runtime兼容不同的硬件、驱动程序和操作系统,并通过适用的硬件加速器、图形优化和转换提供最佳性能。
什么是生成式AI?
生成式AI是指可以根据其训练数据生成新内容(如文本、图像或音乐)的AI系统。示例包括语言模型如GPT-3和图像生成模型如Stable Diffusion。ONNX Runtime for GenAI库为ONNX模型提供了生成式AI循环,包括使用ONNX Runtime进行推理、logits处理、搜索和采样以及KV缓存管理。
ONNX Runtime for GENAI
ONNX Runtime for GENAI扩展了ONNX Runtime的能力,以支持生成式AI模型。以下是其一些关键特性:
- 广泛平台支持: 它在各种平台上运行,包括Windows、Linux、macOS、Android和iOS。
- 模型支持: 它支持许多流行的生成式AI模型,如LLaMA、GPT-Neo、BLOOM等。
- 性能优化: 它包括针对不同硬件加速器(如NVIDIA GPU、AMD GPU等)的优化。
- 易于使用: 它提供了API,便于集成到应用程序中,使您可以用最少的代码生成文本、图像等内容。用户可以调用高级generate()方法,或在循环中运行模型的每次迭代,一次生成一个token,并且可以选择在循环内更新生成参数。
入门
要开始使用ONNX Runtime for GENAI,您可以按照以下步骤操作:
安装ONNX Runtime
pip install onnxruntime
安装生成式AI扩展
pip install onnxruntime-genai
运行模型
以下是在Python中的一个简单示例:
import onnxruntime_genai as og model = og.Model('path_to_your_model.onnx') tokenizer = og.Tokenizer(model) input_text = "Hello, how are you?" input_tokens = tokenizer.encode(input_text) output_tokens = model.generate(input_tokens) output_text = tokenizer.decode(output_tokens) print(output_text)
Demo: 使用ONNX Runtime GenAI调用Phi-3.5-Vision
import onnxruntime_genai as og model_path = './Your Phi-3.5-vision-instruct ONNX Path' img_path = './Your Image Path' model = og.Model(model_path) processor = model.create_multimodal_processor() tokenizer_stream = processor.create_stream() text = "Your Prompt" prompt = "<|user|>\n" prompt += "<|image_1|>\n" prompt += f"{text}<|end|>\n" prompt += "<|assistant|>\n" image = og.Images.open(img_path) inputs = processor(prompt, images=image) params = og.GeneratorParams(model) params.set_inputs(inputs) params.set_search_options(max_length=3072) generator = og.Generator(model, params) while not generator.is_done(): generator.compute_logits() generator.generate_next_token() new_token = generator.get_next_tokens()[0] code += tokenizer_stream.decode(new_token) print(tokenizer_stream.decode(new_token), end='', flush=True)
其他
除了ONNX Runtime和Ollama参考方法外,我们还可以根据不同制造商提供的模型参考方法完成量化模型的参考。例如,Apple MLX框架与Apple Metal,Qualcomm QNN与NPU,Intel OpenVINO与CPU/GPU等。您也可以从Phi-3 Cookbook获得更多内容。
更多
我们已经学习了Phi-3/3.5系列的基本知识,但要了解更多关于SLM的知识,我们需要更多的知识。您可以在Phi-3 Cookbook中找到答案。如果想了解更多,请访问Phi-3 Cookbook。
**声明**: 本文件灏天文库团队进行了翻译。尽管我们力求准确,但请注意,翻译可能包含错误或不准确之处。原文档以其原始语言为准。我们不对因使用此翻译而产生的任何误解或误译负责。