第九章:大数据处理技术总结
文档摘要
第九章 大数据处理技术总结 王嘉鹏,胡锐锋 9.1 大数据技术框架综述   从2015年国家发布《促进大数据发展行动纲要》,到2017年发布《大数据产业发展规划(2016-2020年)》,再到现在(2021年)的国家大数据发展战略。大数据技术无疑处于了时代发展的浪潮之中。   不管你是否从事大数据行业,都有必要了解下大数据的发展。从第一章到第七章,相信我们已经对大数据基本组件的使用有所了解。实际上,一套大数据的解决方案通常会包含有多个重要的组件,一般来说,大数据框架在总体上分为存储引擎和计算分析引擎。存储引擎通常用来存储海量数据,而分析引擎通常用来分析海量数据。   针对存储引擎,详见第三章的 、第四章的 ;
第九章 大数据处理技术总结
王嘉鹏,胡锐锋
9.1 大数据技术框架综述
从2015年国家发布《促进大数据发展行动纲要》,到2017年发布《大数据产业发展规划(2016-2020年)》,再到现在(2021年)的国家大数据发展战略。大数据技术无疑处于了时代发展的浪潮之中。
不管你是否从事大数据行业,都有必要了解下大数据的发展。从第一章到第七章,相信我们已经对大数据基本组件的使用有所了解。实际上,一套大数据的解决方案通常会包含有多个重要的组件,一般来说,大数据框架在总体上分为存储引擎和计算分析引擎。存储引擎通常用来存储海量数据,而分析引擎通常用来分析海量数据。
针对存储引擎,详见第三章的HDFS、第四章的HBase;针对计算分析引擎,详见第五章的MapReduce,第六章的Hive,第七章的Spark。下图包含常用的存储引擎和分析引擎用到的技术(后续课程将会详细介绍相关技术):
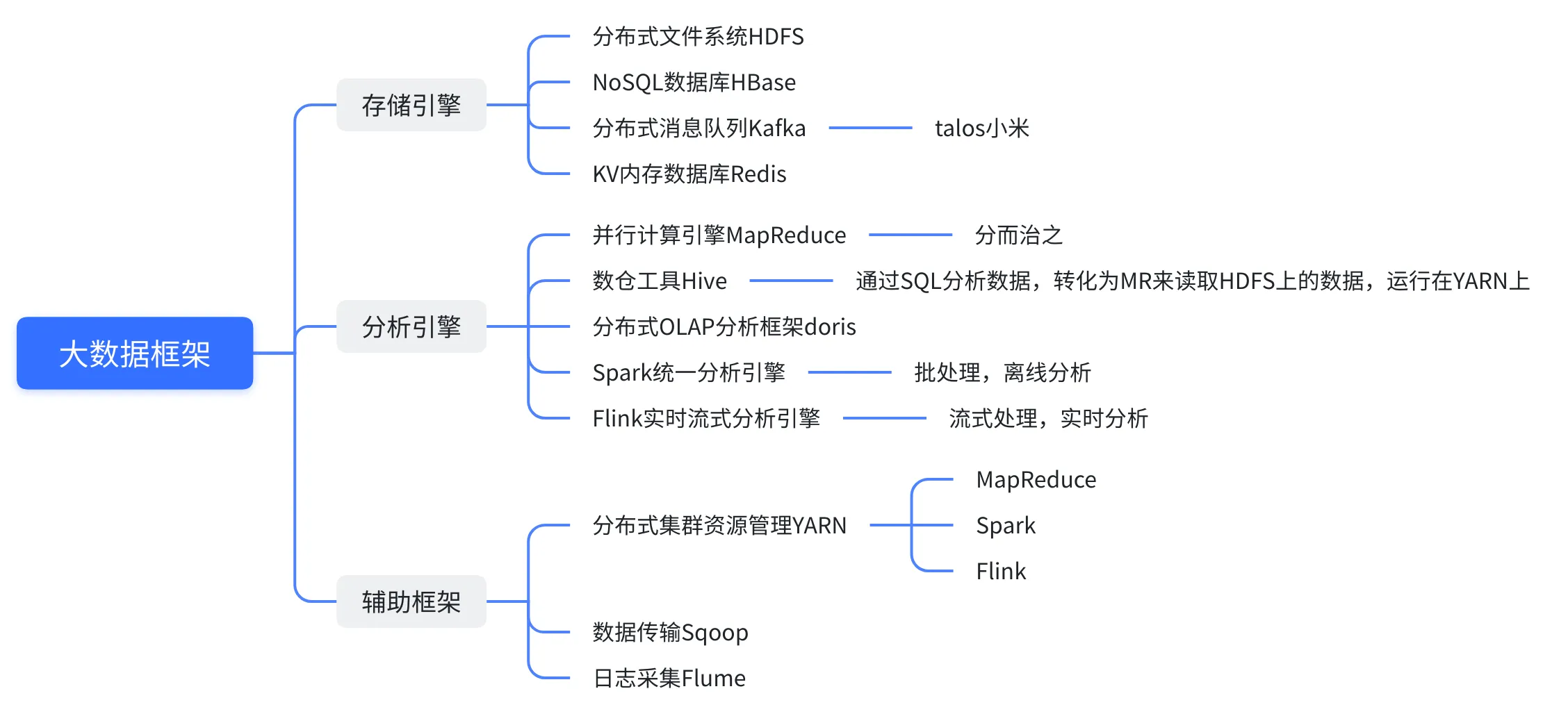
9.2 大数据分析引擎的发展简史
笔者根据大数据处理引擎出现时间,绘制了一张简图,用于总结过去20年间,大数据分析引擎的发展简史和未来方向:
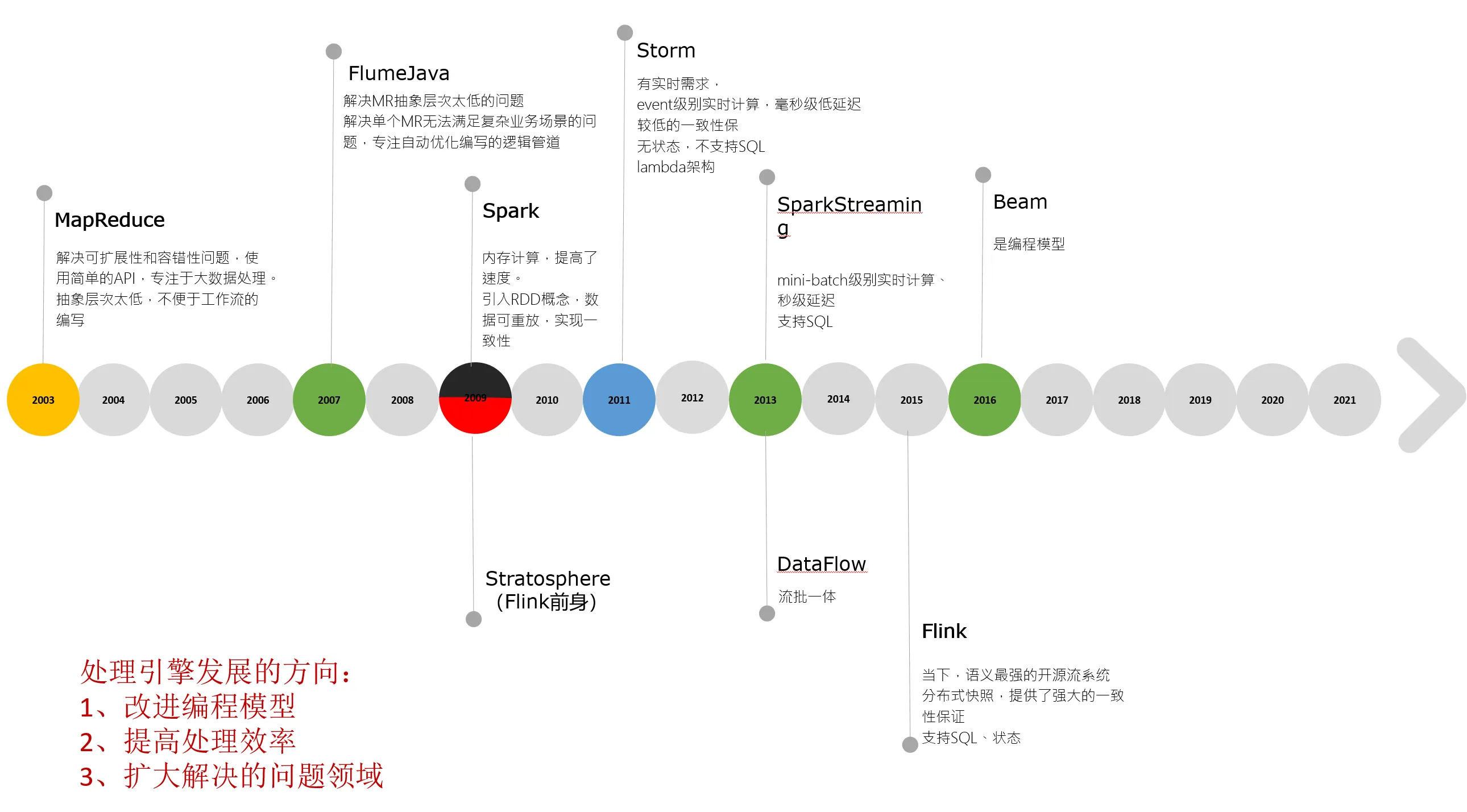
值得说明的是,该时间标注的是技术出现的时间。在生产环境中,这些技术得到大量运用的时间要比出现时间晚5-10年左右。
9.2.1 萌芽阶段(2003-2008)
20年前(没错,有点久了),随着互联网的发展,数据量激增,传统架构的存储容量、读写速度、计算效率等越来越无法满足用户的需求。为了解决这些问题,Google提出了三个处理大数据的技术手段,俗称**”三驾马车”**,从此开始进入大数据的萌芽时代。这三驾马车分别是:
- MapReduce:开源分布式并行计算框架
- BigTable:大型的分布式数据库
- GFS:Google的分布式文件系统
2003年、2004年,Google陆续发布了GFS和MapReduce思想细节。Nutch的创始人Doug Cutting受到启发,用了若干年时间实现了DFS和MapReduce机制,使Nutch性能飙升。
2005年,Hadoop作为Lucene子项目Nutch的一部分正式被引入Apache基金会,随后又从Nutch中剥离,成为一套完整独立的软件,起名为Hadoop,包括HDFS文件存储系统和MapReduce计算引擎。
- MapReducel:主要解决可扩展性和容错性问题,从而可以通过使用简单的API,专注于大数据处理。其缺点是抽象层次太低,不便于工作流的编写。
- FlumeJava:主要解决
MapReduce抽象层次太低的问题,解决单个MapReduce无法满足复杂业务场景的问题,专注自动优化编写的逻辑管道。
9.2.2. 快速发展阶段(2009-2014)
这个阶段,其实就是大家看到MapReduce的成功,发现了分布式处理机制,居然还可以这么干,这就像打开了新世界的大门似的。在这个阶段里,主要出现了Spark、Storm的技术。
-
Spark
主要改进是:- 内存计算,提高了速度;
- 引入
RDD概念,数据可重放,实现一致性; RDD的抽象概念,使数据流的处理很方便,代码编写简单。
缺点是:
Spark Streaming的实时计算,是伪实时、mini-batch的,不能真正覆盖实时应用的场景。 -
Storm
主要优点是:event级别实时计算,毫秒级低延迟,能满足实时需求
缺点是:- 较低的一致性保;
- 无状态;
- 不支持SQL。
关于Storm,比较有趣的是,因为Storm的无状态和较低的一致性保证,Storm的作者提出了Lambda架构(即离线计算+实时计算的架构)。而这个思想,在实时计算和离线计算间,也为后面”流批一体“的出现,埋下了种子。
9.2.3 成熟阶段(2015-至今)
技术的发展是一个不断总结的过程,这个阶段,就是总结上面所有组件的优点、抛弃缺点的过程。
- DataFlow
2015年,DataFlow流批一体论文的发布。在这之前,大家总是假设,输入数据在某个时间点后会变完整。其实,这个假设是有问题的。
论文作者们认为,当下面临了两个方面的问题,其一是庞大无序的数据,另一个是数据消费者复杂的语义和时间线上的各种需求。
DataFlow抽象出一个具有足够普遍性和灵活性的模型,通过执行引擎的选择,转换为延迟程度和处理成本之间的选择。(推荐感兴趣的同学,看下这篇论文 )这也为流批一体的实现提供了理论基础。
- Flink
现在,很多人都认为,Flink已经成为实时计算的事实标准。Flink不同于Spark的批处理(batch processing),它主要用于数据的流处理(streaming processing),将输入看做一条stream,将函数应用到stream上,再进行输出。Flink的底层是流式处理,其上层也是基于流式处理构建的batch,通过记录流式处理的start point,以及维护运行过程中的state实现一个窗口的batch处理。
9.2.4 大数据分析引擎发展方向
基于以前的分析引擎迭代阶段,对于大数据分析引擎发展的方向,可以总结为下面3个:
- 改进编程模型,让我们用更简单的
API,写出更复杂的业务处理逻辑; - 提高处理效率,效率必然是不可缺少的;
- 扩大解决的问题领域,一个处理引擎,能够处理更多的业务场景,意味着更少的维护成本、更少的集群投入、更简单的架构。
9.3 尾声
本课程作为大数据处理技术的导论课程,主要从存储引擎和分析引擎两个方面对大数据技术进行介绍:
第1章介绍了大数据的基本概念,主要包括大数据的主要发展历程、4个典型特点、应用场景和关键技术。
第2章介绍了大数据处理架构Hadoop,主要包括Hadoop发展历程、Hadoop的重要特性及其应用现状、Hadoop系统架构等,通过实验部分,介绍了在Linux系统下安装和配置Hadoop。
第3章介绍了Hadoop分布式文件系统HDFS,主要包括HDFS的体系结构、存储原理、数据读写流程等,通过实验部分,介绍了在Linux系统中的HDFS文件系统基本命令。
第4章介绍了分布式数据库HBase,主要包括HBase的数据模型、访问接口、实现原理和运行机制等,通过实验部分,介绍了在Linux系统中安装和配置HBase,以及HBase的基本操作。
第5章介绍了分布式并行编程模型MapReduce,主要包括MapReduce模型的具体工作原理,并以单词统计(WordCount程序)为示例,讲解了MapReduce程序设计方法。
第6章为期中大作业,补充了一些面试题和实战编程作为知识掌握程度的测试
第7章介绍了数据仓库Hive,主要包括数据仓库、Hive的基本概念、系统结构等,通过实验部分,介绍了在Linux系统中安装Hive,以及常用的DDL操作。
第8章介绍了大数据框架Spark,主要包括Spark的基本概念、编程模型、架构原理等,通过实验部分,介绍了在Linux系统中安装Spark,并以WordCount程序为示例,讲解了RDD的运行原理。
第9章对大数据处理技术做了一个总结与展望。
第10章为期中大作业,补充了一些面试题和实战编程作为知识掌握程度的测试。
希望能通过本教程让大家对大数据处理技术有一个基本的认识,并在这趟旅途中有所收获。感谢大家付出的时间和努力!