第七章:Hive
文档摘要
第七章 数据仓库Hive 王嘉鹏,shenhao 7.0 数据仓库 ps:到了数据仓库啦,崭新的饱满的和知识相濡以沫的一天,又开始啦!!!! 7.0.1 为什么要有数据仓库   在引入数据仓库之前,我们先来聊聊为什么会产生数据仓库呢!!   数据的作用有两个:操作型记录的保存和分析型决策的制定。 操作型记录的保存意味着企业通常不必维护历史数据,只需修改数据以反映最新的状态; 分析型决策意味着企业需要保存历史的数据,从而可以更精确的来评估现有状况进行决策。   基于后者分析型决策的优化,需要高性能地完成用户的查询,因此引出了数据仓库的概念。 7.0.
第七章 数据仓库Hive
王嘉鹏,shenhao
7.0 数据仓库
ps:到了数据仓库啦,崭新的饱满的和知识相濡以沫的一天,又开始啦!!!!

7.0.1 为什么要有数据仓库
在引入数据仓库之前,我们先来聊聊为什么会产生数据仓库呢!!

数据的作用有两个:操作型记录的保存和分析型决策的制定。
- 操作型记录的保存意味着企业通常不必维护历史数据,只需修改数据以反映最新的状态;
- 分析型决策意味着企业需要保存历史的数据,从而可以更精确的来评估现有状况进行决策。
基于后者分析型决策的优化,需要高性能地完成用户的查询,因此引出了数据仓库的概念。
7.0.2 数据仓库概念
数据仓库是一个面向主题的、集成的、非易失的、随时间变化的,用来支持管理人员决策的数据集合,数据仓库中包含了粒度化的企业数据。
随着信息技术的普及和企业信息化建设步伐的加快,企业逐步认识到建立企业范围内的统一数据存储的重要性,越来越多的企业已经建立或正在着手建立企业数据仓库。企业数据仓库有效集成了来自不同部门、不同地理位置、具有不同格式的数据,为企业管理决策者提供了企业范围内的单一数据视图,从而为综合分析和科学决策奠定了坚实的基础。
如下图所示,数据仓库的主要特征是:主题性、集成性、非易失性、时变性。

- 主题性
各个业务系统的数据可能是相互分离的,但数据仓库则是面向主题的。数据仓库将不同的业务进行归类并分析,将数据抽象为主题,用于对应某一分析领域所涉及的分析对象。
而操作型记录(即传统数据)对数据的划分并不适用于决策分析。在数据仓库中,基于主题的数据被划分为各自独立的领域,每个领域有各自的逻辑内涵但互不交叉,在抽象层次上对数据进行完整的、一致的和准确的描述。
以零售业务的过程为例:将多个零售业务数据(杂货、冷冻食品、生活用品、肉类等),依据业务主题进行数据划分,可创建一个具有订单、库存和销售等多个业务领域的零售业务数仓。

- 集成性
确定主题之后,就需要获取与主题相关的数据。这些数据会分布在不同的业务过程中,因此在数据进入数仓之前,需要对这些数据的口径进行统一。
口径统一是指,统一数据来源中的歧义、单位、字长等元素,并进行总和计算,来聚合成新的数据。
以上述零售业务过程中的订单主题为例,对于订单主题,通常会包括三个业务过程:订单、发货和发票。这些过程会产生一些新的指标,如:销售额、发票收入等。

-
非易失性
数据仓库的目的是分析数据中的规律,因此,添加到数据仓库中的数据,需要保证其稳定,不会轻易丢失和改变。
这里,与传统操作型数据库的区别在于:操作型数据库主要服务于日常的业务操作,产生的数据会实时更新到数据库中,以便业务应用能够迅速获得当前最新数据,不至于影响正常的业务运作。而数据仓库通常是保存历史业务数据,根据业务需要每隔一段时间将一批新的数据导入数据仓库。 -
时变性
数据仓库是根据业务需要来建立的,代表了一个业务过程。因此数据仓库分析的结果只能反映过去的业务情况,当业务变化后,数据仓库需要跟随业务的变化而改变,以适应分析决策的需要。
7.0.3 数据仓库的体系结构
数据仓库的体系结构通常包含4个层次:数据源、数据存储和管理、数据服务以及数据应用。

- 数据源:数据仓库的数据来源,包括外部数据、现有业务系统和文档资料等。
- 数据存储和管理:为数据提供的存储和管理,包括数据仓库、数据集市、数据仓库监视、运行与维护工具和元数据管理等。
- 数据服务:为前端工具和应用提供数据服务,包括直接从数据仓库中获取数据提供给前端使用,或者通过
OLAP服务器为前端应用提供更为复杂的数据服务。 - 数据应用:直接面向最终用户,包括数据工具、自由报表工具、数据分析工具、数据挖掘工具和各类应用系统。
7.0.4 面临的挑战
随着大数据时代的全面到来,传统数据仓库也面临了如下挑战:
- 无法满足快速增长的海量数据存储需求
- 无法有效处理不同类型的数据
- 计算和处理能力不足
7.1 Hive基本概念

7.1.1 概述
Hive是建立在Hadoop之上的一种数仓工具。该工具的功能是将结构化、半结构化的数据文件映射为一张数据库表,基于数据库表,提供了一种类似SQL的查询模型(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive本身并不具备存储功能,其核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop集群中执行。

特点:
- 简单、容易上手(提供了类似
SQL的查询语言HiveQL),使得精通SQL却不了解Java编程的人也能很好地进行大数据分析; - 灵活性高,可以自定义用户函数(UDF)和存储格式;
- 为超大的数据集设计的计算和存储能力,集群扩展容易;
- 统一的元数据管理,可与
presto/impala/sparksql等共享数据; - 执行延迟高,不适合做数据的实时处理,但适合做海量数据的离线处理。
7.1.2 产生背景

Hive的产生背景主要有两个:
- 使用成本高:使用
MapReduce直接处理数据时,需要掌握Java等编程语言,学习成本较高,而且使用MapReduce不容易实现复杂查询; - 建立分析型数仓的需求:
Hive支持类SQL的查询以及支持自定义函数,可以作为数据仓库的工具。
Hive利用HDFS存储数据,使用MapReduce查询分析数据。将SQL转换为MapReduce程序,从而完成对数据的分析决策。

7.1.3 Hive与Hadoop生态系统
下图描述了当采用MapReduce作为执行引擎时,Hive与Hadoop生态系统中其他组件的关系。

- Hive与Hadoop生态的联系
HDFS作为高可靠的底层存储方式,可以存储海量数据。MapReduce对这些海量数据进行批处理,实现高性能计算。Hive架构位于MapReduce 、HDFS之上,其自身并不存储和处理数据,而是分别借助于HDFS和MapReduce实现数据的存储和处理,用HiveQL语句编写的处理逻辑,最终都要转换成MapReduce任务来运行。Pig可以作为Hive的替代工具,它是一种数据流语言和运行环境,适用于在Hadoop平台上查询半结构化数据集,常用于数据抽取(ETL)部分,即将外部数据装载到Hadoop集群中,然后转换为用户需要的数据格式。
- Hive与HBase的区别
HBase是一个面向列式存储、分布式、可伸缩的数据库,它可以提供数据的实时访问功能,而Hive只能处理静态数据,主要是BI报表数据。就设计初衷而言,在Hadoop上设计Hive,是为了减少复杂MapReduce应用程序的编写工作,在Hadoop上设计HBase是为了实现对数据的实时访问。所以,HBase与Hive的功能是互补的,它实现了Hive不能提供的功能。
7.1.4 Hive与传统数据库的对比
Hive在很多方面和传统数据库类似,但是,它的底层依赖的是HDFS和MapReduce(或Tez、Spark)。以下将从各个方面,对Hive和传统数据库进行对比分析。
| 对比内容 | Hive | 传统数据库 |
|---|---|---|
| 数据存储 | HDFS | 本地文件系统 |
| 索引 | 支持有限索引 | 支持复杂索引 |
| 分区 | 支持 | 支持 |
| 执行引擎 | MapReduce、Tez、Spark | 自身的执行引擎 |
| 执行延迟 | 高 | 低 |
| 扩展性 | 好 | 有限 |
| 数据规模 | 大 | 小 |
ps:看完了Hive的特点后,一定很好奇这东西的内部构造是啥吧,小伙伴们,请跟我来,坚持学习,沉迷学习,忘我学习,冲冲冲!!!
7.1.5 模拟实现Hive
这里通过一个简单的需求,来帮助我们更好地理解Hive的原理。
- 需求:在
HDFS文件系统上有一个文件,其内容如下:
1,jingjing,26,hangzhou 2,wenrui,26,beijing 3,dapeng,26,beijing 4,tony,15,hebei
需要根据上述文本内容来设计Hive数仓,通过这个数仓,实现用户通过编写SQL语句,来处理位于HDFS文件系统上的结构化数据,从而统计来自北京的年龄大于20的人数。
- 分析:写
SQL的前提是对表进行操作,而不能是针对文件。那么需要记录文件和表之间的对应关系,关系示意图如下:

要实现上图所示的文件和表的对应关系,关键在于实现表和文件的映射,那么需要记录的信息包括:
- 表是对应于哪个文件的,即表的位置信息;
- 表的列是对应文件的哪一个字段,即字段的位置信息;
- 文件字段之间的分隔符是什么,即内容读取时的分隔操作;
完成了表和文件的映射后,Hive需要对用户编写的SQL语句进行语法校验,并且根据记录的元数据信息对SQL进行解析,制定执行计划,并将执行计划转化为MapReduce程序来执行,最终将执行的结果封装返回给用户。
接下来,在Hive的核心概念中,我们进一步了解一下表和文件的映射信息。
7.2 Hive核心概念
7.2.1 Hive数据类型
- 基本数据类型
Hive表中的列支持以下基本数据类型:
| 大类 | 类型 |
|---|---|
| Integers(整型) | TINYINT:1字节的有符号整数; SMALLINT:2字节的有符号整数; INT:4字节的有符号整数; BIGINT:8字节的有符号整数 |
| Boolean(布尔型) | BOOLEAN:TRUE/FALSE |
| Floating point numbers(浮点型) | FLOAT:单精度浮点型; DOUBLE:双精度浮点型 |
| Fixed point numbers(定点数) | DECIMAL:用户自定义精度定点数,比如 DECIMAL(7,2) |
| String types(字符串) | STRING:指定字符集的字符序列; VARCHAR:具有最大长度限制的字符序列; CHAR:固定长度的字符序列 |
| Date and time types(日期时间类型) | TIMESTAMP:时间戳; TIMESTAMP WITH LOCAL TIME ZONE:时间戳,纳秒精度; DATE:日期类型 |
| Binary types(二进制类型) | BINARY:字节序列 |
注:
TIMESTAMP和TIMESTAMP WITH LOCAL TIME ZONE的区别如下:
- TIMESTAMP WITH LOCAL TIME ZONE:用户提交
TIMESTAMP给数据库时,会被转换成数据库所在的时区来保存。查询时,则按照查询客户端的不同,转换为查询客户端所在时区的时间。- TIMESTAMP :提交的时间按照原始时间保存,查询时,也不做任何转换。
- 隐式转换
Hive中基本数据类型遵循以下的层次结构,按照这个层次结构,子类型到祖先类型允许隐式转换。例如INT类型的数据允许隐式转换为BIGINT类型。额外注意的是:按照类型层次结构,允许将STRING类型隐式转换为DOUBLE类型。

- 复杂类型
| 类型 | 描述 | 示例 |
|---|---|---|
| STRUCT | 类似于对象,是字段的集合,字段的类型可以不同,可以使用名称.字段名方式进行访问 |
STRUCT('xiaoming', 12 , '2018-12-12') |
| MAP | 键值对的集合,可以使用名称[key]的方式访问对应的值 |
map('a', 1, 'b', 2) |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合,可以使用名称[index]访问对应的值 |
ARRAY('a', 'b', 'c', 'd') |
- 示例
下面是一个基本数据类型和复杂数据类型的使用示例:
CREATE TABLE students( name STRING, -- 姓名 age INT, -- 年龄 subject ARRAY<STRING>, -- 学科 score MAP<STRING,FLOAT>, -- 各个学科考试成绩 address STRUCT<houseNumber:int, street:STRING, city:STRING, province:STRING> -- 家庭居住地址 ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
7.2.2 Hive数据模型
Hive的数据都是存储在HDFS上的,默认有一个根目录,在hive-site.xml中可以进行配置数据的存储路径。Hive数据模型的含义是,描述Hive组织、管理和操作数据的方式。Hive包含如下4种数据模型:
-
库
MySQL中默认数据库是default,用户可以创建不同的database,在database下也可以创建不同的表。Hive也可以分为不同的数据(仓)库,和传统数据库保持一致。在传统数仓中创建database。默认的数据库也是default。Hive中的库相当于关系数据库中的命名空间,它的作用是将用户和数据库的表进行隔离。 -
表
Hive中的表所对应的数据是存储在HDFS中,而表相关的元数据是存储在关系数据库中。Hive中的表分为内部表和外部表两种类型,两者的区别在于数据的访问和删除:
- 内部表的加载数据和创建表的过程是分开的,在加载数据时,实际数据会被移动到数仓目录中,之后对数据的访问是在数仓目录实现。而外部表加载数据和创建表是同一个过程,对数据的访问是读取
HDFS中的数据; - 内部表删除时,因为数据移动到了数仓目录中,因此删除表时,表中数据和元数据会被同时删除。外部表因为数据还在
HDFS中,删除表时并不影响数据。 - 创建表时不做任何指定,默认创建的就是内部表。想要创建外部表,则需要使用
External进行修饰
| 对比内容 | 内部表 | 外部表 |
|---|---|---|
| 数据存储位置 | 内部表数据存储的位置由hive.Metastore.warehouse.dir参数指定,默认情况下,表的数据存储在 HDFS的/user/hive/warehouse/数据库名.db/表名/目录下 |
外部表数据的存储位置创建表时由Location参数指定 |
| 导入数据 | 在导入数据到内部表,内部表将数据移动到自己的数据仓库目录下, 数据的生命周期由 Hive来进行管理 |
外部表不会将数据移动到自己的数据仓库目录下, 只是在元数据中存储了数据的位置 |
| 删除表 | 删除元数据(metadata)和文件 | 只删除元数据(metadata) |
- 分区
分区是一个优化的手段,目的是减少全表扫描,提高查询效率。在Hive中存储的方式就是表的主目录文件夹下的子文件夹,子文件夹的名字表示所定义的分区列名字。 - 分桶
分桶和分区的区别在于:分桶是针对数据文件本身进行拆分,根据表中字段(例如,编号ID)的值,经过hash计算规则,将数据文件划分成指定的若干个小文件。分桶后,HDFS中的数据文件会变为多个小文件。分桶的优点是优化join查询和方便抽样查询。
7.3 Hive系统结构
Hive主要由用户接口模块、驱动模型以及元数据存储模块3个模块组成,其系统架构如下图所示:

7.3.1 用户接口模块
用户接口模块包括CLI、Hive网页接口(Hive Web Interface,HWI)、JDBC、ODBC、Thrift Server等,主要实现外部应用对Hive的访问。用户可以使用以下两种方式来操作数据:
- CLI(command-line shell):
Hive自带的一个命令行客户端工具,用户可以通过Hive命令行的方式来操作数据; - HWI(Thrift/JDBC):
HWI是Hive的一个简单网页,JDBC、ODBS和Thrift Server可以向用户提供编程访问的接口。用户可以按照标准的JDBC的方式,通过Thrift协议操作数据。
7.3.2 驱动模块
驱动模块(Driver)包括编译器、优化器、执行器等,所采用的执行引擎可以是 MapReduce、Tez或Spark等。当采用MapReduce作为执行引擎时,驱动模块负责把 HiveQL语句转换成一系列MapReduce作业,所有命令和查询都会进入驱动模块,通过该模块对输入进行解析编译,对计算过程进行优化,然后按照指定的步骤执行。
7.3.3 元数据存储模块
- 元数据:
元数据(metadata)是描述数据的数据,对于Hive来说,元数据就是用来描述HDFS文件和表的各种对应关系(位置关系、顺序关系、分隔符)。Hive的元数据存储在关系数据库中(Hive内置的是Derby、第三方的是MySQL),HDFS中存储的是数据。在Hive中,所有的元数据默认存储在Hive内置的Derby数据库中,但由于Derby只能有一个实例,也就是说不能有多个命令行客户端同时访问,所以在实际生产环境中,通常使用MySQL代替Derby。
元数据存储模块(Metastore)是一个独立的关系数据库,通常是与MySQL数据库连接后创建的一个MySQL实例,也可以是Hive自带的Derby数据库实例,提供元数据服务。元数据存储模块中主要保存表模式和其他系统元数据,如表的名称、表的列及其属性、表的分区及其属性、表的属性、表中数据所在位置信息等。它提供给Hive操作管理访问元数据的一个服务,具体操作为Metastore对外提供一个服务地址,使客户端能够连接Hive,以此来对元数据进行访问。使用Metastore的好处如下:- 元数据把数据保存在关系数据库中,
Hive提供元数据服务,通过对外的服务地址,用户能够使用客户端连接Hive,访问并操作元数据; - 支持多个客户端的连接,而客户端无需关心数据的存储地址,实现了数据访问层面的解耦操作。
- 因此如果你在
Hive上创建了一张表,然后在presto/impala/sparksql中都是可以直接使用的,它们会从Metastore中获取统一的元数据信息,同样的你在presto/impala/sparksql中创建一张表,在Hive中也可以直接使用。
- 元数据把数据保存在关系数据库中,

Metastore管理元数据的方式:
- 内嵌模式
Metastore默认的部署模式是Metastore元数据服务和Hive服务融合在一起。

在这种模式下,Hive服务(即Hive驱动本身)、元数据服务Metastore,元数据metadata(用于存储映射信息)都在同一个JVM进程中,元数据存储在内置的Derby数据库。当启动HiveServer进程时,Derby和Metastore都会启动,不需要额外启动Metastore服务。但是,一次只能支持一个用户访问,适用于测试场景。
- 本地模式
本地模式与内嵌模式的区别在于:把元数据提取出来,让Metastore服务与HiveServer主进程在同一个JVM进程中运行,存储元数据的数据库在单独的进程中运行。元数据一般存储在MySQL关系型数据库中。

但是,每启动一个Hive服务,都会启动一个Metastore服务。多个人使用时,会启用多个Metastore服务。
- 远程模式
既然可以把元数据存储给提取出来,也可以考虑把Metastore给提取出来变为单独一个进程。把Metastore单独进行配置,并在单独的进程中运行,可以保证全局唯一,从而保证数据访问的安全性。(即不随Hive的启动而启动)

其优点是把Metastore服务独立出来,可以安装到远程的服务器集群里,从而解耦Hive服务和Metastore服务,保证Hive的稳定运行。
7.3.4 HQL的执行流程
Hive在执行一条HQL语句时,会经过以下步骤:
- 语法解析:
Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree; - 语义解析:遍历
AST Tree,抽象出查询的基本组成单元QueryBlock; - 生成逻辑执行计划:遍历
QueryBlock,翻译为执行操作树OperatorTree; - 优化逻辑执行计划:逻辑层优化器进行
OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量; - 生成物理执行计划:遍历
OperatorTree,翻译为MapReduce任务; - 优化物理执行计划:物理层优化器进行
MapReduce任务的变换,生成最终的执行计划。
关于 Hive SQL 的详细工作原理可以参考美团技术团队的文章:HiveQL编译过程
7.4 Hive编程实战
7.4.1 实验一:Hive的安装部署和管理
7.4.1.1 实验准备
**实验环境:**Linux Ubuntu 22.04
前提条件:
- 完成Java运行环境部署(详见第2章Java安装)
- 完成Hadoop 3.3.1的单点部署(详见第2章安装单机版Hadoop)
7.4.1.2 实验内容
基于上述前提条件,学习并掌握Hive的安装部署和管理。
✅官网参考教程:GettingStarted
7.4.1.3 实验步骤
1.解压安装包
通过官网下载地址(✅官网下载地址:Hive下载),下载hive 2.3.9的安装包到本地指定目录,如/data/hadoop/下。(使用readme文件中提供的链接下载也可)解压安装包至/opt目录下,命令如下:
sudo tar -zxvf /data/hadoop/apache-hive-2.3.9-bin.tar.gz -C /opt/
解压后,在/opt目录下会产生apache-hive-2.3.9-bin文件夹。
2.更改文件夹名和所属用户
使用mv命令,将文件名改为hive,命令如下:
sudo mv /opt/apache-hive-2.3.9-bin/ /opt/hive
使用chown命令,更改文件夹及其下级的所有文件的所属用户和用户组,将其改为datawhale用户和datawhale用户组,命令如下:
sudo chown -R datawhale:datawhale /opt/hive/
3.设置HIVE_HOME环境变量
将HIVE_HOME环境变量设置为/opt/hive,作为工作目录,打开系统环境变量配置文件,命令如下:
sudo vim /etc/profile
在文件末尾,添加如下内容:
# hive export HIVE_HOME=/opt/hive export PATH=$PATH:$HIVE_HOME/bin
使用Shift+:,输入wq后回车,保存退出。运行下面命令使环境变量生效:
source /etc/profile
4.安装MySQL
在Ubuntu 22.04版本中,源仓库中MySQL的默认版本已经更新到8.0,因此可以直接安装,命令如下:
sudo apt-get update #更新软件源 sudo apt-get install mysql-server #安装mysql
默认情况下,MySQL是已经启动的,可以通过netstat -tap|grep mysql或systemctl status mysql命令查看(下面给出开启,关闭,重启命令),具体命令如下:
sudo netstat -tap | grep mysql #mysql节点处于LISTEN状态表示启动成功 sudo service mysql start #开启 sudo service mysql stop #关闭 sudo service mysql restart #重启
执行结果如下:

注意:安装时没有提示输入root账户密码,默认是空,可以执行以下命令设置密码为123456:
sudo mysql -u root -p #密码按Enter即可进入mysql shell,空格也可以,普通用户一定sudo
5.创建MySQL hive用户
登录mysql shell界面,请先确认已经启动,命令如下:
mysql -u root -p
创建datawhale用户,密码是123456,必须与hive-site.xml配置的user、password相同,并赋予权限,命令如下:
create user 'datawhale'@'localhost' identified by '123456'; -- 创建用户 grant all on *.* to 'datawhale'@'localhost'; -- 将所有数据库的所有表的所有权限赋给datawhale flush privileges; -- 刷新mysql系统权限关系表
6.下载安装MySQL JDBC
✅官网下载地址:MySQL JDBC下载
选择合适的系统以及系统版本,会自动出现最新的安装包,注意下载的是deb格式的,可以使用cpkg命令安装。这里选择Ubuntu Linux 22.04版本的Connector/J 8.0.32。

下载MySQL JDBC到本地的目录(如~/Download目录)下,并使用cpkg命令安装,命令如下:
cd ~/Download #切换到你的文件所在目录下 sudo dpkg -i mysql-connector-java_8.0.32-1ubuntu22.04_all.deb #安装mysql-connector-java
7.导入MySQL JDBC jar包到hive/lib目录下
使用cp命令,将jar包到/opt/hive/lib目录下,命令如下:
sudo cp /usr/share/java/mysql-connector-java-8.0.32.jar /opt/hive/lib/
注意:
你可能不知道安装到哪里了,别急,在
/usr/share/java/下面,会存在该jar包。
验证路径的方法:打开deb文件,提取文件,看到.tar.xz文件,使用xz -d命令解压,并使用tar -xvf解包,解压出来的文件目录路径就是在系统中的路径。
使用chown命令,更改jar包的所属用户和用户组,将其改为datawhale用户和datawhale用户组,命令如下:
sudo chown datawhale:datawhale /opt/hive/lib/mysql-connector-java-8.0.32.jar
8.修改hive配置文件
进入/opt/hive/conf目录下,将hive-default.xml.template文件重命名为hive-default.xml,命令如下:
cd /opt/hive/conf sudo mv hive-default.xml.template hive-default.xml
在当前目录(/opt/hive/conf)下,创建hive-site.xml文件,命令如下:
sudo touch hive-site.xml
使用vim命令,打开hive-site.xml文件,命令如下:
sudo vim hive-site.xml
添加内容如下:
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive_metadata?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC Metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> <description>Driver class name for a JDBC Metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>datawhale</value> <description>username to use against Metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> <description>password to use against Metastore database</description> </property> </configuration>
至此,Hive的配置已经完成了。
9.启动MySQL
使用service命令,启动MySQL,命令如下:
sudo service mysql start
使用systemctl命令,查看MySQL是否正常启动,命令如下:
systemctl status mysql
执行结果如下:
10.指定元数据数据库类型并初始化Schema
使用schematool命令,初始化Hive在MySQL上的Schema,命令如下:
schematool -initSchema -dbType mysql
初始化成功后,执行结果如下:

如果运行此步时报错,schematool:未找到命令...,需要重新source一下全局变量:
source /etc/profile
8.启动Hadoop
进入/opt/hadoop/bin目录,启动Hadoop,命令如下:
cd /opt/hadoop/sbin ./start-all.sh
使用jps命令检验hadoop是否启动成功,如果6个进程都启动,表示启动成功,执行结果如下:

9.启动Hive
执行hive命令,启动Hive,执行结果如下:

10.检验Hive是否成功部署
在hive shell命令行下,执行show databases;命令,显示已有的数据库,执行结果如下:

至此,Hive安装部署完成,本次实验结束啦!
7.4.2 实验二:Hive常用的DDL操作
7.4.2.1 实验准备
**实验环境:**Linux Ubuntu 22.04
前提条件:
- 完成Java运行环境部署(详见第2章Java安装)
- 完成Hadoop 3.3.1的单点部署,并正常启动(详见第2章安装单机版Hadoop)
- MySQL数据库安装完成,并正常启动(详见实验一)
- Hive单点部署完成,并正常启动(详见实验一)
7.4.2.2 实验内容
基于上述前提条件, 在hive shell命令行下,完成一些常见的DDL操作。(✅官方参考内容:LanguageManual DDL)
7.4.2.3 实验步骤
正常启动hive之后,可进入hive shell命令行,以下所有命令将在该环境下执行。
1.数据库操作
1.1 查看数据列表
使用如下命令,查看已有数据库:
show databases;
执行结果如下:

1.2 使用数据库
使用use命令,指定要使用的数据库,命令格式如下:
use <database_name>;
使用datawhale数据库,执行结果如下:

1.3 新建数据库
使用create database命令,新建数据库,命令格式如下:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name -- DATABASE|SCHEMA 是等价的 [COMMENT database_comment] -- 数据库注释 [LOCATION hdfs_path] -- 存储在HDFS上的位置 [WITH DBPROPERTIES (property_name=property_value, ...)]; -- 指定额外属性
创建hive_test数据库,命令如下:
CREATE DATABASE IF NOT EXISTS hive_test COMMENT 'hive database for test' WITH DBPROPERTIES ('create'='datawhale');
执行结果如下:

1.4 查看数据库信息
使用desc database命令,查看数据库信息,命令格式如下:
DESC DATABASE [EXTENDED] db_name; -- EXTENDED 表示是否显示额外属性
查看hive_test数据库信息,命令如下:
DESC DATABASE EXTENDED hive_test;
执行结果如下:

1.5 删除数据库
使用drop database命令,删除数据库,命令格式如下:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
注:默认行为是RESTRICT,如果数据库中存在该表,则删除失败。要想删除库及其中的表,可以使用CASCADE级联删除。
删除hive_test数据库,命令如下:
DROP DATABASE IF EXISTS hive_test CASCADE;
执行结果如下:

2.创建表
2.1 建表语法
使用create table命令,创建表,命令格式如下:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- 表名 [(col_name data_type [COMMENT col_comment], ... [constraint_specification])] -- 列名 列数据类型 [COMMENT table_comment] -- 表描述 [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] -- 分区表分区规则 [ CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS ] -- 分桶表分桶规则 [SKEWED BY (col_name, col_name, ...) ON ((col_value, col_value, ...), (col_value, col_value, ...), ...) [STORED AS DIRECTORIES] ] -- 指定倾斜列和值 [ [ROW FORMAT row_format] [STORED AS file_format] | STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] ] -- 指定行分隔符、存储文件格式或采用自定义存储格式 [LOCATION hdfs_path] -- 指定表的存储位置 [TBLPROPERTIES (property_name=property_value, ...)] -- 指定表的属性 [AS select_statement]; -- 从查询结果创建表
2.2 内部表
使用以下雇员表emp的字段信息,在Hive中创建内部表:
| 字段名称 | 字段类型 | 说明 |
|---|---|---|
| empno | INT | 员工编号 |
| ename | STRING | 员工姓名 |
| job | STRING | 员工工作 |
| mgr | INT | 领导编号 |
| hiredate | TIMESTAMP | 入职日期 |
| sal | DECIMAL(7,2) | 月薪 |
| comm | DECIMAL(7,2) | 奖金 |
| deptno | INT | 部门编号 |
使用create table创建emp内部表,命令如下:
CREATE TABLE emp( empno INT, empname STRING, job STRING, mgr INT, hiredate TIMESTAMP, sal DECIMAL(7,2), comm DECIMAL(7,2), deptno INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
执行结果如下:

hdfs文件系统中的存储位置如下:

2.3 外部表
使用create external table创建emp_external外部表,命令如下:
CREATE EXTERNAL TABLE emp_external( empno INT, ename STRING, job STRING, mgr INT, hiredate TIMESTAMP, sal DECIMAL(7,2), comm DECIMAL(7,2), deptno INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LOCATION '/datawhale/emp_external';
使用 desc emp_external 命令,查看emp_external表的详细信息,执行结果如下:

hdfs文件系统中的存储位置如下所示:

2.4 分区表
使用 partitioned语句,创建emp_partition分区表,命令如下:
CREATE EXTERNAL TABLE emp_partition( empno INT, ename STRING, job STRING, mgr INT, hiredate TIMESTAMP, sal DECIMAL(7,2), comm DECIMAL(7,2) ) PARTITIONED BY (deptno INT) -- 按照部门编号进行分区 ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LOCATION '/datawhale/emp_partition';
hdfs文件系统中的存储位置如下所示:

2.5 分桶表
使用clustered sorted into语句,创建emp_bucket分桶表,命令如下:
CREATE EXTERNAL TABLE emp_bucket( empno INT, ename STRING, job STRING, mgr INT, hiredate TIMESTAMP, sal DECIMAL(7,2), comm DECIMAL(7,2), deptno INT) CLUSTERED BY(empno) SORTED BY(empno ASC) INTO 4 BUCKETS -- 按照员工编号散列到四个 bucket 中 ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LOCATION '/datawhale/emp_bucket';
hdfs文件系统中的存储位置如下所示:
2.6 倾斜表
通过指定一个或者多个列经常出现的值(严重偏斜),Hive会自动将涉及到这些值的数据拆分为单独的文件。在查询时,如果涉及到倾斜值,它就直接从独立文件中获取数据,而不是扫描所有文件,这使得查询性能得到提升。
使用skewed语句,创建emp_skewed倾斜表,命令如下:
CREATE EXTERNAL TABLE emp_skewed( empno INT, ename STRING, job STRING, mgr INT, hiredate TIMESTAMP, sal DECIMAL(7,2), comm DECIMAL(7,2) ) SKEWED BY (empno) ON (66,88,100) -- 指定 empno 的倾斜值 66,88,100 ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LOCATION '/datawhale/emp_skewed';
hdfs文件系统中的存储位置如下所示:
2.7 临时表
临时表仅对当前session可见,临时表的数据将存储在用户的暂存目录中,并在会话结束后删除。如果临时表与永久表表名相同,则对该表名的任何引用都将解析为临时表,而不是永久表。临时表还具有以下两个限制:
- 不支持分区列;
- 不支持创建索引。
使用create temporary table命令,创建emp_temp临时表,命令如下:
CREATE TEMPORARY TABLE emp_temp( empno INT, ename STRING, job STRING, mgr INT, hiredate TIMESTAMP, sal DECIMAL(7,2), comm DECIMAL(7,2) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
2.8 CTAS创建表
使用create table as select语句形式,从查询语句的结果中创建表:
CREATE TABLE emp_copy AS SELECT * FROM emp WHERE deptno='20';
执行命令如下:
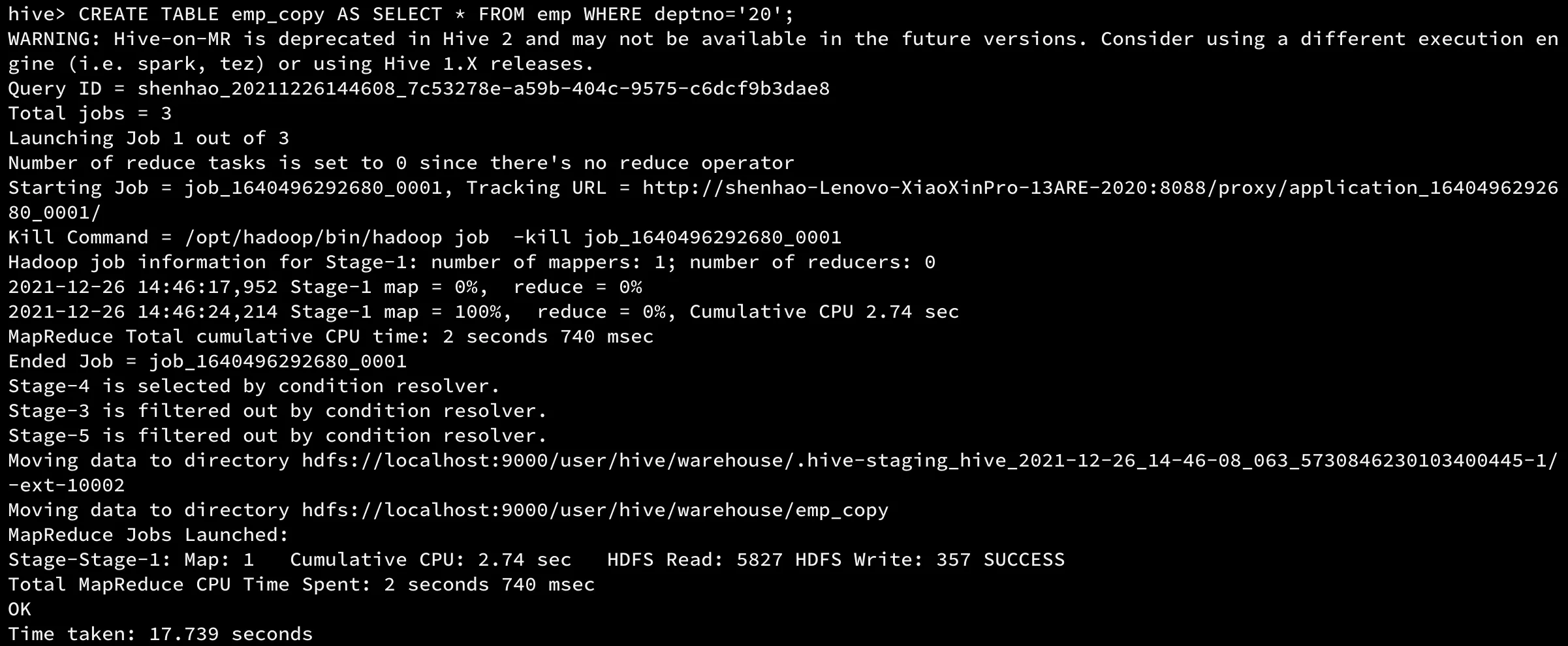

hdfs文件系统中的存储位置如下所示:

2.9 复制表结构
使用create like语句形式,复制一个表的表结构,命令格式如下:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- 创建表表名 LIKE existing_table_or_view_name -- 被复制表的表名 [LOCATION hdfs_path]; -- 存储位置
通过复制emp表,创建emp_co表,命令如下:
CREATE TEMPORARY EXTERNAL TABLE IF NOT EXISTS emp_co LIKE emp
执行结果如下:

注:临时表不存储在hdfs中。
2.10 加载数据到表
加载数据到表中属于DML操作,这里为了方便大家测试,先简单介绍一下加载本地数据到表中的命令,命令如下:
-- 加载数据到 emp 表中 load data local inpath "/home/datawhale/emp.txt" into table emp;
其中emp.txt的内容在本仓库的resources 目录下,具体内容如下:
7369 SMITH CLERK 7902 1980-12-17 00:00:00 800.00 20 7499 ALLEN SALESMAN 7698 1981-02-20 00:00:00 1600.00 300.00 30 7521 WARD SALESMAN 7698 1981-02-22 00:00:00 1250.00 500.00 30 7566 JONES MANAGER 7839 1981-04-02 00:00:00 2975.00 20 7654 MARTIN SALESMAN 7698 1981-09-28 00:00:00 1250.00 1400.00 30 7698 BLAKE MANAGER 7839 1981-05-01 00:00:00 2850.00 30 7782 CLARK MANAGER 7839 1981-06-09 00:00:00 2450.00 10 7788 SCOTT ANALYST 7566 1987-04-19 00:00:00 1500.00 20 7839 KING PRESIDENT 1981-11-17 00:00:00 5000.00 10 7844 TURNER SALESMAN 7698 1981-09-08 00:00:00 1500.00 0.00 30 7876 ADAMS CLERK 7788 1987-05-23 00:00:00 1100.00 20 7900 JAMES CLERK 7698 1981-12-03 00:00:00 950.00 30 7902 FORD ANALYST 7566 1981-12-03 00:00:00 3000.00 20 7934 MILLER CLERK 7782 1982-01-23 00:00:00 1300.00 10
加载后可使用select * from emp查询该表的数据,执行结果如下:

如果使用分区表加载数据,需要增加字段partition(deptno=30),或者可以修改hive的默认配置配置为动态分区,可以参考Hive数仓:操作分区表。
使用分区表加载emp.txt数据,命令如下:
load data local inpath "/home/datawhale/emp.txt" into table emp_partition partition(deptno=30);
hdfs文件系统中的存储位置如下所示:

3.修改表
3.1 重命名表
使用alter table rename语句,对表进行重命名,命令格式如下:
ALTER TABLE table_name RENAME TO new_table_name;
将emp_temp表重命名为new_emp表,命令如下:
ALTER TABLE emp_temp RENAME TO new_emp;
执行结果如下:

3.2 修改列
使用alter table change column语句,修改列的属性,命令格式如下:
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
修改new_emp表中的empno、sal、mgr字段属性,命令分别如下:
-- 修改字段名和类型 ALTER TABLE new_emp CHANGE empno empno_new INT; -- 修改字段 sal 的名称 并将其放置到 empno 字段后 ALTER TABLE new_emp CHANGE sal sal_new decimal(7,2) AFTER ename; -- 为字段增加注释 ALTER TABLE new_emp CHANGE mgr mgr_new INT COMMENT 'this is column mgr';
3.3 新增列
使用alter table add columns语句形式,在new_emp表中新增address列,命令如下:
ALTER TABLE new_emp ADD COLUMNS (address STRING COMMENT 'home address');
4.清空表/删除表
4.1 清空表
使用truncate table命令,清空整个表或表指定分区中的数据,命令格式如下:
-- 清空整个表或表指定分区中的数据 TRUNCATE TABLE table_name [PARTITION (partition_column = partition_col_value, ...)];
目前只有内部表才能执行TRUNCATE操作,外部表执行时会抛出异常Cannot truncate non-managed table。
清空emp_partition分区表,命令如下:
TRUNCATE TABLE emp_partition PARTITION (deptno=30);
4.2 删除表
使用drop table命令,删除表,命令格式如下:
DROP TABLE [IF EXISTS] table_name [PURGE];
注:
- 内部表:不仅会删除表的元数据,同时会删除
HDFS上的数据; - 外部表:只会删除表的元数据,不会删除
HDFS上的数据; - 删除视图引用的表时,不会给出警告(但视图已经无效了,必须由用户删除或重新创建)。
5.其他命令
5.1 describe
使用describe命令,查看数据库属性,命令格式如下:
DESCRIBE|Desc DATABASE [EXTENDED] db_name; -- EXTENDED 是否显示额外属性
查看datawhale库的属性,执行结果如下:

也可用于查看表的属性,命令格式如下:
DESCRIBE|Desc [EXTENDED|FORMATTED] table_name -- FORMATTED 以友好的展现方式查看表详情
查看emp表的属性,命令如下:
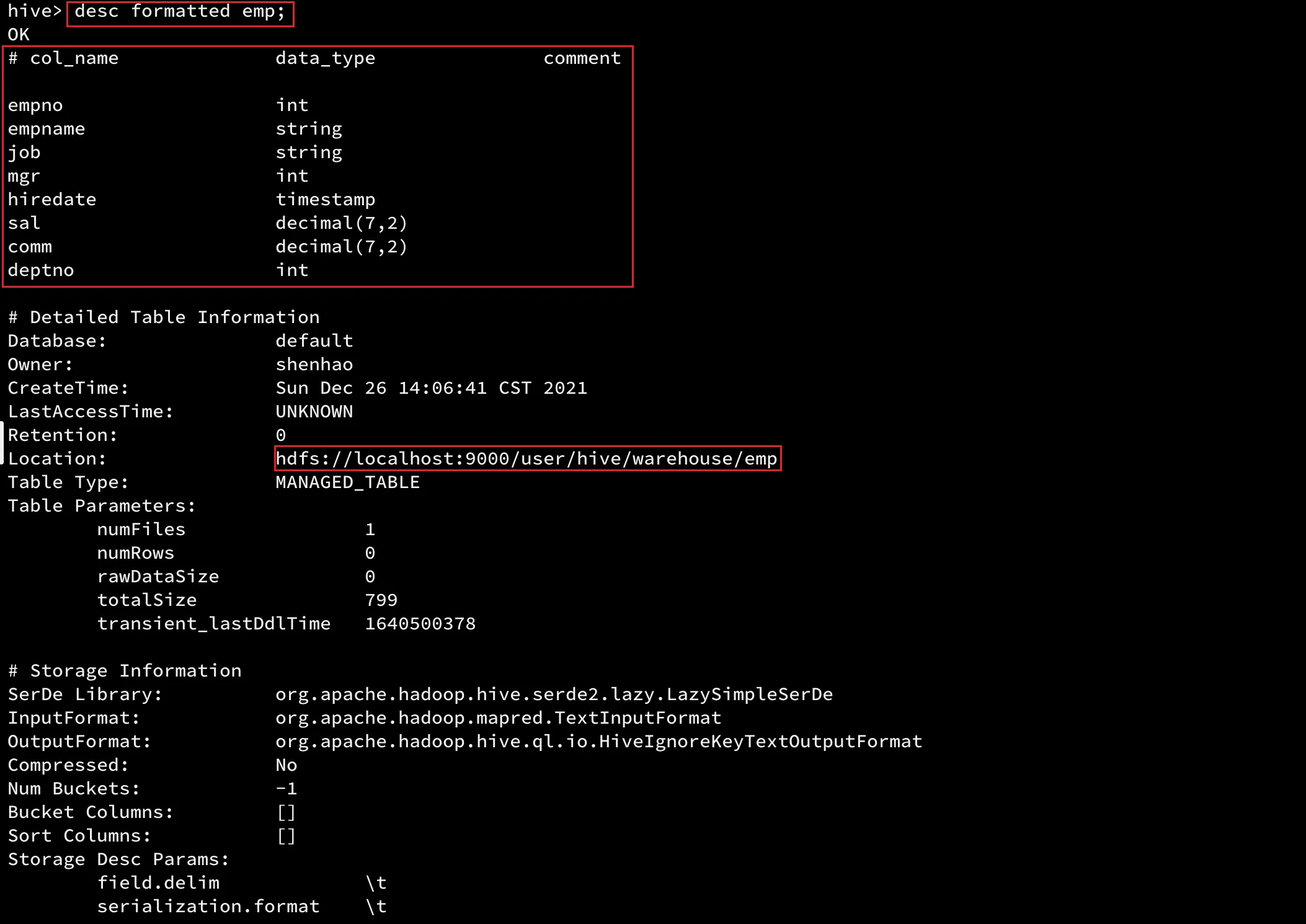
5.2 show
- 查看数据库列表
-- 语法 SHOW (DATABASES|SCHEMAS) [LIKE 'identifier_with_wildcards'];
以列表形式展示符合datawhale*规则的所有数据库,命令如下:
SHOW DATABASES like 'datawhale*';
LIKE子句允许使用正则表达式进行过滤,但是SHOW语句当中的LIKE子句只支持 *(通配符)和 |(条件或)两个符号。例如 employees,emp *,emp * | * ees,所有这些都将匹配名为employees的数据库。

- 查看表的列表
使用show tables命令,查看数据库下的所有表,命令格式如下:
-- 语法 SHOW TABLES [IN database_name] ['identifier_with_wildcards'];
展示datawhale库下的所有表,命令如下:
SHOW TABLES IN 'datawhale';
执行结果如下:

- 查看视图列表
使用show views命令,查看数据库下的所有视图,命令格式如下:
SHOW VIEWS [IN/FROM database_name] [LIKE 'pattern_with_wildcards']; -- 仅支持 Hive 2.2.0 +
- 查看表的分区列表
使用show partitions命令,查看表的所有分区表,命令格式如下:
SHOW PARTITIONS table_name;
- 查看表/视图的创建语句
使用show create table命令,查看表/视图的创建语句,命令格式如下:
SHOW CREATE TABLE ([db_name.]table_name|view_name);
7.5 本章小结
在本章的学习中,主要介绍了数据仓库和Hive的基本概念,并通过一个小示例,模拟实现Hive;还介绍了Hive的核心概念,主要包括7大类的Hive的数据类型和4个数据模型;通过讲解Hive的系统结构,结合之前学习过的MapReduce,介绍了HQL语句的执行流程;最后通过两个实验,分别介绍了Hive的安装和常用的DDL操作。
ps:多用脑,多思考,这一章内容很干,希望大家足够肝。
保护眼睛,保护头发,好好学习,天天向上
