第八章:Spark
文档摘要
第八章 Spark 王嘉鹏,shenhao 8.0 引言   我们再次拿出5.1章节中辣椒酱的demo(没印象的同学移步这里),来简单看下Spark和MapReduce在处理问题的方式上有什么区别。   在介绍这个之前,必须要了解什么是内存和磁盘。内存和磁盘两者都是存储设备,但内存储存的是我们正在使用的资源,磁盘储存的是我们暂时用不到的资源。可以把磁盘理解为一个仓库,而内存是进出这个仓库的通道。仓库(磁盘)很大,而通道(内存)很小,通道就很容易塞满。
第八章 Spark
王嘉鹏,shenhao
8.0 引言
我们再次拿出5.1章节中辣椒酱的demo(没印象的同学移步这里),来简单看下Spark和MapReduce在处理问题的方式上有什么区别。
在介绍这个之前,必须要了解什么是内存和磁盘。内存和磁盘两者都是存储设备,但内存储存的是我们正在使用的资源,磁盘储存的是我们暂时用不到的资源。可以把磁盘理解为一个仓库,而内存是进出这个仓库的通道。仓库(磁盘)很大,而通道(内存)很小,通道就很容易塞满。
假设把磁盘作为冰箱,内存为做饭时的操作台:
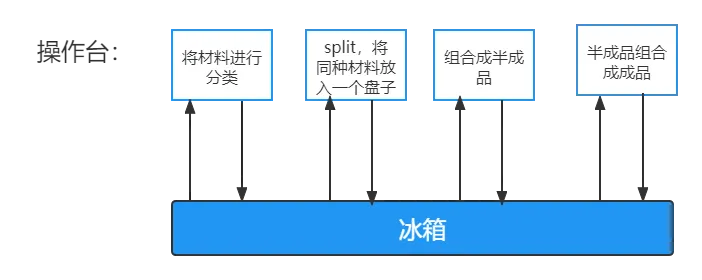
MapReduce每一个步骤发生在内存中,但产生的中间值(溢写文件)都会写入在磁盘里,下一步操作时又会将这个中间值merge到内存中,如此循环直到最终完成计算。
而对于Spark,每个步骤也是发生在内存之中,但产生的中间值会直接进入下一个步骤,直到所有的步骤完成之后才会将最终结果保存进磁盘。所以在使用Spark做数据分析时,较少进行很多次相对没有意义的读写,节省大量的时间。当计算步骤很多时,Spark的优势就体现出来了。

8.1 Spark概述
8.1.1 Spark诞生
在Hadoop出现之前,分布式计算都是专用系统,只能用来处理某一类的计算,比如进行大规模的排序。这样的系统无法复用到其他大数据计算场景。
而Hadoop MapReduce出现后,使得大数据计算通用编程成为可能,只要遵循MapReduce编程模型编写业务处理代码,就可以运行在Hadoop分布式集群上,而无需关心分布式计算是怎样完成的。
紧接着,我们经常看到的说法是:“MapReduce虽然已经可以满足大数据的应用场景,但是其执行速度和编程复杂度并不让人们满意。于是AMP lab的Spark应运而生”。
从事后因果规律的分析上,往往容易把结果当作了原因 ——觉得是因为MapReduce执行的很慢,所以才去发明和使用Spark。但事实上,在Spark出现之前,MapReduce并没有让人怨声载道。一方面,Hive这些工具将常用的MapReduce编程进行了封装,转化为了更易于编写的SQL形式;另一方面,MapReduce已经将分布式编程极大地进行了简化。
而当Spark出现后,性能比MapReduce快了100多倍。因为有了Spark,才对MapReduce不满,才觉得MapReduce慢。而不是觉得MapReduce慢,所以诞生了Spark。真实世界中的因果关系并非是顺承的,我们常常意识不到问题的存在,直到有大神解决了这些问题。
附上Spark框架发展历史中重要的时间点:

8.1.2 Spark与Hadoop、MapReduce、HDFS的关系
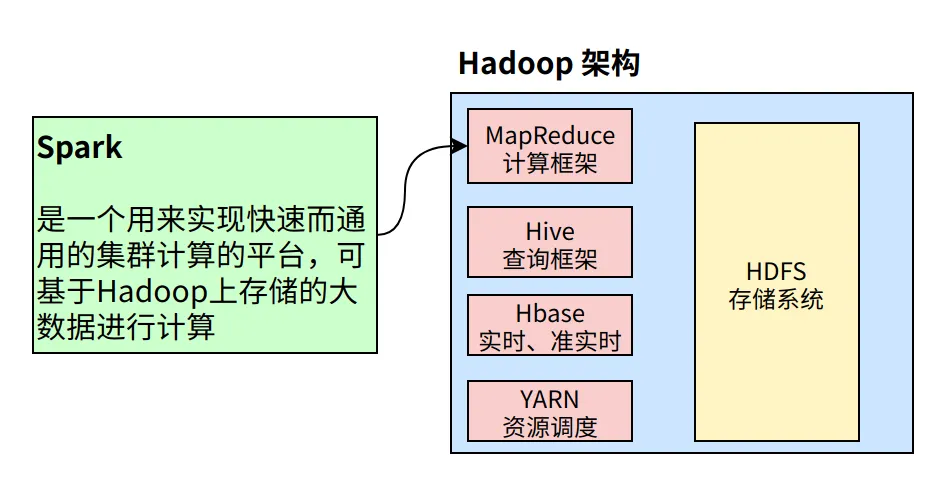
那接下来的问题是:Spark自己有自己的体系,那么其和Hadoop之间的关系是什么呢?
我们先来回忆一下Hadoop处理大数据的流程:首先从HDFS读取输入数据;接着在 Map 阶段使用用户定义的mapper function;然后把结果写入磁盘;在Reduce阶段,从各个处于Map阶段的机器中读取Map计算的中间结果,使用用户定义的reduce function,最后把结果写回HDFS。
在这个过程中, 至少进行了三次数据读写,Hadoop处理大数据的流程高度依赖磁盘读写,那么在数据处理上就出现了瓶颈,面对更复杂的计算逻辑的处理任务时,Hadoop存在很大局限性。
Spark在这样的背景下产生,它不像Hadoop一样采取磁盘读写,而是基于性能更高的内存存储来进行数据存储和读写(这里说的是计算数据的存储,而非持久化的存储)。但是Spark并非完美,缺乏对数据存储这一块的支持,即没有分布式文件系统,必须依赖外部的数据源,这个依赖可以是Hadoop系统的HDFS,也可以是其他的分布式文件系统,甚至可以是MySQL或本地文件系统。
基于以上分析,我们可以得出结论:Hadoop和Spark两者都是大数据框架,但是各自存在的目的不同。Hadoop实质上是一个分布式数据基础设施,它将巨大的数据集分派到一个集群中的多个节点进行存储,并具有计算处理的功能。Spark则不会进行分布式数据的存储,是计算分布式数据的工具,可以部分看做是MapReduce的竞品(准确的说是SparkCore)。综上所示,见下图:
8.1.3 Spark生态体系
Spark是一个用来实现快速且通用的集群计算平台,主要表现在以下两个方面:
- 速度方面:Spark的一个主要特点是能够在内存中进行计算,因此,速度要比MapReduce计算模型更加高效,可以面向海量数据进行分析处理;
- 通用方面:Spark框架可以针对任何业务类型分析进行处理,比如
SparkCore离线批处理、SparkSQL交互式分析、SparkStreaming和StructuredStreamig流式处理及机器学习和图计算都可以完成;
以Spark为基础,有支持SQL语句的SparkSQL,有支持流计算的Spark Streaming,有支持机器学习的MLlib,还有支持图计算的GraphX。
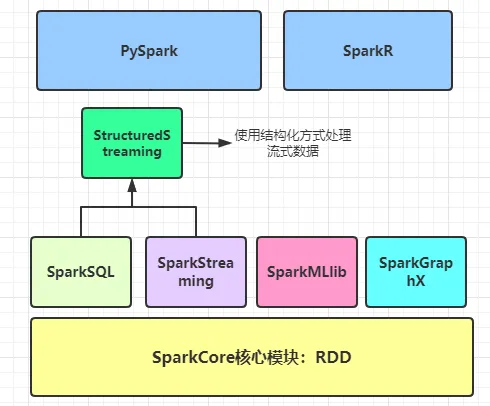
利用这些产品,Spark技术栈支撑了大数据分析、大数据机器学习等各种大数据应用场景。
8.2 Spark编程模型
8.2.1 RDD概述
RDD是Spark的核心概念,是弹性数据集(Resilient Distributed Datasets)的缩写。RDD既是Spark面向开发者的编程模型,又是Spark自身架构的核心元素。
大数据计算就是在大规模的数据集上进行一系列的数据计算处理。类比MapReduce,针对输入数据,将计算过程分为两个阶段,Map阶段和Reduce阶段,可以理解成是面向过程的大数据计算。我们在用MapReduce编程的时候,思考的是,如何将计算逻辑用 Map和Reduce两个阶段实现,map和reduce函数的输入和输出是什么。
而Spark则直接针对数据进行编程,将大规模数据集合抽象成一个RDD对象,然后在这个RDD上进行各种计算处理,得到一个新的RDD,并继续计算处理,直至得到最后的数据结果。所以,Spark可以理解成是面向对象的大数据计算。我们在进行Spark编程的时候,主要思考的是一个RDD对象需要经过什么样的操作,转换成另一个RDD对象,思考的重心和落脚点都在RDD上。
8.2.2 RDD定义
RDD是分布式内存的一个抽象概念,是只读的记录分区集合,能横跨集群所有节点进行并行计算。Spark建立在抽象的RDD上,可用统一的方式处理不同的大数据应用场景,把所有需要处理的数据转化为RDD,然后对RDD进行一系列的算子运算,通过丰富的API来操作数据,从而得到结果。
8.2.3 RDD五大特性
RDD共有五大特性,我们将对每一种特性进行介绍:
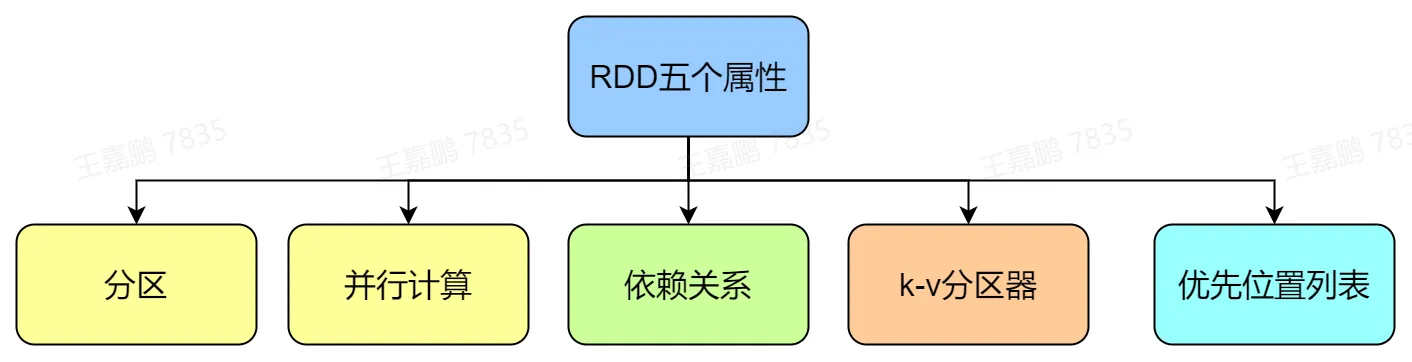
一、分区
分区的含义是允许Spark将计算以分区为单位,分配到多个机器上并行计算。在某些情况下,比如从HDFS读取数据时,Spark会使用位置信息,将计算工作发给靠近数据的机器,减少跨网络传输的数据量。
二、可并行计算
RDD的每一个分区都会被一个计算任务(Task)处理,每个分区有计算函数(具体执行的计算算子),计算函数以分片为基本单位进行并行计算,RDD的分区数决定着并行计算的数量。
三、依赖关系
依赖关系列表会告诉Spark如何从必要的输入来构建RDD。当遇到错误需要重算时,Spark可以根据这些依赖关系重新执行操作,以此来重建RDD。依赖关系赋予了RDD的容错机制。
四、Key-Value数据的RDD分区器
想要理解分区器的概念,我们需要先来比较一下MapReduce的任务机制。MapReduce任务的Map阶段,处理结果会进行分片(也可以叫分区,这个分区不同于上面的分区),分片的数量就是Reduce Task的数量。而具体分片的策略由分区器Partitioner决定,Spark目前支持Hash分区(默认分区)和Range分区,用户也可以自定义分区。
总结一下,Partitioner决定了RDD如何分区。通过Partitioner来决定下一步会产生并行的分片数,以及当前并行Shuffle输出的并行数据,使得Spark可以控制数据在不同节点上分区。
值得注意的是,其本身只针对于key-value的形式(key-value形式的RDD才有Partitioner属性),Partitioner会从0到numPartitions-1区间内映射每一个key到partition ID上。
五、每个分区都有一个优先位置列表
大数据计算的基本思想是:"移动计算而非移动数据"。Spark本身在进行任务调度时,需要尽可能的将任务分配到处理数据的数据块所在的具体位置。因此在具体计算前,就需要知道它运算的数据在什么地方。所以,分区位置列表会存储每个Partition的优先位置,如果读取的是HDFS文件,这个列表保存的就是每个分区所在的block块的位置。
8.2.4 RDD操作函数
RDD的操作函数包括两种:转换(transformation)函数和执行(action)函数。一种是转换(transformation)函数,这种函数的返回值还是RDD;另一种是执行(action)函数,这种函数不返回RDD。
RDD中定义的转换操作函数有:用于计算的map(func)函数、用于过滤的filter(func)函数、用于合并数据集的union(otherDataset)函数、用于根据key聚合的reduceByKey(func, [numPartitions])函数、用于连接数据集的join(otherDataset, [numPartitions])函数、用于分组的groupByKey([numPartitions])函数等。
跟MapReduce一样,Spark也是对大数据进行分片计算,Spark分布式计算的数据分片、任务调度都是以RDD为单位展开的,每个RDD分片都会分配到一个执行进程中进行处理。RDD上的转换操作分成两种:
- 转换操作产生的RDD不会出现新的分片,比如
map、filter等操作。一个RDD数据分片,经过map或者filter转换操作后,其结果还在当前的分片中。就像用map函数对每个数据加1,得到的还是这样一组数据,只是值不同。实际上,Spark并不是按照代码写的操作顺序生成RDD,比如rdd2 = rdd1.map(func)这样的代码并不会在物理上生成一个新的RDD。物理上,Spark只有在产生新的RDD分片时候,才会真的生成一个RDD,Spark的这种特性也被称作惰性计算; - 转换操作产生的RDD会产生新的分片,比如
reduceByKey,来自不同分片的相同key必须聚合在一起进行操作,这样就会产生新的RDD分片。实际执行过程中,是否会产生新的RDD分片,并不是根据转换函数名就能判断出来的。
8.3 Spark架构原理
Spark和MapReduce一样,也遵循着 移动计算而非移动数据这一大数据计算基本原则。MapReduce通过固定的map与reduce分阶段计算,而Spark的计算框架通过DAG来实现计算。
8.3.1 Spark计算阶段
MapReduce中,一个应用一次只运行一个map和一个reduce,而Spark可以根据应用的复杂程度,将过程分割成更多的计算阶段(stage),这些计算阶段组成一个有向无环图(DAG),Spark任务调度器根据DAG的依赖关系执行计算阶段(stage)。
Spark比MapReduce快100 多倍。因为某些机器学习算法可能需要进行大量的迭代计算,产生数万个计算阶段,这些计算阶段在一个应用中处理完成,而不是像MapReduce那样需要启动数万个应用,因此极大地提高了运行效率。
DAG是有向无环图,即是说不同阶段的依赖关系是有向的,计算过程只能沿着依赖关系方向执行,被依赖的阶段执行完成之前,依赖的阶段不能开始执行,同时,这个依赖关系不能是环形依赖,否则就造成死循环。下面这张图描述了一个典型的Spark运行DAG的不同阶段:
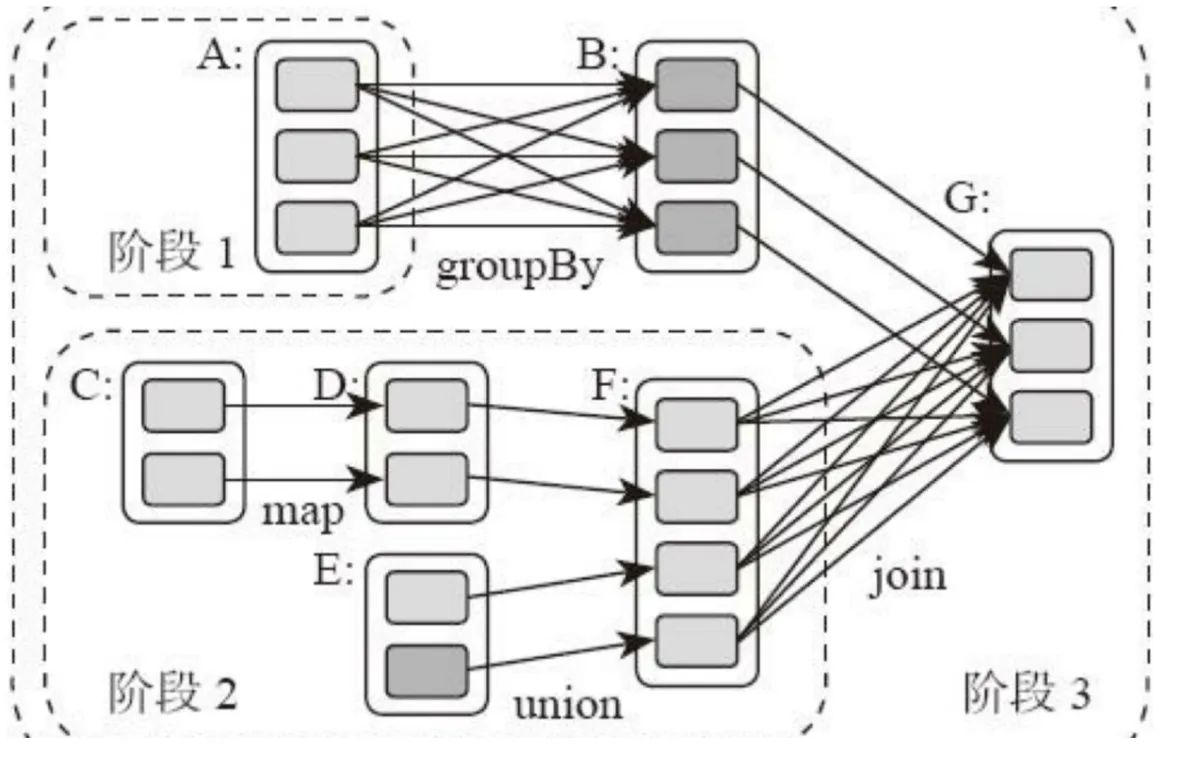
从图上看,整个应用被切分成3个阶段,阶段3需要依赖阶段1和阶段2,阶段1和阶段2互不依赖。Spark在执行调度时,先执行阶段1和阶段2,完成以后再执行阶段3。如果有更多的阶段,Spark的策略是一样的。Spark大数据应用的计算过程为:Spark会根据程序初始化DAG,由DAG再建立依赖关系,根据依赖关系顺序执行各个计算阶段。
Spark 作业调度执行核心是DAG,由DAG可以得出 整个应用就被切分成哪些阶段以及每个阶段的依赖关系。再根据每个阶段要处理的数据量生成相应的任务集合(TaskSet),每个任务都分配一个任务进程去处理。
那DAG是怎么来生成的呢?在Spark中,DAGScheduler组件负责应用DAG的生成和管理,DAGScheduler会根据程序代码生成DAG,然后将程序分发到分布式计算集群,按计算阶段的先后关系调度执行。
8.3.2 如何划分计算阶段
上图的DAG对应Spark伪代码可以表示为:
rddB = rddA.groupBy(key) rddD = rddC.map(func) rddF = rddD.union(rddE) rddG = rddB.join(rddF)
可以看到,共有4个转换函数,但是只有3个阶段。看起来并不是RDD上的每个转换函数都会生成一个计算阶段。那RDD的计算阶段是怎样来进行划分的呢?
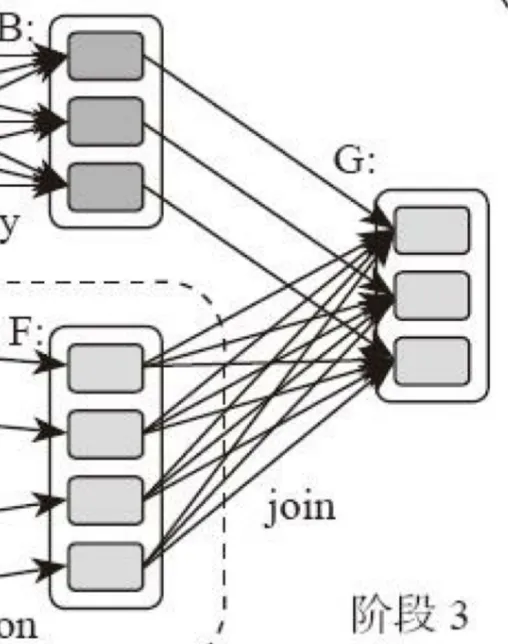
再看下上图,我们发现了一个规律,当 RDD之间的转换连接线呈现多对多交叉连接的时候,就会产生新的阶段。图中每个RDD里面都包含多个小块,每个小块都表示RDD的一个分片。
一个RDD表示一个数据集,一个数据集中的多个数据分片需要进行分区传输,写入到另一个数据集的不同分片中。这种涉及到数据分区交叉传输的操作,是否在MapReduce中也有印象?我们来回忆下MapReduce的过程:

MapReduce把这种从数据集跨越,由多个分区传输的过程,叫做Shuffle。同样,Spark也需要通过Shuffle将数据进行重新组合,把相同key的数据放一起。由于会进行新的聚合、关联等操作,所以Spark每次Shuffle都会产生新的计算阶段。而每次计算时,需要的数据都是由前面一个或多个计算阶段产生的,所以计算阶段需要依赖关系,必须等待前面的阶段执行完毕后,才能进行Shuffle。
Spark中计算阶段划分的依据是Shuffle,而不是操作函数的类型,并不是所有的函数都有Shuffle过程。比如Spark计算阶段示例图中,RDD B和RDD F进行join后,得到RDD G。RDD B不需要Shuffle,因为RDD B在上一个阶段中,已经进行了数据分区,分区数和分区key不变,就不需要进行Shuffle。而RDD F的分区数不同,就需要进行Shuffle。Spark把不需要Shuffle的依赖,称为窄依赖。需要Shuffle的依赖,称为宽依赖。Shuffle是Spark最重要的一个环节,只有通过Shuffle,相关数据才能互相计算,从而构建起复杂的应用逻辑。
那么Spark和MapReduce一样,都进行了Shuffle,为什么Spark会比MapReduce更高效呢? 我们从本质和存储方式两个方面,对Spark和MapReduce进行比较:
-
从本质上:Spark可以算是一种MapReduce计算模型的不同实现,Hadoop MapReduce根据
Shuffle将大数据计算分为Map和Reduce两个阶段。而Spark更流畅,将前一个的Reduce和后一个的Map进行连接,当作一个阶段进行计算,从而形成了一个更高效流畅的计算模型。其本质仍然是Map和Reduce。但是这种多个计算阶段依赖执行的方案可以有效减少对HDFS的访问(落盘),减少作业的调度执行次数,因此执行速度也更快。 -
从存储方式上:MapReduce主要使用磁盘存储
Shuffle过程的数据,而Spark优先使用内存进行数据存储(RDD也优先存于内存)。这也是Spark比Hadoop性能高的另一个原因。
8.3.3 Spark 作业管理
本小节主要说明作业、计算阶段、任务的依赖和时间先后关系。
Spark的RDD有两种函数:转换函数和action函数。action函数调用之后不再返回RDD。Spark的DAGScheduler遇到Shuffle时,会生成一个计算阶段,在遇到action函数时,会生成一个作业(Job)。RDD里的每个数据分片,Spark都会创建一个计算任务进行处理,所以,一个计算阶段会包含多个计算任务(Task)。
一个作业至少包含一个计算阶段,每个计算阶段由多个任务组成,这些任务(Task)组成一个任务集合。
DAGScheduler根据代码生成DAG图,Spark的任务调度以任务为单位进行分配,将任务分配到分布式集群的不同机器上进行执行。
8.3.4 Spark 执行过程
Spark支持多种部署方案(Standalone、Yarn、Mesos等),不同的部署方案核心功能和运行流程基本一样,只是不同组件角色命名不同。
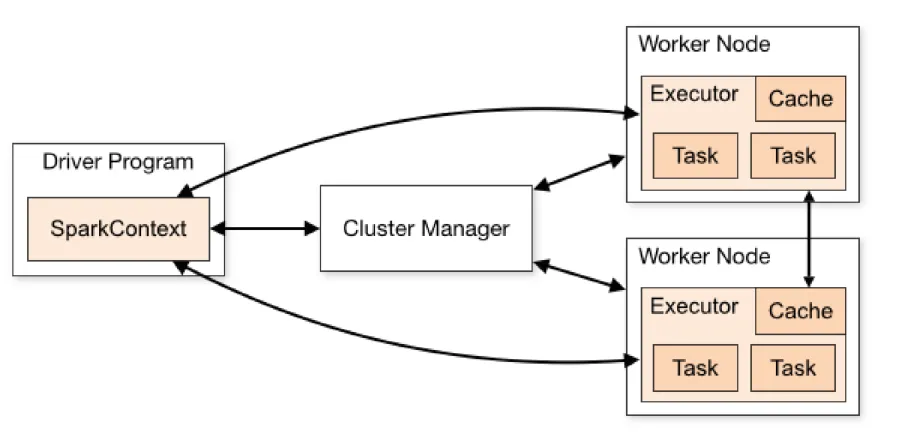
首先,Spark在自己的JVM进程里启动应用程序,即Driver进程。启动后,Driver调用SparkContext初始化执行配置和输入数据。再由SparkContext启动DAGScheduler构造执行的DAG图,切分成计算任务这样的最小执行单位。
接着,Driver向Cluster Manager请求计算资源,用于DAG的分布式计算。ClusterManager收到请求以后,将Driver的主机地址等信息通知给集群的所有计算节点Worker。
最后,Worker收到信息后,根据Driver的主机地址,向Driver通信并注册,然后根据自己的空闲资源向Driver通报可以领用的任务数。Driver根据DAG图向注册的Worker分配任务。
8.4 Spark 编程实战
8.4.1 实验一:Spark Local模式的安装
8.4.1.1 实验准备
**实验环境:**Linux Ubuntu 22.04
前提条件:
- 完成Java运行环境部署(详见第2章Java安装)
- 完成Hadoop 3.3.1的单点部署(详见第2章安装单机版Hadoop)
8.4.1.2 实验内容
基于上述前提条件,完成Spark Local模式的安装。
✅厦门大学数据库实验室参考教程:GettingStarted
8.4.1.3 实验步骤
1.解压安装包
通过官网下载地址(✅官网下载地址:Spark下载),下载spark-3.2.0-bin-without-hadoop.tgz。
将安装包放置本地指定目录,如/data/hadoop/下。解压安装包至/opt目录下,命令如下:
sudo tar -zxvf /data/hadoop/spark-3.2.0-bin-without-hadoop.tgz -C /opt/
解压后,在/opt目录下会产生spark-3.2.0-bin-without-hadoop文件夹。
2.更改文件夹名和所属用户
使用mv命令,将文件名改为spark,命令如下:
sudo mv /opt/spark-3.2.0-bin-without-hadoop/ /opt/spark
使用chown命令,更改文件夹及其下级的所有文件的所属用户和用户组,将其改为datawhale用户和datawhale用户组,命令如下:
sudo chown -R datawhale:datawhale /opt/spark/
3.修改Spark的配置文件spark-env.sh
进入/opt/spark/conf目录下,将spark-env.sh.template文件拷贝一份并命名为spark-env.sh,命令如下:
cd /opt/spark/conf cp ./spark-env.sh.template ./spark-env.sh
编辑spark-env.sh文件,命令如下:
vim spark-env.sh
在第一行添加如下配置信息:
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/bin/hadoop classpath)
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
4.设置Spark的环境变量
将SPARK_HOME环境变量设置为/opt/spark,作为工作目录,打开系统环境变量配置文件,命令如下:
sudo vim /etc/profile
在文件末尾,添加如下内容:
# spark export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin
使用Shift+:,输入wq后回车,保存退出。运行如下命令使环境变量生效:
source /etc/profile
5.检验Spark是否成功部署
通过运行Spark自带的示例,验证Spark是否安装成功,命令如下:
cd /opt/spark bin/run-example SparkPi
执行时会输出非常多的运行信息,输出结果不容易找到,可以通过grep命令进行过滤(命令中的2>&1可以将所有的信息都输出到stdout中,否则由于输出日志的性质,还是会输出到屏幕中),命令如下:
cd /opt/spark bin/run-example SparkPi 2>&1 | grep "Pi is"
过滤后的运行结果如下,可以得到\pi的5位小数近似值:

至此,Spark安装部署完成,本次实验结束啦!
8.4.2 实验二:通过WordCount观察Spark RDD执行流程
8.4.2.1 实验准备
**实验环境:**Linux Ubuntu 22.04
前提条件:
- 完成Java运行环境部署(详见第2章Java安装)
- 完成Hadoop 3.3.1的单点部署(详见第2章安装单机版Hadoop)
- 完成Spark Local模式的部署(详见本章Spark Local模式的安装)
8.4.2.2 实验内容
基于上述前提条件,通过WordCount观察Spark RDD执行,进一步理解Spark RDD的执行逻辑。
8.4.2.3 实验步骤
WordCount在MapReduce章节(第5章5.3节)已经提过。这里再次学习WordCount的案例(编写单词记数代码),从数据流动的角度来详细了解Spark RDD是如何进行数据处理的。
1.文本数据准备
首先需要进入spark安装目录:
cd /opt/spark

建立一个文本文件helloSpark.txt,将该文件放到文件目录 data/wordcount/中,文本内容如下:
Hello Spark Hello Scala Hello Hadoop Hello Flink Spark is amazing

2.本地模式启动spark-shell
通过进入bin目录,启动spark-shell的本地环境,指定核数为2个
bin/spark-shell --master local[2]

3.创建SparkContext对象
SparkContext是Spark程序所有功能的唯一入口。不管是使用scala,还是python语言编程,都必须有一个SparkContext。
Spark-shell中会默认为我们创建了SparkContext入口,无需再进行创建。后续可以直接用sc来进行编码。
如果你并未通过spark-shell,创建SparkContext的方法如下:(使用spark-shell的可以跳过这段)
// 首先 import 必要的包,否则会报错 import org.apache.spark.SparkConf import org.apache.spark.SparkContext val conf = new SparkConf() // 创建SparkConf对象 conf.setAppName("First Spark App") //设置app应用名称,在程序运行的监控解面可以看到名称 conf.setMaster("local") //本地模式运行 val sc = new SparkContext(conf) // 创建SparkContext对象,通过传入SparkConf实例来定制Spark运行的具体参数和配置信息
SparkContext的核心作用:初始化Spark应用程序,运行所需要的核心组件,包括DAGScheduler、TaskScheduler、SchedulerBackend,同时还会负责Spark向Master注册等,SparkContext是整个Spark应用程序中至关重要的一个对象。
4.创建RDD
根据具体的数据来源,如HDFS,通过SparkContext来创建RDD。创建的方式有三种:根据外部数据源、根据Scala集合、由其他的RDD操作转换。数据会被RDD划分为一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴,具体代码如下:
val lines = sc.textFile("file:///opt/spark/data/wordcount/helloSpark.txt", 1) // 读取本地文件并设置为一个Partition //也可以将helloSpark.txt上传到hdfs中,直接读取hdfs中的文件,此时path路径不需要加"file://"前缀
5.对数据进行转换处理
对初始的RDD进行transformation级别的处理,如通过map、filter等高阶函数编程,进行具体的数据计算。
- 将每一行的字符串拆分为单个单词
val words = lines.flatMap{line => line.split(" ")} // 把每行字符串进行单词拆分,把拆分结果通过flat合并为一个大的单词集合
- 在单词拆分的基础上对每个单词实例计数为1,也就是word ->(word, 1)
val pairs = words.map{word => (word, 1)}
- 在每个单词实例计数为1基础之上统计每个单词在文件中出现的总次数
val wordCountOdered = pairs.reduceByKey(_+_).map(pair=>(pair._2, pair._1)).sortByKey(false).map(pair => (pair._2, pair._1))
6.打印数据
打印每个单词在文件中出现的次数,具体代码如下:
wordCountOdered.collect.foreach(wordNumberPair => println(wordNumberPair._1 + ":" + wordNumberPair._2))
执行结果如下:

8.4.2.4 WordCount在RDD的运行原理
1.textFile操作

在textFile操作之后,产生了两个RDD:HadoopRDD 和 MapPartitionRDD。
-
HadoopRDD
先产生HadoopRDD的原因是先从HDFS中抓取数据,导致先产生HadoopRDD。HadoopRDD会从HDFS上读取分布式文件,并将输入文件以数据分片的方式存在于集群中。数据分片就是把要处理的数据分成不同的部分。
例如,集群现在有4个节点,将数据分成4个数据分片(当然,这是一种粗略的划分),“Hello Spark"在第1台机器,"Hello Hadoop"在第2台机器,"Hello Flink“在第3台机器,”Spark is amazing“在第4台机器。HadoopRDD会从磁盘上读取数据,在计算的时候将数据以分布式的方式存储在内存中。
在默认情况下,Spark分片的策略是分片的大小与存储数据的Block块的大小是相同的。假设现在有4个数据分片(partition),每个数据分片有128M左右。这里描述为"左右"的原因是分片记录可能会跨越两个Block来存储,如果最后一条数据跨了两个Block块,那么分片的时候会把最后一条数据都放在前面的一个分片中,此时分片大小会大于128M(Block块大小)。 -
MapPartitionsRDD
MapPartitionsRDD是基于HadoopRDD产生的RDD,MapPartitionsRDD将HadoopRDD产生的数据分片((partition) 去掉相应行的key,只留value。 产生RDD的个数与操作并不一一对应。在textFile操作产生了2个RDD,Spark中一个操作可以产生一个或多个RDD。
2.flatMap操作

flatMap操作产生了一个MapPartitionsRDD,其作用是对每个Partition中的每一行内容进行单词切分,并合并成一个大的单词实例的集合。
3.map操作

map操作产生了一个MapPartitionsRDD,其作用是在单词拆分的基础上,对单词计数为1。例如将“Hello”和“Spark“变为(Hello, 1),(Spark, 1)。
4.reduceByKey操作
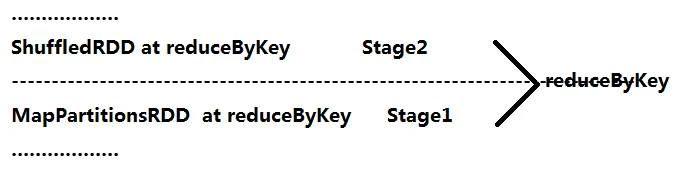
reduceByKey操作是对相同key进行value的统计。包括本地级别和全局级别的统计。 该操作实际上产生了两个 RDD:MapPartitionsRDD与ShuffledRDD。
-
MapPartitionsRDD
reduceByKey在MapPartitionRDD之后,首先,进行本地级别(local)的归并操作,把统计后的结果按照分区策略放到不同的分布式文件中。
例如将(Hello, 1),(Spark, 1),(Hello, 1)汇聚为(Hello, 2),(Spark, 1)进行局部统计,然后将统计的结果传给下一个阶段,如果下一个阶段是3个并行度,每个Partition进行local reduce后,将自己的数据分成了3种类型传给下一个阶段。分成3种类型最简单的方式是通过HashCode按3进行取模。
这个步骤发生在Stage1的末尾端,能够基于内存进行计算,减少网络的传输,并加快计算速度。 -
ShuffledRDD
reduceByKey进行Shuffle操作会产生ShuffleRDD,因为在全局进行聚合的操作时,网络传输不能在内存中进行迭代,因此需要一个新的Stage来重新分类。把结果收集后,会进行全局reduce级别的归并操作。
对照上述流程图,4个机器对4行数据进行并行计算,并在各自内存中进行了局部聚集,将数据进行分类。图中,第1台机器获取数据为(Hello, 2),第2台机器获取数据为(Hello, 1),第3台机器获取数据为(Hello, 1),把所有的Hello进行全局reduce在内部变成(Hello, 4),产生reduceByKey的最后结果,其他数据也类似操作。
综上所述,reduceByKey包含两个阶段:第一个是本地级别的reduce,一个是全局级别的reduce,其中第一个本地级别是我们容易忽视的。
5.输出
reduceByKey操作之后,我们得到了数据的最后结果,需要对结果进行输出。在该阶段会产生MapPartitionsRDD,这里的输出有两种情况:Collect或saveAsTextFile。
- 对于
Collect来说,MapPartitionsRDD的作用是把结果收集起来发送给Driver。 - 对于
saveAsTextFile,将Stage2产生的结果输出到HDFS中时,数据的输出要符合一定的格式,而现在的结果只有value,没有key。所以MapPartitionsRDD会生成相应的key。例如输出(Hello, 4),这里(Hello, 4)是value,而不是"Hello"是key,4是value的形式。
由于最初在textFile读入数据时,split分片操作将key去掉了,只对value计算。所以,最后需要将去掉的key恢复。这里的key只对Spark框架有意义(满足格式),在向HDFS写入结果时,生成的key为null即可。
8.5 本章小结
在本章的学习中,主要介绍Spark的编程模型:RDD的定义、特性和操作函数,接着从Spark的架构原理出发,简述了Spark的计算阶段、作业管理和执行过程。最后通过实验,介绍了Spark的安装、并通过WordCount实例观察RDD的数据流向。如果想要更多的了解Spark SQL和Scala API的内容,可以参考本仓库experiments目录下的笔记Spark SQL的基本使用以及Spark的Scala API介绍(✅Gitee地址:Spark SQL的基本使用以及Spark的Scala API介绍)。