1.5_初识图像分类:MNIST分类实战
文档摘要
初识图像分类:MNIST分类实战 前面几个小节我们学习了Pytorch的环境安装、Pytorch基本用法、反向传播自动求梯度以及线性回归实战,在第二章我们将会学习图像分类的一些基本知识和实战。那么接下来,我们就以一个机器学习领域的Hello World任务——MNIST手写体数字识别来结束本章,同时作为下一章节的预备知识,让大家初识图像分类。 MNIST手写体数字识别是一个分类任务,为了简单直观,本小节将仅使用多层全连接神经网络来实现MNIST分类,关于卷积神经网路以及经典分类网络将会在下一章节进行详细介绍。
初识图像分类:MNIST分类实战
前面几个小节我们学习了Pytorch的环境安装、Pytorch基本用法、反向传播自动求梯度以及线性回归实战,在第二章我们将会学习图像分类的一些基本知识和实战。那么接下来,我们就以一个机器学习领域的Hello World任务——MNIST手写体数字识别来结束本章,同时作为下一章节的预备知识,让大家初识图像分类。
MNIST手写体数字识别是一个分类任务,为了简单直观,本小节将仅使用多层全连接神经网络来实现MNIST分类,关于卷积神经网路以及经典分类网络将会在下一章节进行详细介绍。
MNIST数据集简介
关于MNIST数据集,大部分同学一定不会陌生,它是一个手写数字数据集,包含了0 ~ 9这10个数字,一共有7万张灰度图像,其中6w张训练接,1w张测试集,并且每张都有标签,如标签0对应图像中数字0,标签1对应图像中数字1,以此类推...。
另外,在 MNIST 数据集中的每张图片由 28 x 28 个像素点构成, 每个像素点用一个灰度值表示,灰度值在0 ~ 1 或 0 ~ 255之间,MINIST数据集图像示例如下:

在Pytorch中已经集成了MNIST数据集,所以使用非常方便,几行代码即可解决。关于MNIST数据集更详细的介绍和加载方法,第二章将会介绍。
全连接神经网络和激活函数
全连接层(full-connected layer),简称FC,是神经网络中的一种基本的结构。那么仅由输入层、全连接层、输出层构成的神经网络就叫做全连接神经网络,中间的隐藏层由多层含有不同神经元的全连接层构成,结构可以看下图。
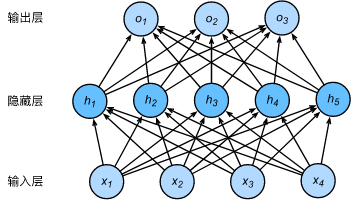
“全连接”层,顾名思义,表示神经网络中除输入层之外的每个节点都和上一层的所有节点有连接,如下图所示:
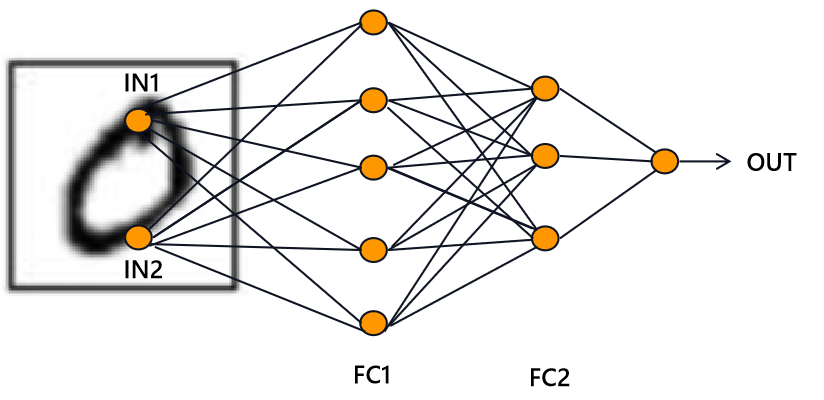
图片中IN1和IN2表示两个像素点,FC1为第一层全连接层,FC2为第二层全连接层,可以看到全连接层所有的节点都和上一层每一个节点相连接,最后连接输出层。当然上图只是一个简单的示例图,节点个数和层数都是随意设置的。
另外,全连接神经网络也叫做多层感知机(MLP),因为它的每一个神经元把前一层所有神经元的输出作为输入,其输出又会给下一层的每一个神经元作为输入,相邻层的每个神经元都有“连接权”。神经网络学到的东西,就蕴含在连接权和偏置中。
事实上,多层全连接的连接处理方式很好,使得全连接神经网路具备一定非线性映射学习能力,能胜任一些简单、低维度的学习任务;但是,全连接神经网路是不适合做图像识别/分类任务的,为啥呢?先卖个关子,第二章会为你解答。
对于MNIST数据集,它的维度是28 x 28 x 1=784, 相对较小,对MLP来说在可接受的范围,而且MNIST数据集较为简单,所以我们用全连接神经网络也是可以实现较好的分类的。
为了使模型能够学习非线性模式(或者说具有更高的复杂度),激活函数被引入其中。常用的激活函数有Sigmoid、tanh、Relu,如下图所示:

好,基本知识就介绍完毕,接下来,就开始实践吧!
全连接神经网络实现MNIST分类
导入相关库
首先导入numpy、torch等模块。
import torch import torch.nn as nn import numpy as np from torch import optim from torch.autograd import Variable from torch.utils.data import DataLoader from torchvision.datasets import mnist from torchvision import transforms import matplotlib.pyplot as plt
全连接网络构建
在这里,我们构建了输入层、四层全连接层和输出层,输入层的节点个数为784,FC1的节点个数为512,FC2的节点个数为256,FC3的节点个数为128,输出层的节点个数是10(分类10个数)。每个全连接层后都接一个
激活函数,这里激活函数选用Relu。
#定义网络结构 class Net(nn.Module): def __init__(self, in_c=784, out_c=10): super(Net, self).__init__() # 定义全连接层 self.fc1 = nn.Linear(in_c, 512) # 定义激活层 self.act1 = nn.ReLU(inplace=True) self.fc2 = nn.Linear(512, 256) self.act2 = nn.ReLU(inplace=True) self.fc3 = nn.Linear(256, 128) self.act3 = nn.ReLU(inplace=True) self.fc4 = nn.Linear(128, out_c) def forward(self, x): x = self.act1(self.fc1(x)) x = self.act2(self.fc2(x)) x = self.act3(self.fc3(x)) x = self.fc4(x) return x # 构建网络 net = Net()
数据加载及网络输入
然后,是数据准备和加载,准备好喂给神经网络的数据。为了简单直观,我们就以MNIST数据集中图像的像素值作为特征进行输入,MNIST图像的维度是28 x 28 x 1=784,所以,直接将28 x 28的像素值展开平铺为 784 x 1的数据输入给输入层。
pytorch内置集成了MNIST数据集,只需要几行代码就可加载,关于加载的具体方法下一章节会详细解释。
# 准备数据集 # 训练集 train_set = mnist.MNIST('./data', train=True, transform=transforms.ToTensor(), download=True) # 测试集 test_set = mnist.MNIST('./data', train=False, transform=transforms.ToTensor(), download=True) # 训练集载入器 train_data = DataLoader(train_set, batch_size=64, shuffle=True) # 测试集载入器 test_data = DataLoader(test_set, batch_size=128, shuffle=False) # 可视化数据 import random for i in range(4): ax = plt.subplot(2, 2, i+1) idx = random.randint(0, len(train_set)) digit_0 = train_set[idx][0].numpy() digit_0_image = digit_0.reshape(28, 28) ax.imshow(digit_0_image, interpolation="nearest") ax.set_title('label: {}'.format(train_set[idx][1]), fontsize=10, color='black') plt.show()

定义损失函数和优化器
模型训练是一个监督学习过程,模型学习到的特征和真实特征难免会存在误差,那么为了纠正模型(通过误差反向传播修正权值),就需要一个函数去描述这种误差,这个函数就是损失函数(loss),训练过程就是使损失函数的值越来越小的过程,loss越小,模型就越精确。
均方误差,大家一定很熟悉,它就是一个不错的loss,不过它的缺点就是优化速度过慢,所以我们使用 交叉熵 作为损失函数,它可以更快收敛。
现在有了模型结构,有了loss,那还需要一个优化算法据误差反传去帮助我们根执行权值修正,这里我们采用随机梯度下降(SGD),当然也还有其他的,例如Adam等等。
# 定义损失函数--交叉熵 criterion = nn.CrossEntropyLoss() # 定义优化器---随机梯度下降 optimizer = optim.SGD(net.parameters(), lr=1e-2, weight_decay=5e-4)
开始训练:前向传播和反向传播
好!万事具备,只欠东风,现在就可开始训练了~,设置了20轮训练次数,大家可以修改看看结果有没有什么变化,在这里还需要定义前向传播和反向传播过程哦。
# 开始训练 # 记录训练损失 losses = [] # 记录训练精度 acces = [] # 记录测试损失 eval_losses = [] # 记录测试精度 eval_acces = [] # 设置迭代次数 nums_epoch = 20 for epoch in range(nums_epoch): train_loss = 0 train_acc = 0 net = net.train() for batch, (img, label) in enumerate(train_data): img = img.reshape(img.size(0), -1) img = Variable(img) label = Variable(label) # 前向传播 out = net(img) loss = criterion(out, label) # 反向传播 optimizer.zero_grad() loss.backward() optimizer.step() # 记录误差 train_loss += loss.item() # 计算分类的准确率 _, pred = out.max(1) num_correct = (pred == label).sum().item() acc = num_correct / img.shape[0] if (batch + 1) % 200 ==0: print('[INFO] Epoch-{}-Batch-{}: Train: Loss-{:.4f}, Accuracy-{:.4f}'.format(epoch + 1, batch+1, loss.item(), acc)) train_acc += acc losses.append(train_loss / len(train_data)) acces.append(train_acc / len(train_data)) eval_loss = 0 eval_acc = 0 # 测试集不训练 for img, label in test_data: img = img.reshape(img.size(0),-1) img = Variable(img) label = Variable(label) out = net(img) loss = criterion(out, label) # 记录误差 eval_loss += loss.item() _, pred = out.max(1) num_correct = (pred == label).sum().item() acc = num_correct / img.shape[0] eval_acc += acc eval_losses.append(eval_loss / len(test_data)) eval_acces.append(eval_acc / len(test_data)) print('[INFO] Epoch-{}: Train: Loss-{:.4f}, Accuracy-{:.4f} | Test: Loss-{:.4f}, Accuracy-{:.4f}'.format( epoch + 1, train_loss / len(train_data), train_acc / len(train_data), eval_loss / len(test_data), eval_acc / len(test_data)))
结果可视化
将结果可视化,从图可以看出,测试结果在0.97以上,还是比较低的哈,大家可以修改一下参数看能否有提高呢。
lt.figure() plt.suptitle('Test', fontsize=12) ax1 = plt.subplot(1, 2, 1) ax1.plot(eval_losses, color='r') ax1.plot(losses, color='b') ax1.set_title('Loss', fontsize=10, color='black') ax2 = plt.subplot(1, 2, 2) ax2.plot(eval_acces, color='r') ax2.plot(acces, color='b') ax2.set_title('Acc', fontsize=10, color='black') plt.show()

总结
到这里,本章的内容就结束啦,完整代码可见code文件夹,这一小节我们主要学习了使用torch如何搭建一个简单的全链接神经网络进行MNIST分类。还有很多细节:如激活函数、损失函数、优化算法以及网络结构它们的选择、公式理论、优缺点等还需要大家深入探究哦。经过本小节的学习,相信对图像分类的基本流程有了一个直观认识,后续章节将会进一步深入探究如何使用深度卷积网络进行图像分类啦。
贡献者
作者: 小武
校对优化:安晟