4.统计和概率简介
文档摘要
统计和概率简介 素描笔记由 (@sketchthedocs) 提供 :---: 统计与概率论 - 素描笔记由 @nitya 提供 统计学和概率论是数学中两个高度相关的领域,对数据科学至关重要。虽然可以不深入了解数学就操作数据,但了解一些基本概念总是更好的。这里我们将简要介绍一些基础知识,帮助你入门。 入门视频 课前测验 概率和随机变量 概率是一个介于0到1之间的数字,表示事件发生的可能性。它定义为导致该事件的正面结果数量除以所有可能的结果总数,前提是所有结果都是等概率的。例如,当我们掷骰子时,得到偶数的概率是3/6 = 0.5。 当我们谈论事件时,我们使用随机变量。例如,表示掷骰子所得数字的随机变量可以取值从1到6。从1到6的数值集合称为样本空间。
统计和概率简介
 |
|---|
| 统计与概率论 - _素描笔记由 @nitya 提供 _ |
统计学和概率论是数学中两个高度相关的领域,对数据科学至关重要。虽然可以不深入了解数学就操作数据,但了解一些基本概念总是更好的。这里我们将简要介绍一些基础知识,帮助你入门。
课前测验
概率和随机变量
概率是一个介于0到1之间的数字,表示事件发生的可能性。它定义为导致该事件的正面结果数量除以所有可能的结果总数,前提是所有结果都是等概率的。例如,当我们掷骰子时,得到偶数的概率是3/6 = 0.5。
当我们谈论事件时,我们使用随机变量。例如,表示掷骰子所得数字的随机变量可以取值从1到6。从1到6的数值集合称为样本空间。我们可以谈论随机变量取某个特定值的概率,例如P(X=3)=1/6。
在上面的例子中,随机变量被称为离散型,因为它具有可枚举的样本空间,即有独立的值。有些情况下,样本空间是一个实数范围,甚至是整个实数集。这种变量称为连续型。一个很好的例子是公交车到达的时间。
概率分布
对于离散型随机变量,通过函数P(X)描述每个事件的概率是很容易的。对于样本空间S中的每个值s,它将给出0到1之间的一个数字,所有事件的P(X=s)之和为1。
最著名的离散型分布是均匀分布,在这种分布中,样本空间有N个元素,每个元素的概率均为1/N。
描述连续型变量的概率分布更加困难,因为其值是从某个区间[a,b]或整个实数集ℝ中抽取的。考虑公交车到达时间的情况。实际上,对于每个确切的到达时间t,公交车恰好在那个时间到达的概率为0!
现在你知道概率为0的事件也会发生,并且经常发生!至少每次公交车到达时都是如此!
我们只能谈论随机变量落在给定区间内的概率,例如P(t1≤X<t2)。在这种情况下,概率分布由概率密度函数p(x)描述,满足以下条件:
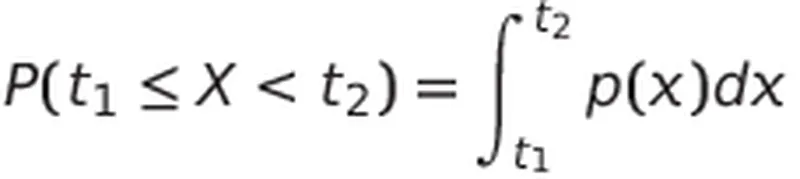
均匀分布的连续型版本称为连续型均匀分布,它定义在一个有限区间上。值X落入长度为l的区间的概率与l成正比,并上升到1。
另一个重要的分布是正态分布,我们将在下面更详细地讨论。
均值、方差和标准差
假设我们从随机变量X中抽取了一个序列n个样本:x1, x2, ..., xn。我们可以像传统方式一样定义序列的均值(或算术平均值)为(x1+x2+...+xn)/n。随着样本大小的增长(即取n→∞的极限),我们将获得分布的均值(也称为期望)。我们用E(x)表示期望。
可以证明,对于任何离散分布,其值为{x1, x2, ..., xN},相应的概率为p1, p2, ..., pN,期望等于E(X)=x1p1+x2p2+...+xNpN。
为了识别数值分散的程度,我们可以计算方差 σ2 = ∑(xi - μ)2/n,其中μ是序列的均值。值σ称为标准差,σ2称为方差。
众数、中位数和四分位数
有时,均值不能很好地代表数据的“典型”值。例如,当存在一些极端值时,它们会影响均值。另一种好的指标是中位数,即一半的数据点低于该值,另一半高于该值。
为了帮助我们理解数据的分布,谈论四分位数是有帮助的:
- 第一四分位数(Q1)是指25%的数据点低于该值。
- 第三四分位数(Q3)是指75%的数据点低于该值。
我们可以通过箱线图来图形化表示中位数和四分位数的关系:
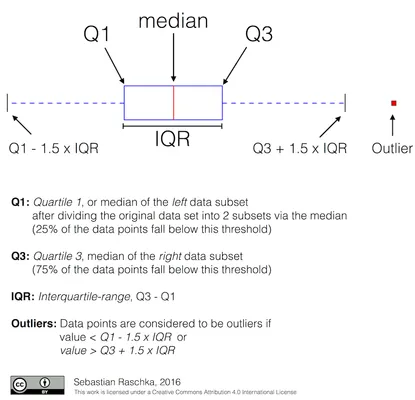
在这里我们还计算了四分位间距 IQR=Q3-Q1,以及所谓的异常值 - 即超出边界 [Q1-1.5IQR, Q3+1.5IQR] 的值。
对于包含少量可能值的有限分布,一个良好的“典型”值是出现频率最高的值,这称为众数。它通常应用于分类数据,如颜色。假设我们有两个群体的人,一些人强烈偏爱红色,另一些人则偏爱蓝色。如果我们用数字编码颜色,最喜欢的颜色的均值会在橙色和绿色之间,但这并不能准确反映任何一个群体的实际偏好。然而,众数将是其中一种颜色,或者如果投票人数相等,则两种颜色都是(在这种情况下,我们称样本为多模态)。
实际数据
当我们分析现实生活中的数据时,这些数据往往不是随机变量,因为我们不会对未知结果进行实验。例如,考虑一支棒球队及其队员的身体数据,如身高、体重和年龄。这些数字并不是完全随机的,但我们仍然可以应用相同的数学概念。例如,一个人的体重序列可以被视为从某个随机变量中抽取的一系列值。以下是来自美国职业棒球大联盟的真实棒球运动员体重序列(仅显示前20个值):
[180.0, 215.0, 210.0, 210.0, 188.0, 176.0, 209.0, 200.0, 231.0, 180.0, 188.0, 180.0, 185.0, 160.0, 180.0, 185.0, 197.0, 189.0, 185.0, 219.0]
注意:要查看此数据集的示例,请参考附带笔记本。本课程中有多个挑战,你可以通过向该笔记本添加一些代码来完成它们。如果你不知道如何处理数据,不要担心——我们将在稍后的时间使用Python进一步讲解。如果你不知道如何运行Jupyter笔记本中的代码,请阅读这篇文章。
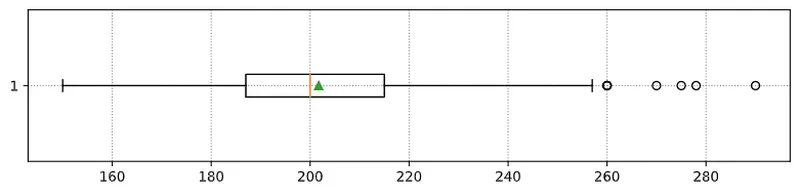
以下是显示我们的数据的均值、中位数和四分位数的箱线图:
由于我们的数据包含了不同的球员角色,我们还可以按角色绘制箱线图——这将使我们了解不同角色参数值的差异。这次我们考虑身高:

该图表表明,平均而言,一垒手的身高高于二垒手。在本课程的后续部分,我们将学习如何更正式地测试这一假设,并如何展示我们的数据在统计上显著地表明这一点。
在处理现实世界的数据时,我们假定所有数据点都是从某个概率分布中抽取的样本。这一假设使我们能够应用机器学习技术并构建有效的预测模型。
要查看我们的数据的分布,我们可以绘制一个称为直方图的图。X轴包含不同体重间隔(所谓桶),垂直轴显示随机变量样本落入给定间隔的次数。
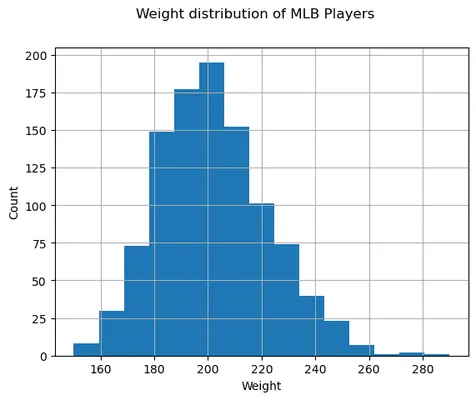
从这个直方图可以看出,所有值都集中在某个均值周围,越远离这个均值,遇到的该重量的次数就越少。也就是说,棒球运动员的体重非常不可能与平均体重有很大差异。体重的方差显示了体重偏离均值的可能性。
如果我们测量的是其他人的体重,而不是来自棒球联赛的人,那么分布很可能会不同。然而,分布的形状会相同,但均值和方差会改变。因此,如果我们用棒球运动员训练模型,将其应用于大学学生时很可能会得出错误的结果,因为基础分布不同。
正态分布
我们上面看到的体重分布非常典型,许多现实生活中的测量值都遵循相同类型的分布,但具有不同的均值和方差。这种分布称为正态分布,在统计学中起着非常重要的作用。
使用正态分布是生成潜在棒球运动员体重的有效方法。一旦我们知道均值重量mean and standard deviation std,我们可以通过以下方式生成1000个体重样本:
samples = np.random.normal(mean,std,1000)
如果绘制生成样本的直方图,我们会看到与上述图非常相似的图像。如果我们增加样本数量和桶的数量,我们可以生成更接近理想的正态分布的图像:
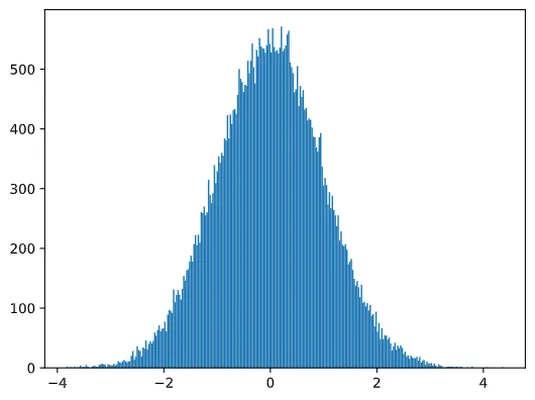
*均值=0,标准差=1的正态分布*
置信区间
当我们谈论棒球运动员的体重时,我们假设有一个对应理想概率分布的随机变量W,该分布代表所有棒球运动员的体重(所谓的总体)。我们的体重序列对应于我们称为样本的所有棒球运动员的一个子集。一个有趣的问题是,我们能否知道分布的参数,即总体的均值和方差?
最简单的答案是计算样本的均值和方差。然而,我们的随机样本可能不能准确地代表完整总体。因此,讨论置信区间是有意义的。
置信区间是在一定概率(或置信水平)下对总体真实均值的估计。
假设我们从分布中抽取了样本X1, ..., Xn。每次从分布中抽取样本,我们都会得到不同的均值μ。因此,μ可以被视为一个随机变量。置信区间是一个值对(Lp,Rp),使得P(Lp≤μ≤Rp) = p,即测量均值落在该区间内的概率等于p。
详细讨论如何计算这些置信区间超出了我们的简短介绍。更多信息可以在维基百科上找到。简单地说,我们定义了计算出的样本均值相对于总体真实均值的分布,这称为学生分布。
有趣的事实:学生分布是以数学家William Sealy Gosset命名的,他以化名“学生”发表了论文。他在吉尼斯酿酒厂工作,根据一种说法,他的雇主不想让公众知道他们正在使用统计检验来确定原材料的质量。
如果我们想以置信度p估计总体的均值μ,我们需要取*(1-p)/2-th 百分位的学生分布A,这可以从表格中获取,也可以使用一些统计软件(如Python、R等)中的内置函数计算。然后,μ的区间由X±AD/√n给出,其中X是样本的均值,D是标准差。
注意:我们还省略了关于自由度的重要概念的讨论,该概念与学生分布有关。你可以查阅更完整的统计书籍以更深入地理解这一概念。
在附带笔记本中给出了权重和身高的置信区间计算示例。
| 置信度 | 体重均值 |
|---|---|
| 0.85 | 201.73±0.94 |
| 0.90 | 201.73±1.08 |
| 0.95 | 201.73±1.28 |
请注意,置信度越高,置信区间越宽。
假设检验
在我们的棒球运动员数据集中,有不同的球员角色,可以总结如下(查看附带笔记本了解如何计算此表):
| 角色 | 身高 | 体重 | 计数 |
|---|---|---|---|
| 捕手 | 72.723684 | 204.328947 | 76 |
| 指定击球手 | 74.222222 | 220.888889 | 18 |
| 一垒手 | 74.000000 | 213.109091 | 55 |
| 外野手 | 73.010309 | 199.113402 | 194 |
| 救援投手 | 74.374603 | 203.517460 | 315 |
| 二垒手 | 71.362069 | 184.344828 | 58 |
| 游击手 | 71.903846 | 182.923077 | 52 |
| 先发投手 | 74.719457 | 205.163636 | 221 |
| 三垒手 | 73.044444 | 200.955556 | 45 |
我们可以注意到,一垒手的平均身高高于二垒手。因此,我们可能会得出结论:一垒手比二垒手更高。
这个陈述被称为假设,因为我们不知道这个事实是否真的成立。
然而,是否可以得出这样的结论并不总是显而易见的。从上面的讨论我们知道,每个均值都有一个相关的置信区间,因此这个差异可能只是统计误差。我们需要一些更正式的方法来检验我们的假设。
让我们分别计算一垒手和二垒手身高的置信区间:
| 置信度 | 一垒手 | 二垒手 |
|---|---|---|
| 0.85 | 73.62..74.38 | 71.04..71.69 |
| 0.90 | 73.56..74.44 | 70.99..71.73 |
| 0.95 | 73.47..74.53 | 70.92..71.81 |
我们可以看到,在任何置信度下,区间都不重叠。这证明了一垒手确实比二垒手更高。
更正式地,我们解决的问题是看两个概率分布是否相同,或者至少具有相同的参数。根据分布的不同,我们需要使用不同的检验方法。如果我们知道我们的分布是正态的,我们可以应用**[学生t检验]**。
在学生t检验中,我们计算所谓的t值,它表示考虑到方差的均值之间的差异。研究表明t值遵循学生分布,这使我们能够为给定的置信水平p(可以从表中查找或通过某些统计软件计算)获得阈值。然后我们将t值与该阈值进行比较,以批准或拒绝假设。
在Python中,我们可以使用SciPy包,它包括ttest_ind函数(除了许多其他有用的统计函数!)。它为我们计算t值,并执行反向查找以获得置信p值,因此我们可以直接查看置信度以得出结论。
例如,我们对一垒手和二垒手身高的比较给出了以下结果:
from scipy.stats import ttest_ind tval, pval = ttest_ind(df.loc[df['Role']=='First_Baseman',['Height']], df.loc[df['Role']=='Designated_Hitter',['Height']],equal_var=False) print(f"T-value = {tval[0]:.2f}\nP-value: {pval[0]}")
T-value = 7.65 P-value: 9.137321189738925e-12
在这个案例中,p值非常低,意味着有一股强有力的证据支持一垒手比二垒手更高的结论。
我们还有其他类型的假设需要测试,例如:
- 证明给定样本符合某种分布。在我们的案例中,我们假设身高呈正态分布,但这需要正式的统计验证。
- 证明样本的均值对应某个预定义值。
- 比较多个样本的均值(例如,不同年龄段人群的幸福感水平差异)。
大数定律和中心极限定理
正态分布之所以重要,其中一个原因是所谓的中心极限定理。假设我们有一个大型的独立样本N个值X1, ..., XN,从任意分布中抽取,具有均值μ和方差σ2。那么,对于足够大的N,这些值的样本均值将接近正态分布,均值为μ,方差为σ2/N。
N(换句话说,当N→∞时),均值ΣiXi将服从正态分布,其均值为μ,方差为σ2/N。
中心极限定理的另一种解释是,无论分布如何,当你计算一组随机变量值的平均值时,最终会得到一个正态分布。
根据中心极限定理,当N→∞时,样本均值等于μ的概率变为1。这被称为大数定律。
协方差和相关性
数据科学的一个重要方面是发现数据之间的关系。当我们观察到两个序列在同一时间表现出相似的行为时,即它们要么同时上升或下降,或者一个序列上升而另一个下降,我们说这两个序列相关。换句话说,似乎有两个序列之间存在某种关系。
相关并不一定表明两个序列之间存在因果关系;有时两个变量都可能依赖于某些外部因素,或者两个序列相关纯粹是偶然的。然而,强烈的数学相关性是一个很好的迹象,表明两个变量在某种程度上是相关的。
从数学上讲,表示两个随机变量之间关系的主要概念是协方差,其计算公式如下:Cov(X,Y) = E[(X-E(X))(Y-E(Y))]。我们计算两个变量偏离其均值的程度,然后将这些偏差相乘。如果两个变量一起偏离,乘积将始终是正值,从而增加正协方差。如果两个变量不同步偏离(即一个变量低于平均值而另一个变量高于平均值),我们将始终得到负数,从而增加负协方差。如果偏差无关,则它们大致相加为零。
协方差的绝对值并不能告诉我们相关性的大小,因为它取决于实际值的幅度。为了标准化它,我们可以将协方差除以两个变量的标准差,从而得到相关性。好的一点是,相关性总是在[-1,1]范围内,其中1表示值之间强烈的正相关,-1表示强烈的负相关,0表示没有相关性(变量相互独立)。
示例:我们可以计算上述数据集中棒球运动员体重和身高的相关性:
print(np.corrcoef(weights,heights))
结果,我们得到一个相关矩阵,如下所示:
array([[1. , 0.52959196], [0.52959196, 1. ]])
对于任何数量的输入序列S1,...,Sn,可以计算相关矩阵C。Cij的值是Si和Sj之间的相关性,并且对角线元素始终为1(这也是Si的自相关)。
在我们的例子中,数值0.53表示体重和身高之间存在某种相关性。我们还可以制作一个散点图来直观地看到这种关系:
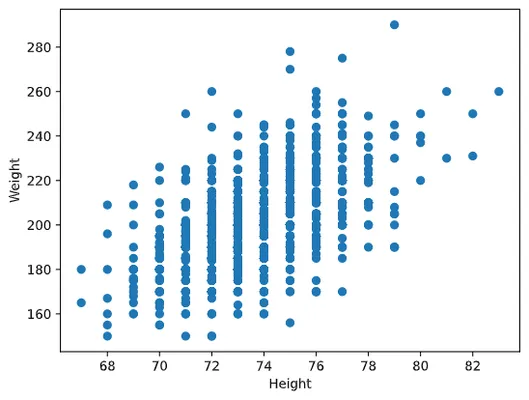
更多关于协方差和相关性的示例可以在附带的笔记本中找到。
结论
在本节中,我们学习了:
- 数据的基本统计属性,如均值、方差、众数和四分位数
- 随机变量的不同分布,包括正态分布
- 如何找到不同属性之间的相关性
- 如何使用数学和统计学的方法来证明某些假设
- 如何根据数据样本计算随机变量的置信区间
虽然概率和统计学的主题非常广泛,但这应该足以让你在这个课程中有一个良好的开端。
挑战
使用笔记本中的示例代码来测试以下假设:
- 一垒手比二垒手年长
- 一垒手比三垒手高
- 游击手比二垒手高
课后测验
复习与自学
概率和统计学是一个如此广泛的主题,值得单独开设一门课程。如果你有兴趣深入理论,可以继续阅读以下书籍之一:
- 纽约大学的Carlos Fernandez-Granda教授提供了精彩的讲义《数据科学的概率和统计》(在线可获取)
- Peter和Andrew Bruce的《数据科学家实用统计学》。[R语言示例代码]
- James D. Miller的《数据科学统计学》。[R语言示例代码]
作业
致谢
本课程由Dmitry Soshnikov精心设计
声明:
本文件灏天文库团队进行了翻译。尽管我们力求准确,但请注意,翻译可能包含错误或不准确之处。原文档以其原始语言为准。我们不对因使用此翻译而产生的任何误解或误译负责。