5.处理数据:关系型数据库
文档摘要
处理数据:关系型数据库 速写插图由@sketchthedocs绘制 :---: 处理数据:关系型数据库 - 速写插图由@nitya绘制 你可能在过去使用过电子表格来存储信息。你有一组行和列,其中行包含信息(或数据),而列描述了这些信息(有时称为元数据)。关系型数据库建立在这些核心原理之上,即表中的行和列,允许你在多个表中存储信息。这使你可以处理更复杂的数据,避免重复,并且在探索数据的方式上具有灵活性。让我们来探讨一下关系型数据库的概念。 课前测验 一切从表开始 关系型数据库的核心是表。就像电子表格一样,一个表是一系列列和行的集合。行包含了我们想要操作的信息,例如城市的名称或降雨量。列描述了它们所存储的数据。 让我们通过创建一个存储城市信息的表来开始我们的探索。我们可能会从城市名称和国家开始。
处理数据:关系型数据库
 |
|---|
| 处理数据:关系型数据库 - 速写插图由@nitya绘制 |
你可能在过去使用过电子表格来存储信息。你有一组行和列,其中行包含信息(或数据),而列描述了这些信息(有时称为元数据)。关系型数据库建立在这些核心原理之上,即表中的行和列,允许你在多个表中存储信息。这使你可以处理更复杂的数据,避免重复,并且在探索数据的方式上具有灵活性。让我们来探讨一下关系型数据库的概念。
课前测验
一切从表开始
关系型数据库的核心是表。就像电子表格一样,一个表是一系列列和行的集合。行包含了我们想要操作的信息,例如城市的名称或降雨量。列描述了它们所存储的数据。
让我们通过创建一个存储城市信息的表来开始我们的探索。我们可能会从城市名称和国家开始。你可以将这些信息存储在一个表中,如下所示:
| 城市 | 国家 |
|---|---|
| 东京 | 日本 |
| 亚特兰大 | 美国 |
| 奥克兰 | 新西兰 |
注意,列名 城市、国家 和 人口 描述了存储的数据,每一行都包含一个城市的信息。
单表方法的局限性
你可能觉得上面的表对你来说很熟悉。现在让我们向我们正在发展的数据库添加一些额外的数据——年降雨量(以毫米为单位)。我们将重点关注2018年、2019年和2020年。如果我们为东京添加数据,它可能看起来像这样:
| 城市 | 国家 | 年份 | 数量 |
|---|---|---|---|
| 东京 | 日本 | 2020 | 1690 |
| 东京 | 日本 | 2019 | 1874 |
| 东京 | 日本 | 2018 | 1445 |
你注意到我们的表有什么问题吗?你可能会注意到我们在每一行中重复了城市的名称和国家。这会占用大量的存储空间,并且基本上没有必要有多个副本。毕竟,东京只有一个我们感兴趣的名称。
好的,让我们尝试其他方法。让我们为每一年添加新列:
| 城市 | 国家 | 2018 | 2019 | 2020 |
|---|---|---|---|---|
| 东京 | 日本 | 1445 | 1874 | 1690 |
| 亚特兰大 | 美国 | 1779 | 1111 | 1683 |
| 奥克兰 | 新西兰 | 1386 | 942 | 1176 |
虽然这避免了行重复,但也带来了其他挑战。每次有新的年份时,我们需要修改表的结构。此外,随着数据的增长,将年份作为列会使检索和计算值变得更加困难。
这就是为什么我们需要多个表和关系。通过拆分数据,我们可以避免重复并有更多的灵活性来处理数据。
关系的概念
让我们回到数据上,确定如何分割数据。我们知道我们想存储城市名称和国家,所以这可能最适合放在一个表中。
| 城市 | 国家 |
|---|---|
| 东京 | 日本 |
| 亚特兰大 | 美国 |
| 奥克兰 | 新西兰 |
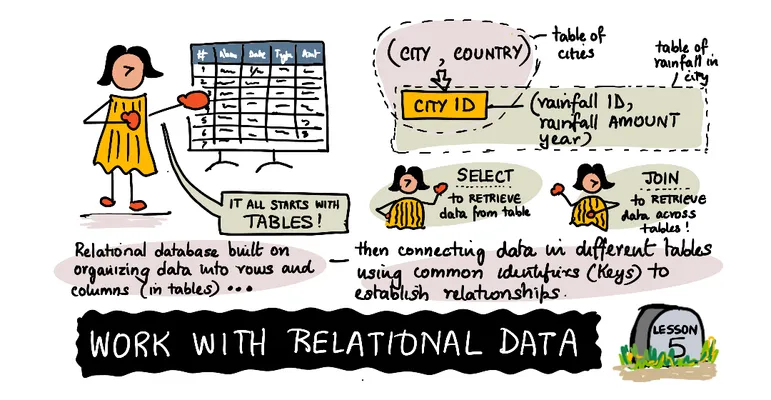
但在创建下一个表之前,我们需要弄清楚如何引用每个城市。我们需要某种形式的标识符,ID 或(在技术数据库术语中)主键。主键是一个用于标识表中特定行的值。虽然这可以基于值本身(例如,我们可以使用城市的名称),但它几乎总是数字或其他标识符。我们不希望 ID 发生变化,因为这会破坏关系。你会发现大多数情况下主键或 ID 都是自动生成的数字。
✅ 主键通常缩写为 PK
城市
| 城市编号 | 城市 | 国家 |
|---|---|---|
| 1 | 东京 | 日本 |
| 2 | 亚特兰大 | 美国 |
| 3 | 奥克兰 | 新西兰 |
✅ 在本课程中,你可能会注意到我们交替使用“ID”和“主键”这两个术语。这些概念适用于你稍后将要探索的数据框架。数据框架不使用“主键”的术语,但你会注意到它们的行为方式非常相似。
有了城市表之后,让我们存储降雨量。与其复制完整的城市信息,我们可以使用 ID。我们也应该确保新创建的表也有一个 id 列,因为所有表都应该有一个 ID 或主键。
降雨量
| 降雨量编号 | 城市编号 | 年份 | 数量 |
|---|---|---|---|
| 1 | 1 | 2018 | 1445 |
| 2 | 1 | 2019 | 1874 |
| 3 | 1 | 2020 | 1690 |
| 4 | 2 | 2018 | 1779 |
| 5 | 2 | 2019 | 1111 |
| 6 | 2 | 2020 | 1683 |
| 7 | 3 | 2018 | 1386 |
| 8 | 3 | 2019 | 942 |
| 9 | 3 | 2020 | 1176 |
注意 城市编号 列在新创建的 降雨量 表中的位置。这个列包含引用 城市 表中 ID 的值。在技术关系数据术语中,这被称为 外键;它是另一个表的主键。你只需将其视为引用或指针。城市编号 1 引用了东京。
[!NOTE] 外键通常缩写为 FK
检索数据
当我们把数据分成两个表后,你可能会想知道如何检索数据。如果我们使用 MySQL、SQL Server 或 Oracle 等关系型数据库,我们可以使用一种名为结构化查询语言或 SQL 的语言。SQL(有时读作 sequel)是一种标准语言,用于检索和修改关系型数据库中的数据。
要检索数据,你使用命令 SELECT。其核心是你 选择 要查看的列 来自 包含这些列的表。如果你只想显示城市的名字,你可以使用以下代码:
SELECT city FROM cities; -- Output: -- Tokyo -- Atlanta -- Auckland
SELECT 是列出列的地方,FROM is where you list the tables.
[NOTE] SQL syntax is case-insensitive, meaning
select和SELECT意思相同。然而,根据你使用的数据库类型,列和表可能是区分大小写的。因此,最好始终将编程中的所有内容视为区分大小写。编写 SQL 查询时,常见的约定是将关键字全部大写。
上述查询将显示所有城市。假设我们只想显示新西兰的城市。我们需要某种形式的过滤器。SQL 中的这个关键字是 WHERE,意为“某个条件为真”。
SELECT city FROM cities WHERE country = 'New Zealand'; -- Output: -- Auckland
合并数据
到目前为止,我们只从一个表中检索数据。现在我们想将来自 城市 和 降雨量 表的数据合并在一起。这是通过 连接 它们来完成的。你将有效地在两个表之间创建一个接口,并匹配来自每个表的列的值。
在我们的示例中,我们将匹配 降雨量 表中的 城市编号 列与 城市 表中的 城市编号 列。这将匹配降雨量值与相应城市。我们将执行的连接类型称为 内连接,意味着如果任何行在另一张表中没有任何匹配项,它们将不会被显示。在我们的例子中,每个城市都有降雨记录,所以一切都将被显示。
让我们检索所有城市的2019年降雨量。
我们将分步进行。第一步是通过指示连接的列——城市编号 来连接数据,如前所述。
SELECT cities.city rainfall.amount FROM cities INNER JOIN rainfall ON cities.city_id = rainfall.city_id
我们已经高亮了我们要连接的两列以及 城市编号。现在我们可以添加 WHERE 语句来筛选出只有2019年的记录。
SELECT cities.city rainfall.amount FROM cities INNER JOIN rainfall ON cities.city_id = rainfall.city_id WHERE rainfall.year = 2019 -- Output -- city | amount -- -------- | ------ -- Tokyo | 1874 -- Atlanta | 1111 -- Auckland | 942
总结
关系型数据库围绕着将信息划分到多个表中,然后将这些信息重新组合起来以供展示和分析。这提供了高度的灵活性来进行计算和其他数据操作。你已经了解了关系型数据库的核心概念,以及如何在两个表之间执行连接操作。
挑战
互联网上有许多关系型数据库可供探索。你可以使用以上学到的技能来探索这些数据。
课后测验
课后测验
复习与自学
Microsoft Learn 上有几个资源可供你继续探索 SQL 和关系型数据库概念
- 描述关系数据的概念
- 使用 Transact-SQL 开始查询(Transact-SQL 是 SQL 的一种版本)
- Microsoft Learn 上的 SQL 内容
作业
声明:
本文件灏天文库团队进行了翻译。尽管我们力求准确,但请注意,翻译可能包含错误或不准确之处。原文档以其原始语言为准。我们不对因使用此翻译而产生的任何误解或误译负责。