RLSystemDeepThinkingWeightUpdateMechanisms
文档摘要
RL System Deep Thinking: Weight Update Mechanisms I recently had the opportunity to once again delve into and reflect upon the system design of mainstream RL frameworks. We hope to share our thoughts through a series of documents and receive feedback, collaborating with like-minded friends to build a better open-source RLHF framework.
RL System Deep Thinking: Weight Update Mechanisms
I recently had the opportunity to once again delve into and reflect upon the system design of mainstream RL frameworks. We hope to share our thoughts through a series of documents and receive feedback, collaborating with like-minded friends to build a better open-source RLHF framework. We're calling this series "RL System Deep Thinking." This is the first article in the series, focusing on various weight update mechanisms. We will start by analyzing the weight update method in verl under a co-located strategy, where I first understood from scratch how weight updates are implemented by reconstructing tensors from handle tuples. Next, we will dissect the weight update model in the slime framework, focusing on its ingenious bucket update strategy. Finally, we will conduct a horizontal comparison of three weight update methods and briefly share some of my personal thoughts. All feedback and corrections are welcome.
As is customary, I'd like to thank all the friends who participated in the discussion and writing of this document:
Zhuoran Yin (CMU), Changyi Yang (CMU), Ji Li (Ant Group), Chengxi Li (CMU), Biao He (LinkedIn), Junrong Lin (Qwen), Shan Yu (UCLA), Xinyuan Tong (Chenyang's little minion), Chenyang Zhao (Amazon)
(The order is based on the member list in our WeChat group )
Weight Update in verl's co-located strategy
Logically, weight updates under a co-located strategy are all similar. We'll use the FSDP training backend as an example to provide a simplified and general update process. The core is this code snippet:
def _preprocess_tensor_for_update_weights(tensor: torch.Tensor): if isinstance(tensor, DTensor): return tensor.full_tensor() return tensor async def update_weights(self, params): named_tensors = [(k, v) for k, v in params.items()] load_format = None for tensor_index, (name, tensor) in enumerate(named_tensors): serialized_tensor = MultiprocessingSerializer.serialize(_preprocess_tensor_for_update_weights(tensor)) if self.device_mesh["infer_tp"].get_local_rank() == 0: gathered_serialized_tensors = [None for _ in range(self.device_mesh["infer_tp"].mesh.size()[0])] else: gathered_serialized_tensors = None dist.gather_object( obj=serialized_tensor, object_gather_list=gathered_serialized_tensors, dst=self.device_mesh["infer_tp"].mesh.tolist()[0], group=self.device_mesh["infer_tp"].get_group(), ) if self.device_mesh["infer_tp"].get_local_rank() == 0: await self.inference_engine.update_weights_from_tensor( named_tensors=[ ( name, LocalSerializedTensor(values=gathered_serialized_tensors), ) ], load_format=load_format, flush_cache=tensor_index == len(named_tensors) - 1, )
Parameters are gathered and updated one by one. After one parameter is updated, it's released, and the loop continues. Let's take a single parameter as an example. Assume its size is [1024, 1024], FSDP's TP size is 4, and SGLang's TP size is 2. Therefore, before the update begins, each rank in the FSDP engine has a tensor of size [256, 1024], while the SGLang engine has a tensor of size [512, 1024].
- Weight Export: Each rank calls
_preprocess_tensor_for_update_weights()to gather the full tensor for the current parameter. This effectively aggregates the parameter shards from various GPUs onto each rank, so every rank holds a complete copy of the current parameter's tensor. At this point, there will be three copies of this parameter: the first two are the[512, 1024]and[256, 1024]tensors that FSDP and SGLang already have, and the third is a[1024, 1024]tensor allocated specifically for the aggregation. - Tensor Serialization:
MultiprocessingSerializer.serialize()is called to serialize the aggregated parameter on each rank, yielding a serialized handle tuple, referred to asserialized_tensor. Note that although the input to serialization is the aggregated[1024, 1024]tensor, the return value is only the serialized handle tuple. A handle tuple is akin to a pointer to the tensor's actual storage, containing information like virtual address, stripe, size, etc., as well as the CUDA IPC handler needed for tensor reconstruction on the SGLang engine side. - Gather Handle Tuples to FSDP TP 0: Although every rank has aggregated the full tensor for the current parameter, only
tp 0collects the handle tuples from all ranks viagather_object. - Inter-Process Transfer: FSDP TP rank 0 packs the collected list of handle tuples into a
LocalSerializedTensorobject for subsequent reconstruction. It then transfers it to the SGLang Engine via inter-process communication. Only the serialized handle tuples are transferred, not the actual data. - SGLang Engine Tensor Reconstruction: Each TP rank in SGLang calls
_unwrap_tensor(), which in turn callsLocalSerializedTensor.get -> MultiprocessingSerializer.deserialize. This deserializes and recovers the handle tuple of the full tensor that was aggregated on the FSDP side. Next, a new Python tensor object is constructed, and the just-recovered handle tuple is assigned as its handle tuple. The new tensor object and the aggregated full tensor on the FSDP side share the same handle tuple and all metadata, thus pointing to the same block of GPU memory, completing the tensor reconstruction process. - SGLang Engine Loads Weights: The reconstructed tensor is passed to
ModelRunner.load_weights, which replaces the original tensor for that parameter with the new one, completing the entire parameter update process.
Through this process, on any given TP rank, only a temporary [1024, 1024] tensor is created. After the original handler is replaced, the unused half of this [1024, 1024] tensor is released. The old tensor pointed to by the original SGLang engine handler is also freed, preventing any memory leaks.
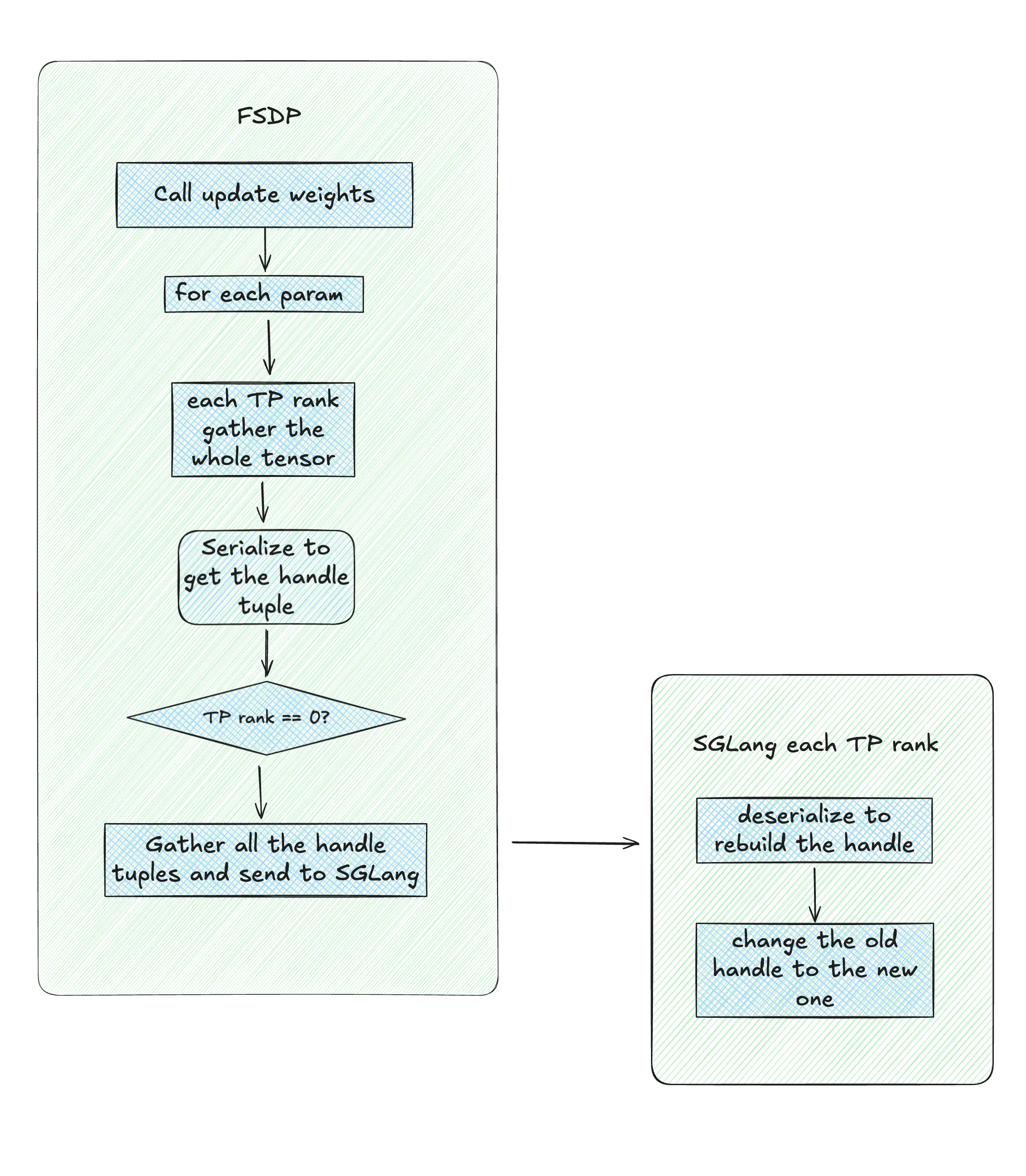
Weight Export
Weight export and handle tuple serialization are done in a single line:
def _preprocess_tensor_for_update_weights(tensor: torch.Tensor): if isinstance(tensor, DTensor): return tensor.full_tensor() return tensor serialized_tensor = MultiprocessingSerializer.serialize(_preprocess_tensor_for_update_weights(tensor))
After the training phase concludes, weights are first exported using FSDP state_dict. Generally, state_dict is a param name -> tensor dictionary. In FSDP, the value in the state_dict depends on the StateDictType mode. FSDP has three built-in modes: FULL_STATE_DICT, SHARDED_STATE_DICT, and LOCAL_STATE_DICT. Let's examine these three modes assuming a 4-rank FSDP training with a parameter shape of [1024, 1024], where each rank is responsible for 1/4 of the parameters:
-
FULL_STATE_DICT# Each rank gets the complete parameters { 'layer1.weight': tensor([1024, 1024]), # Full tensor, identical on each rank 'layer1.bias': tensor([1024]), # Full tensor, identical on each rank # ... all parameters are complete } -
LOCAL_STATE_DICT# Each rank only gets the shard it is responsible for { 'layer1.weight': tensor([256, 1024]), # Shard for the current rank (1/4) 'layer1.bias': tensor([256]), # Shard for the current rank (1/4) # ... only the parameter shards for the current rank } -
SHARDED_STATE_DICT# Each rank gets a shard object containing metadata { 'layer1.weight': ShardedTensor { metadata: { "world_size": 4, # Total number of shards "rank": 1, # Current shard index (0-3) "shape": [1024, 1024], # Shape of the full tensor "dtype": torch.float16, # Data type }, local_shard: tensor([256, 1024]), # Shard data for the current rank }, 'layer1.bias': ShardedTensor { metadata: { "world_size": 4, "rank": 1, "shape": [1024], "dtype": torch.float16 }, local_shard: tensor([256]), # Shard data for the current rank } }
Among these, FULL_STATE_DICT is the most straightforward implementation. LOCAL_STATE_DICT only saves the part stored by the current rank without slicing information, while SHARDED_STATE_DICT builds upon LOCAL_STATE_DICT by additionally storing metadata about the parameter shard and slicing. A tensor in the SHARDED_STATE_DICT state can be aggregated using full_tensor():
if isinstance(tensor, DTensor): return tensor.full_tensor()
Tensor Serialization
Serialization is performed by MultiprocessingSerializer.serialize. As mentioned earlier, the return value from serializing a tensor is actually a serialized handler, or more precisely, a handle tuple. Let's look at the return value of the reduce_tensor() function, which is called deep within the serialization process:
return ( rebuild_cuda_tensor, # Reconstruction function ( type(tensor), # Tensor type tensor.size(), # Tensor size tensor.stride(), # Tensor stride tensor_offset, # Tensor offset in storage type(storage), # Storage type tensor.dtype, # Tensor data type device, # Tensor device handle, # Identifier for which CUDA allocation the storage is in storage_size_bytes, # Storage size storage_offset_bytes, # Storage offset in CUDA allocation tensor.requires_grad, # Whether the tensor requires grad ref_counter_handle, # Reference counter handle ref_counter_offset, # Reference counter offset event_handle, # Event handle event_sync_required, # Whether event sync is required ), )
As you can see, calling reduce_tensor on a CUDA Tensor returns a Python Tuple containing everything needed to reconstruct the Tensor, but absolutely none of the actual stored data itself. This handle tuple is then passed to the receiving party via inter-process communication (e.g., zmq). The receiver, naturally, does not get the data itself but a set of handlers that help find (reconstruct) this tensor. We will refer to this as the handle tuple hereafter.
Gathering Handles
Note that during the process of gathering and serializing the tensor, no distinction is made between different TP ranks. This means that for the parameter being updated, each TP rank will allocate an additional piece of GPU memory, gather the complete tensor, and serialize it to get its handle tuple. Given that a single parameter is not very large, this approach is still safe. Next, after each TP rank obtains a handle tuple, the handle tuples themselves are also gathered:
if self.device_mesh["infer_tp"].get_local_rank() == 0: gathered_serialized_tensors = [None for _ in range(self.device_mesh["infer_tp"].mesh.size()[0])] else: gathered_serialized_tensors = None dist.gather_object( obj=serialized_tensor, object_gather_list=gathered_serialized_tensors, dst=self.device_mesh["infer_tp"].mesh.tolist()[0], group=self.device_mesh["infer_tp"].get_group(), )
Here, dist.gather_object is used to gather the handle tuples from all TP ranks. Unlike all_gather, gather_object is a one-way gathering operation:
- All TP ranks participate in sending: Each rank calls
dist.gather_objectto send itsserialized_tensor. - Only the destination rank receives: Only the rank specified by
dst(here, TP rank 0) will receive the complete list of handle tuples. - Other ranks do not receive: For non-destination ranks,
gathered_serialized_tensorsremainsNone.
The advantage of this design is that only TP rank 0 needs to pass the collected handle tuples to the SGLang Engine, avoiding the memory overhead of each rank holding a complete list of handle tuples.
SGLang Completes Tensor Reconstruction
Next, the gathered list of handle tuples is passed to the SGLang Engine, and the update_weights_from_tensor interface is called.
if self.device_mesh["infer_tp"].get_local_rank() == 0: await self.inference_engine.update_weights_from_tensor( named_tensors=[ ( name, LocalSerializedTensor(values=gathered_serialized_tensors), ) ], load_format=load_format, # Actually passes None flush_cache=tensor_index == len(named_tensors) - 1, )
The code then moves to the SGLang side. Let's look at the source code for ModelRunner.update_weights_from_tensor. Note that for SGLang, ModelRunner is a very low-level class; above it is the TpModelManager. This means that update_weights_from_tensor is actually called by each TP rank of SGLang. You can refer to this diagram for the specific SGLang architecture:

Let's get back to the main track and examine the update_weights_from_tensor interface executed on each TP rank at the SGLang low level:
def update_weights_from_tensor( self, named_tensors: List[Tuple[str, Union[torch.Tensor, "LocalSerializedTensor"]]], load_format: Optional[str] = None, ): named_tensors = [ (name, _unwrap_tensor(tensor, tp_rank=self.tp_rank)) for name, tensor in named_tensors ] if load_format == "direct": _model_load_weights_direct(self.model, named_tensors) elif load_format in self.server_args.custom_weight_loader: custom_loader = dynamic_import(load_format) custom_loader(self.model, named_tensors) elif load_format is None: self.model.load_weights(named_tensors) else: raise NotImplementedError(f"Unknown load_format={load_format}") return True, "Success" def _unwrap_tensor(tensor, tp_rank): if isinstance(tensor, LocalSerializedTensor): monkey_patch_torch_reductions() tensor = tensor.get(tp_rank) return tensor.to(torch.cuda.current_device()) @dataclass class LocalSerializedTensor: """torch.Tensor that gets serialized by MultiprocessingSerializer (which only serializes a pointer and not the data). The i-th element in the list corresponds to i-th rank's GPU.""" values: List[bytes] def get(self, rank: int): return MultiprocessingSerializer.deserialize(self.values[rank])
Each TP rank calls the _unwrap_tensor interface. In the tensor.get(tp_rank) step, the call chain LocalSerializedTensor.get -> MultiprocessingSerializer.deserialize is followed to deserialize and recover the handle tuple of the full tensor aggregated on the FSDP side. Then, a new Python tensor object is constructed, and the just-recovered handle tuple is assigned as its handle tuple. Through this handle-sharing mechanism, the new tensor object and the aggregated full tensor on the FSDP side share all metadata and naturally point to the same block of GPU memory, completing the tensor reconstruction process. After reconstruction, this new tensor object is passed to ModelRunner.load_weights to replace the original tensor at the SGLang low level.
Weight Synchronization Strategy in slime
With the previous understanding of update_weights_from_tensor, let's further analyze slime's weight synchronization strategy under a co-located policy. slime is a lightweight framework that supports both disaggregated and co-located strategies. In terms of technology choices, slime uses Ray for communication, Megatron for the Training Backend, and SGLang for the Rollout Backend. Thanks to its streamlined design and technology stack, the slime codebase is very clean. We will have more to share on this later. For now, let's continue from the previous discussion and delve into slime's weight synchronization strategy in a co-located setting.
In a co-located strategy, the rollout engine and training engine must continuously offload and upload to free up GPU memory for each other. SGLang manages offloading via torch.memory.caching_allocator, while Megatron uses its own custom memory allocator. Logically, after a rollout concludes, the physical memory is released directly via the memory saver, and then Megatron is started for training. After training, Megatron's model weights and optimizer are all offloaded to the CPU, and then SGLang's model weights and KV cache are uploaded to the GPU.
This is where it gets interesting. For the subsequent parameter update, slime will upload Megatron's model weights to the GPU in buckets. Then, similar to the operation in verl, it aggregates them to get the full tensor, serializes it to get the handle tuple, and passes the handle tuple to the rollout engine, calling the update_weights_from_tensor interface to complete the parameter update.
A very interesting question to share is: why does slime need to offload Megatron's model weights first and then upload them again? Can't they just be kept on the GPU?
The answer lies in slime's more refined handling of weight updates. Specifically, to prevent OOM issues when an extremely large MoE model's entire set of weights is uploaded to the GPU and coexists with SGLang, slime updates parameters in buckets. Only a small portion of parameters within a bucket is updated at a time. If a method similar to verl's were used, keeping all of FSDP's parameters on the GPU, it would still be very easy to run out of memory for very large models unless the TP degree is very high. Based on this, we can see that during slime's update weights phase, the GPU memory usage is almost entirely composed of SGLang's CUDA Graph, model weights, and KV cache, with the uploaded Megatron parameters taking up very little memory. Therefore, in theory, slime does not need the complex multi-stage wake up mechanism we implemented in verl, and SGLang's memory static fraction can be set to a very high level. Unfortunately, since Megatron's offloading is not perfect, there is still room for improvement in the current memory static fraction. We at LMSYS are actively collaborating with the slime team on optimizations.
Alright, with this foundation, let's quickly review the specific weight update process in slime's co-located strategy:
- Establish Communication Group: To be able to gather handle tuples during weight updates, a process group (
_ipc_gather_group) containing all rollout and training engines is established whenslimestarts, withncclas the communication backend. - Clear KV Cache: After the rollout engine updates its parameters, all previous KV cache entries become unusable. Therefore, before the rollout engine updates its parameters, a flush cache command is sent to all rollout engines to clear the radix tree, ensuring that the old KV cache does not affect the new round of rollouts.
- Weight Aggregation: Buckets are constructed, and the Megatron model weights within a bucket are uploaded from CPU to GPU. Then, a
broadcastis performed within the PP/EP group to ensure each rank has the complete parameter in the PP/EP dimension, followed bydist.all_gather+torch.catto complete the aggregation at the TP level, resulting in a full tensor.verlmainly deals with parameters sharded only at the TP level, sofull_tensorcan be used to directly gather theDTensoralong this dimension into a tensor. Inslime, there is multi-dimensional parallelism with different sharding strategies, sofull_tensorcannot be used simply; manual aggregation is required. - Tensor Serialization and Handle Tuple Aggregation: Same as in
verl,MultiprocessingSerializer.serializeis used for serialization to get the handle tuple, followed bydist.gather()to aggregate the handle tuples. - Pass Handle Tuples and Reconstruct Parameters to Complete Update: This part is very similar to what was described before. The aggregated handle tuples are passed to the SGLang Engines, deserialized on the SGLang side, the parameters are reconstructed, and then
ModelRunner.load_weightsis called to complete the update.
Here is some relevant code for better understanding:
slime weight update code
def update_weights_from_tensor(self): pp_size = mpu.get_pipeline_model_parallel_world_size() ep_size = mpu.get_expert_model_parallel_world_size() rank = dist.get_rank() if rank == 0: ray.get([engine.reset_prefix_cache.remote() for engine in self.rollout_engines]) dist.barrier() for param_infos in self.param_info_buckets: # init params: params = [] for info in param_infos: if dist.get_rank() == info.src_rank: params.append( torch.nn.Parameter(self.params_dict[info.name].to(device=torch.cuda.current_device())) ) else: params.append(torch.empty(info.shape, dtype=info.dtype, device=torch.cuda.current_device())) # broadcast params across pp ranks if pp_size > 1: handles = [] for info, param in zip(param_infos, params): if info.src_rank in dist.get_process_group_ranks(mpu.get_pipeline_model_parallel_group()): handles.append( torch.distributed.broadcast( param, src=info.src_rank, group=mpu.get_pipeline_model_parallel_group(), async_op=True ) ) for handle in handles: handle.wait() # broadcast params across ep ranks if ep_size > 1: handles = [] for info, param in zip(param_infos, params): if ".experts." in info.name: src_rank = ( info.src_rank if info.src_rank in dist.get_process_group_ranks(mpu.get_expert_model_parallel_group()) else rank ) handles.append( torch.distributed.broadcast( param, src=src_rank, group=mpu.get_expert_model_parallel_group(), async_op=True ) ) for handle in handles: handle.wait() converted_named_tensors = [] for info, param in zip(param_infos, params): # set tp attrs for key, value in info.attrs.items(): setattr(param, key, value) # gather param param = update_weight_utils.all_gather_param(info.name, param) param = update_weight_utils.remove_padding(info.name, param, self.vocab_size) converted_named_tensors.extend( update_weight_utils.convert_to_hf( self.args, self.model_name, info.name, param, self.quantization_config ) ) self._update_converted_params_from_tensor(converted_named_tensors) def all_gather_param(name, param): if "expert_bias" in name: return param assert hasattr(param, "tensor_model_parallel"), f"{name} does not have tensor_model_parallel attribute" if not param.tensor_model_parallel: # if mpu.get_tensor_model_parallel_world_size() == 1: return param.data if ".experts." in name: tp_size = mpu.get_expert_tensor_parallel_world_size() tp_group = mpu.get_expert_tensor_parallel_group() else: tp_size = mpu.get_tensor_model_parallel_world_size() tp_group = mpu.get_tensor_model_parallel_group() param_partitions = [torch.empty_like(param.data) for _ in range(tp_size)] dist.all_gather(param_partitions, param.data, group=tp_group) partition_dim = param.partition_dim assert param.partition_stride == 1, "partition_stride != 1 is not supported" # TODO: here we did an extra copy during concat, maybe merge this with convert_to_hf is better? # TODO: check only GLU is used. if "linear_fc1.weight" in name: param_partitions = [p.chunk(2, dim=0) for p in param_partitions] param_partitions = [p[0] for p in param_partitions] + [p[1] for p in param_partitions] # this is bug in megatron's grouped moe. if "linear_fc2.weight" in name: if partition_dim == 0: partition_dim = 1 param = torch.cat(param_partitions, dim=partition_dim) return param def _update_converted_params_from_tensor(self, converted_named_tensors): ipc_handle = MultiprocessingSerializer.serialize(converted_named_tensors, output_str=True) ipc_handles = ( [None] * dist.get_world_size(self._ipc_gather_group) if self._ipc_gather_src == dist.get_rank() else None ) dist.gather_object( ipc_handle, object_gather_list=ipc_handles, dst=self._ipc_gather_src, group=self._ipc_gather_group, ) if dist.get_rank() == self._ipc_gather_src: ref = self._ipc_engine.update_weights_from_tensor.remote( ipc_handles=ipc_handles, ) ray.get(ref) converted_named_tensors.clear() torch.cuda.empty_cache()
Comparison of Three Weight Update Methods
Finally, let's compare three weight update methods. As the saying goes, "knowing is easy, but doing is hard." My personal journey into RL system development began with the weight update interface. An RL system just needs to integrate an inference engine, run a series of inferences, and then update the weights after training is complete. However, the bitter-sweet experience can only be truly understood by those who have gone through the grind. By outlining these three weight update interfaces, I am essentially outlining two main approaches:
-
update_weights_from_disk: This is the simplest interface. While ensuring the engine is running, it directly reads weights from the disk and then callsModelRunner.load_weightsdown the line to update the weights. In practice, after each update of the target policy during the RL process, the target policy is saved, and then theupdate_weights_from_diskinterface is called to perform the update. This might not sound efficient, as it involves writing weights to underlying storage and then reading them back, with the overall speed determined by the I/O efficiency of the storage. However, if the read/write speed of the underlying storage is fast enough, or if the SGLang Engine can read from the disk efficiently in parallel, this might not be an unfeasible solution. Furthermore, writing to storage also accomplishes checkpointing. If other interfaces are used for weight updates, checkpoint management requires a separate asynchronous logic. Lastly, I believeupdate_weights_from_diskis the interface best suited for the dynamic scaling needs of rollouts. If, during training, rollouts become surprisingly slow and you're using anupdate_weights_from_distributedsolution, you would have to pause the existing communication group, add a new Rollout Engine, and re-establish the communication group to scale out—a process of considerable engineering complexity. With theupdate_weights_from_diskinterface, you can simply add a new Rollout Engine to the DP router above the Rollout Engines, and all Rollout Engines can then read from the same checkpoint to update their weights.update_weights_from_diskcan be used in both co-located and disaggregated strategies, but frameworks that support co-location mostly adoptupdate_weights_from_tensor. Among mainstream frameworks, AReaL has chosenupdate_weights_from_disk. -
update_weights_from_distributed: This is an interface I implemented. It's logically similar toupdate_weights_from_tensor, butfrom_distributeduses NCCL or InfiniBand for communication between different resource groups and can only be used in a disaggregated strategy. Specifically, when the Training Engine and Rollout Engine are placed in two separate resource groups, a unified communication group is established between them. Each time the training engine finishes updating weights, the sharded weights are gathered parameter by parameter onto TP 0 of the Training Engine, then transferred from the Training Engine's TP 0 to each TP of the Rollout Engine. Each TP of the Rollout Engine then shards the data to take the part it needs, and the parameters are loaded. -
update_weights_from_tensor: This is actually similar toupdate_weights_from_distributed; logically, both require a gathering step. However, as we analyzed earlier,update_weights_from_tensoronly serializes and passes handle tuples, not the actual data. The main difficulty withfrom_tensoris that the co-located strategy often requires strong intrusion into the rollout engine to meet its strict SPMD (Single Program, Multiple Data) requirements. Many optimizations for MoE, like the classic DeepSeek DP Attention, cannot be enabled, whereas these are naturally supported in a disaggregated strategy.