RolloutSystemWalkthrough
文档摘要
Rollout System Walkthrough 文件概述 rollout系统是slime中负责数据生成的核心组件,主要由两个文件组成: : 管理rollout引擎和路由器的生命周期; : 处理rollout数据生成和转换 slime rollout工作流程 核心组件详解 RolloutManager - 协调器 作用 RolloutManager是rollout系统的主控制器,负责协调Router、Controller和Engines之间的交互。 初始化流程 RolloutManager初始化 关键方法 A. 数据生成 asyncgenerate方法 B. 评估 asynceval方法 C.
Rollout System Walkthrough
文件概述
rollout系统是slime中负责数据生成的核心组件,主要由两个文件组成:
slime/ray/rollout.py:class RolloutManager管理rollout引擎和路由器的生命周期;slime/ray/buffer.py:class RolloutController处理rollout数据生成和转换
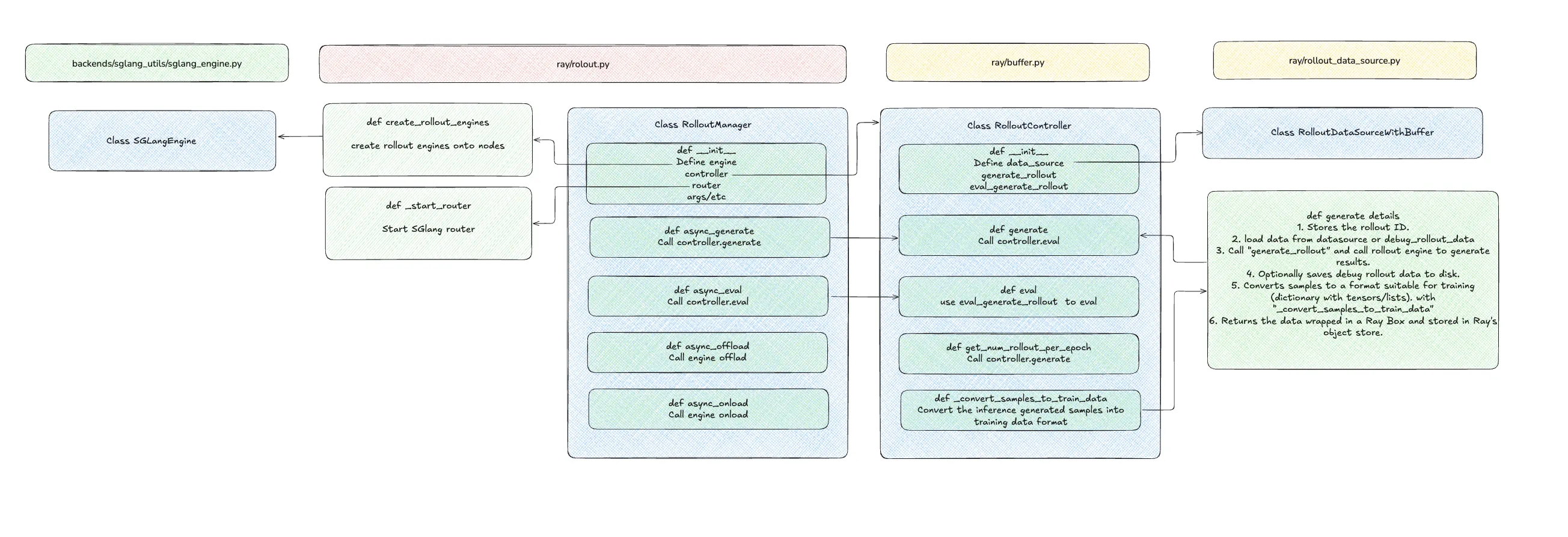
核心组件详解
RolloutManager - 协调器
作用
RolloutManager是rollout系统的主控制器,负责协调Router、Controller和Engines之间的交互。
初始化流程
RolloutManager初始化
class RolloutManager: def __init__(self, args, pg, wandb_run_id): self.args = args # 1. 启动Router _start_router(args) # 2. 创建Controller self.controller = RolloutController.options( num_cpus=1, num_gpus=0, ).remote(args, wandb_run_id=wandb_run_id) # 3. 创建Engine池 self.all_rollout_engines = create_rollout_engines(args, pg) # 4. 多节点配置:只向每个engine的node-0发送请求 nodes_per_engine = max(1, args.rollout_num_gpus_per_engine // args.rollout_num_gpus_per_node) self.rollout_engines = self.all_rollout_engines[::nodes_per_engine] # 5. 创建锁 self.rollout_engine_lock = Lock.options( num_cpus=1, num_gpus=0, ).remote()
关键方法
A. 数据生成
async_generate方法
def async_generate(self, rollout_id): return self.controller.generate.remote(rollout_id)
B. 评估
async_eval方法
def async_eval(self, rollout_id): return self.controller.eval.remote(rollout_id)
C. 内存管理 onload/offload
onload/offload
def async_offload(self): return [engine.release_memory_occupation.remote() for engine in self.rollout_engines] def async_onload(self, tags: List[str] = None): return [engine.resume_memory_occupation.remote(tags=tags) for engine in self.rollout_engines]
create_rollout_engines - 引擎创建
作用
创建SGLang引擎池,负责模型推理服务。
核心逻辑
create_rollout_engines实现
def create_rollout_engines(args, pg): if args.debug_train_only: return [] # 计算引擎配置 num_gpu_per_engine = min(args.rollout_num_gpus_per_engine, args.rollout_num_gpus_per_node) num_engines = args.rollout_num_gpus // num_gpu_per_engine # 创建Ray Actor RolloutRayActor = ray.remote(SGLangEngine) rollout_engines = [] for i in range(num_engines): num_gpus = 0.2 # 每个引擎使用0.2个GPU num_cpus = num_gpus # 设置调度策略 scheduling_strategy = PlacementGroupSchedulingStrategy( placement_group=pg, placement_group_capture_child_tasks=True, placement_group_bundle_index=reordered_bundle_indices[i * num_gpu_per_engine], ) # 创建引擎 rollout_engines.append( RolloutRayActor.options( num_cpus=num_cpus, num_gpus=num_gpus, scheduling_strategy=scheduling_strategy, runtime_env={"env_vars": {name: "1" for name in NOSET_VISIBLE_DEVICES_ENV_VARS_LIST}}, ).remote(args, rank=i) ) # 端口分配和初始化 # ... 端口分配逻辑 ... # 初始化所有引擎 init_handles = [engine.init.remote(**ports) for engine, ports in zip(rollout_engines, addr_and_ports)] ray.get(init_handles) return rollout_engines
关键特点:
- 资源分配:每个引擎使默认用0.2个GPU
- 多节点支持:支持跨节点部署
- 端口管理:自动分配服务器端口、NCCL端口等
- 初始化同步:等待所有引擎初始化完成
_start_router - 路由器启动
作用
启动SGLang路由器,提供负载均衡服务。
实现细节
_start_router实现
def _start_router(args): if args.sglang_router_ip is not None: return # 使用外部Router from sglang_router.launch_router import RouterArgs # 自动分配IP和端口 args.sglang_router_ip = get_host_info()[1] args.sglang_router_port = find_available_port(random.randint(3000, 4000)) # 配置Router参数 router_args = RouterArgs( host=args.sglang_router_ip, port=args.sglang_router_port, balance_abs_threshold=0, ) # 设置日志级别和超时 if hasattr(router_args, "log_level"): router_args.log_level = "warn" if hasattr(router_args, "request_timeout_secs"): router_args.request_timeout_secs = args.sglang_router_request_timeout_secs # 启动Router进程 process = multiprocessing.Process( target=run_router, args=(router_args,), ) process.daemon = True process.start() # 等待启动完成 time.sleep(3) assert process.is_alive()
RolloutController - 执行器
作用
RolloutController是rollout系统的核心执行器,负责数据生成、转换和管理。
初始化
RolloutController初始化
@ray.remote class RolloutController: def __init__(self, args, wandb_run_id): self.args = args init_wandb_secondary(args, wandb_run_id) # 创建数据源 self.data_source = RolloutDataSourceWithBuffer(args) # 动态加载rollout函数 self.generate_rollout = load_function(self.args.rollout_function_path) self.eval_generate_rollout = load_function(self.args.eval_function_path) print(f"import {self.args.rollout_function_path} as generate_rollout function.") print(f"import {self.args.eval_function_path} as eval_generate_rollout function.")
关键特性:
- 动态函数加载:支持自定义rollout函数
- SFT支持:通过
--rollout-function-path可以切换到SFT模式 - 数据源管理:使用带缓冲的数据源
generate方法 - 核心生成流程
generate方法实现
def generate(self, rollout_id): self.rollout_id = rollout_id # 1. 调试模式:从磁盘加载数据 if self.args.load_debug_rollout_data: data = torch.load( open(self.args.load_debug_rollout_data.format(rollout_id=rollout_id), "rb"), )["samples"] data = [Sample.from_dict(sample) for sample in data] else: # 2. 正常模式:调用rollout函数生成数据 data = self.generate_rollout(self.args, rollout_id, self.data_source, evaluation=False) # 3. 扁平化数据(如果是嵌套列表) if isinstance(data[0], list): data = sum(data, []) # 4. 可选:保存调试数据 if (path_template := self.args.save_debug_rollout_data) is not None: path = Path(path_template.format(rollout_id=self.rollout_id)) print(f"Save debug rollout data to {path}") path.parent.mkdir(parents=True, exist_ok=True) torch.save( dict( rollout_id=self.rollout_id, samples=[sample.to_dict() for sample in data], ), path, ) # 5. 转换为训练数据格式 data = self._convert_samples_to_train_data(data) # 6. 包装并返回 return Box(ray.put(data))
生成流程:
- 存储rollout ID:记录当前rollout标识
- 数据获取:从调试文件或rollout函数获取数据
- 数据扁平化:处理嵌套数据结构
- 调试保存:可选保存调试数据
- 格式转换:转换为训练数据格式
- Ray存储:包装到Ray对象存储
eval方法 - 评估流程
eval方法实现
def eval(self, rollout_id): if self.args.debug_train_only: return # 调试模式不生成评估数据 # 调用评估rollout函数 data = self.eval_generate_rollout(self.args, rollout_id, self.data_source, evaluation=True) # 记录评估数据 log_eval_data(rollout_id, self.args, data)
_convert_samples_to_train_data - 数据转换
作用
将生成的Sample对象转换为训练所需的字典格式。
转换逻辑
_convert_samples_to_train_data实现
def _convert_samples_to_train_data(self, samples: Union[list[Sample], list[list[Sample]]]): """ Convert inference generated samples to training data. """ # 基础训练数据 train_data = { "tokens": [sample.tokens for sample in samples], "response_lengths": [sample.response_length for sample in samples], "rewards": [sample.get_reward_value(self.args) for sample in samples], "truncated": [1 if sample.status == Sample.Status.TRUNCATED else 0 for sample in samples], "sample_indices": [sample.index for sample in samples], } # 处理loss mask loss_masks = [] for sample in samples: # 如果没有提供loss_mask,创建默认的 if sample.loss_mask is None: sample.loss_mask = [1] * sample.response_length # 验证loss_mask长度 assert ( len(sample.loss_mask) == sample.response_length ), f"loss mask length {len(sample.loss_mask)} != response length {sample.response_length}" loss_masks.append(sample.loss_mask) train_data["loss_masks"] = loss_masks # 处理raw reward if samples[0].metadata and "raw_reward" in samples[0].metadata: train_data["raw_reward"] = [sample.metadata["raw_reward"] for sample in samples] # 处理round_number(用于rollout buffer) if samples[0].metadata and "round_number" in samples[0].metadata: train_data["round_number"] = [sample.metadata["round_number"] for sample in samples] return train_data
转换内容:
- tokens:prompt + response的token序列
- response_lengths:response的token长度
- rewards:奖励值
- truncated:是否被截断的标志
- sample_indices:样本索引
- loss_masks:损失掩码
- raw_reward:原始奖励(可选)
- round_number:轮次编号(可选)
log_eval_data - 评估日志
作用
记录评估数据到wandb和控制台。
log_eval_data实现
def log_eval_data(rollout_id, args, data): log_dict = {} for key in data.keys(): rewards = data[key]["rewards"] log_dict[f"eval/{key}"] = sum(rewards) / len(rewards) if "truncated" in data[key]: truncated = data[key]["truncated"] log_dict[f"eval/{key}-truncated_ratio"] = sum(truncated) / len(truncated) print(f"eval {rollout_id}: {log_dict}") if args.use_wandb: log_dict["eval/step"] = ( rollout_id if not args.wandb_always_use_train_step else rollout_id * args.rollout_batch_size * args.n_samples_per_prompt // args.global_batch_size ) wandb.log(log_dict)
组件关系详解
1. 组件关系概览
上图展示了slime rollout系统中各组件的关系。整个系统采用分层架构,实现了职责分离和高效协作。
2. 数据流向
A. 生成请求流
训练进程发起生成请求,经过Manager协调、Controller执行、Engine推理的完整流程,最终返回训练数据。
B. 管理操作流
- 内存管理:Manager直接调用Engine的offload/onload方法
- 状态管理:Controller管理数据源的状态保存和加载
- 评估:Controller调用评估函数并记录日志
3. 与Dataset的交互
参考Dataset Walkthrough,数据源交互流程:
- Controller拥有
RolloutDataSourceWithBuffer实例 - 生成时:调用
data_source.get_samples()获取prompt样本 - Buffer管理:支持partial rollout和over-sampling的数据重用
- 状态持久化:支持训练中断恢复
自定义Rollout支持
1. 函数路径配置
# RL模式(默认) --rollout-function-path slime.rollout.sglang_rollout.generate_rollout # SFT模式 --rollout-function-path slime.rollout.sft_rollout.generate_rollout # 自定义模式 --rollout-function-path path.to.custom.generate_rollout
2. 函数签名要求
def generate_rollout(args, rollout_id, data_source, evaluation=False) -> list[list[Sample]]: """ Args: args: 全局参数 rollout_id: rollout标识 data_source: 数据源 evaluation: 是否为评估模式 Returns: list[list[Sample]]: 生成的样本组 """ # 实现逻辑 return samples
3. SFT模式特点
SFT模式通过自定义rollout函数实现:
- 数据读取:从文件读取预生成的样本
- 格式转换:转换为训练数据格式
- 复用架构:完全复用RL的架构和流程
关键配置参数
| 参数 | 说明 | 默认值 |
|---|---|---|
rollout_num_gpus_per_engine |
每个引擎使用的GPU数量 | 0.2 |
rollout_num_gpus |
总GPU数量 | - |
rollout_function_path |
rollout函数路径 | slime.rollout.sglang_rollout.generate_rollout |
eval_function_path |
评估函数路径 | - |
sglang_router_ip |
Router IP地址 | None(自动分配) |
sglang_router_port |
Router端口 | None(自动分配) |
设计特点总结
- 分层架构:Manager协调、Controller执行、Engine推理
- 异步设计:所有主要操作都是异步的
- 可扩展性:支持多引擎负载均衡和多节点部署
- 灵活性:支持自定义rollout函数和SFT模式
- 容错性:支持训练中断恢复和状态持久化
- 资源管理:精确的GPU分配和内存管理
这个架构使得rollout系统既高效又灵活,能够支持各种复杂的强化学习和监督学习训练场景!