第4章:流形假设——高维数据的隐秩序
文档摘要
第4章:流形假设——高维数据的隐秩序 你以为数据是随机散布在高维空间的。它不是。它挤在一个薄薄的曲面上。 一、维度的荒谬 先做一个思想实验。 在一条线段上,随机撒 100 个点。平均而言,相邻两点之间的距离大约是线段长度的 1/100——密度很高,采样充分。 现在把这 100 个点放进一个正方形里。为了保持同样的采样密度,你需要 $100^2 = 10000$ 个点。 放进一个正方体呢?需要 $100^3 = 1000000$ 个点。 这就是维度诅咒(Curse of Dimensionality)——Bellman 在 1957 年命名这个现象时,大概没想到它会成为整个机器学习领域的幽灵。 维度诅咒说的是:当数据的维度增加时,覆盖同等密度的空间需要指数级增长的样本量。
第4章:流形假设——高维数据的隐秩序
你以为数据是随机散布在高维空间的。它不是。它挤在一个薄薄的曲面上。
一、维度的荒谬
先做一个思想实验。
在一条线段上,随机撒 100 个点。平均而言,相邻两点之间的距离大约是线段长度的 1/100——密度很高,采样充分。
现在把这 100 个点放进一个正方形里。为了保持同样的采样密度,你需要 100^2 = 10000 个点。
放进一个正方体呢?需要 100^3 = 1000000 个点。
这就是维度诅咒(Curse of Dimensionality)——Bellman 在 1957 年命名这个现象时,大概没想到它会成为整个机器学习领域的幽灵。
:::details 维度诅咒:为什么高维空间里什么都稀疏?
维度诅咒说的是:当数据的维度增加时,覆盖同等密度的空间需要指数级增长的样本量。
直觉例子:
- 1维线段(0到1)上撒100个点,平均间距 = 0.01,还算密集
- 2维正方形里想保持同样密度,需要 100² = 10,000 个点
- 10维超立方体里需要 100¹⁰ = 10²⁰ 个点——比可观测宇宙里的原子数还多
这不只是"需要更多数据"这么简单。更根本的是:在高维空间里,距离这个概念失去了意义——所有点之间的距离都趋于相等,"近邻"变得无法区分。
这就是为什么很多在低维有效的算法(k-NN、聚类)在高维下效果很差。而流形假设(见下文)恰好提供了一个出路:真实数据不是均匀散布在高维空间里的,它有低维结构。
:::
随维度增长,要覆盖同等密度的空间,所需样本量呈指数级膨胀。但这只是问题的表层。真正诡异的事情,发生在几何上。
在一个 d 维单位超球里,随机取两个点,它们之间的距离满足:
而距离的方差趋于零。
这意味着:在高维空间里,所有点之间的距离都趋于相等。最近邻和最远邻变得几乎一样远。基于距离的相似性度量——余弦相似度、欧氏距离、k-NN 分类——在高维下全部失效,因为”近”这个概念丧失了辨别力。
如果你随机初始化两个 1000 维向量,它们的余弦相似度几乎一定接近零。不是因为它们语义相反,而是因为在 1000 维里,随机向量几乎一定正交。
正交意味着什么? 两个向量正交,即 \vec{u} \cdot \vec{v} = 0,在几何上意味着它们彼此垂直、互不相关——一个向量在另一个向量方向上的投影为零。在低维里,正交是一种特殊关系,需要刻意构造。在高维里,正交是默认状态,是随机的必然结果。
这个事实在两个地方对我们构成了回响。
回响一:专家系统的概念空间。 第二章里,专家系统用离散符号表示知识——"是哺乳动物"、"有翅膀"、"会飞",每个符号是一个原子,概念之间的关系必须显式写进规则。从高维几何的角度重新看这件事:每个离散符号,相当于在某个正交基上放了一个维度。"猫"和"狗"在符号系统里没有内在关联,它们是两个独立的 token,正如两个随机单位向量几乎必然正交。专家系统的本质困境——无法自动捕获概念之间的连续相似性——从这个角度看,就是因为它把世界强行嵌入了一个人工正交基里。世界不是正交的,但符号系统假装它是。
::: info 兔狲教授评
高维空间的正交性不是 bug,而是 feature。在极高维度下,随机向量几乎必然正交——这意味着它们天然解耦,彼此独立。这种解耦性正是高维嵌入表示学习能够成功的前提:每个维度可以独立地刻画不同语义 aspect,而不需要像低维空间那样彼此"粘合"。
专家系统的问题恰恰在于它故意制造了这种正交性,但是在一个极其低效的维度上。它把每个概念硬编码为一个正交基向量,创造了有限维度的、人工的、离散的正交表示。这种表示在概念上干净,但在表征效率上极其低下——它无法捕获概念之间的连续相似性,也无法利用高维空间天然的正交性所提供的"免费午餐"。
真正的高维嵌入(如词向量)之所以强大,是因为它们让数据自己决定如何在保持语义连续性的同时,利用高维空间的正交性。训练过程不是强行正交化,而是让统计约束把向量推到流形上——这个流形既不是完全正交的随机沙漠,也不是完全相关的低维泥潭,而是一个精心折叠的、语义丰富的曲面。
:::
回响二:词向量的类比算术。 第三章里,我们看到 \vec{\text{King}} - \vec{\text{Man}} + \vec{\text{Woman}} \approx \vec{\text{Queen}} 这个漂亮的等式,并追问:这是推理,还是统计巧合?现在有了高维正交的背景,可以更精确地说出它的局限:词向量之所以能做这个算术,恰恰是因为训练数据把词向量推离了随机初始化的正交状态——语料里的共现约束,把随机向量拉进了一个低维的语义流形。类比算术有效,是流形结构的功劳,不是算法的智慧。而当类比失败时(医生 - 男人 + 女人 ≈ 护士,而非女医生),原因是训练语料的偏见把流形扭曲了——语义空间在那个区域的曲率,不是”客观概念”的曲率,而是”语料统计偏见”的曲率。
这两个回响指向同一个问题:如果随机高维空间是正交的沙漠,那么”有意义的数据”之所以能被学习,一定是因为数据不是随机的——它被某种约束压缩进了一个低维结构。这就是流形假设要说的事情。

图1:左图,随机点对在 2、10、100、1000 维空间中的距离分布。维度越高,分布越集中,方差趋零——“距离”失去区分能力。右图,1000 维随机向量两两余弦相似度的直方图,几乎全部堆积在零附近。
这给机器学习带来了一个根本性的问题:如果数据真的是高维随机的,那么任何基于距离或相似度的算法——包括神经网络在内——都不应该能工作。
但它们工作了。
这里有两种可能的解释:
第一,这些算法以某种我们没有完全理解的方式,绕过了高维几何的限制。
第二,数据本身就不是高维随机的。
第二种解释是对的。
停顿一下
等一下,先别急着接受"第二种解释是对的"这个结论。
为什么自然数据会聚集在低维流形上?这是一个需要解释的事实,不是公理。
一种答案是:物理定律约束了可能的状态空间——人脸的变化受制于骨骼、肌肉、光照物理,所以可能的人脸远少于可能的像素组合。
但这个答案暗含了一个假设:世界是有规律的,而这些规律是低维的。
这个假设凭什么成立?如果世界的真实规律是高维的、混沌的,流形假设就会崩塌——机器学习就不应该能工作。
那为什么它确实工作了?是因为物理规律确实是低维的,还是因为我们恰好只在"流形假设成立的那些问题"上测试过它?
先把这个问题放着。
二、流形假设:约束造就曲面
流形假设(Manifold Hypothesis)的核心陈述是:
自然数据(图像、语言、声音)虽然生活在高维空间里,但它们实际上聚集在一个内在维度远低于环境维度的光滑曲面(流形)附近。
“流形”是一个数学术语,意思是局部看起来像欧氏空间的拓扑结构。一张二维曲面嵌入在三维空间里,就是一个流形——地球表面是流形,莫比乌斯带是流形,一根弯曲的管道的表面是流形。
:::details 流形(Manifold):用地球表面来理解
流形是一种几何对象,它的定义是:局部看起来”平坦”(像普通的欧氏平面),但整体可以是弯曲的。
最好的例子:地球表面。你站在地球上的任意一点,如果只看脚下很小的一块,它看起来和平地没什么区别——这就是”局部像欧氏空间”。但整体来看,地球表面是球形的,不是平面。地球表面是一个二维流形,嵌入在三维空间里。
在机器学习语境里:
- 49152 维的人脸图片空间 = 三维空间的类比
- 人脸真实分布所在的几十维曲面 = 地球表面的类比
为什么流形假设重要? 因为它解释了为什么机器学习能工作:数据不是高维随机的,而是聚集在低维曲面上,算法实际上是在学习这个低维曲面的结构。
:::
用一个具体的例子来建立直觉:
128 \times 128 的彩色人脸图片,作为向量,维度是 128 \times 128 \times 3 = 49152。在这个空间里,可能的像素组合有 256^{49152} 种——比宇宙中的原子数多出无数个数量级。
但”真实的人脸”只占这个空间里极小的一片区域。一张真实的人脸,由什么参数决定?
-
身份(谁的脸)
-
姿态(头转了多少度,仰角几度)
-
光照(光从哪里来,强度多少)
-
表情(微笑?皱眉?)
-
年龄
大约十几个到几十个参数,就能描述一张人脸的绝大多数变化。这意味着,人脸图片的内在维度大约是几十维,而不是 49152 维。
图像数据挤在一个嵌入在 49152 维空间中的、约几十维的流形上。
语言数据也是如此。“合法的英语句子”在所有可能的词序列里,只占极小的一部分。“合理的语义”在所有合法英语句子里,又只占更小的一部分。每一层约束,都是对流形的一次折叠和压缩。

图2:左图,一个二维流形(Swiss Roll 数据集)嵌入在三维空间里——三维坐标看起来复杂,但数据沿两个内在维度(展开后的 u, v 坐标)平滑分布。右图,对同一数据集做流形学习(UMAP),恢复内在的二维结构。颜色编码内在坐标的连续性——局部邻近在高维空间里保持邻近。
为什么自然数据会聚集在流形上?这不是巧合,是生成过程的必然结果。
任何数据都是由某个生成过程产生的。人脸图片由生物过程产生——DNA、骨骼结构、皮肤纹理,这些参数是有限的,而且是连续变化的。语言由语法规则和语义约束产生。音乐由物理学(声波)和文化惯例产生。
生成过程的约束就是流形的曲率。约束越强,流形越低维,越弯曲。
这是一个深刻的事实:数据的内在维度,不是数据的固有属性,而是生成数据的世界结构的投影。
三、训练是折叠
现在我们到了这一章最重要的地方。
通常我们说神经网络在”学习”——学习识别猫,学习翻译语言,学习预测下一个词。这个说法很危险。“学习”暗示了某种理解,某种将知识内化的过程。
更准确的说法是:神经网络在做流形变换。
把一个自动编码器(Autoencoder)的工作原理展开来看:
其中 d \ll D。训练目标是最小化重建误差 \|x - \hat{x}\|^2。
这里发生了什么?编码器 f 学会了把高维输入映射到低维潜在空间 z,而这个低维空间恰好就是数据流形的坐标系。解码器 g 学会了从流形坐标重建高维输入。
换句话说,编码器学会的,是流形的参数化——它找到了一组坐标,可以用来描述流形上的点。解码器学会的,是这组坐标和原始高维表示之间的映射。
不只是自动编码器。分类网络做的也是这件事。当你训练一个 ResNet 识别图像类别,最后一个全连接层之前的特征向量,就是网络学到的流形坐标——只是这个坐标系被专门设计成”对分类有用的”。
反向传播,就是调整这个坐标系的过程。每一次梯度更新,都在改变网络把高维输入映射到低维潜在空间的方式——也就是改变流形的参数化。
训练的本质,是把过去见过的数据的流形结构,折叠进参数的曲率里。
“折叠”这个词很重要。不是”存储”,不是”记忆”,是折叠。训练数据不是被逐条存进网络的——网络没有那么多参数来存储训练集的每一个样本。发生的事情是:数据的统计结构,数据所在的流形的几何特征,被压缩进了网络权重的配置里。
10^6 张人脸图片,每张 49152 维。ResNet-50 大约有 2.5 \times 10^7 个参数。用 2500 万个数字,记住了 49 亿个像素值所描述的流形结构。压缩比大约是 200:1。
这不是学习。这是拓扑压缩。
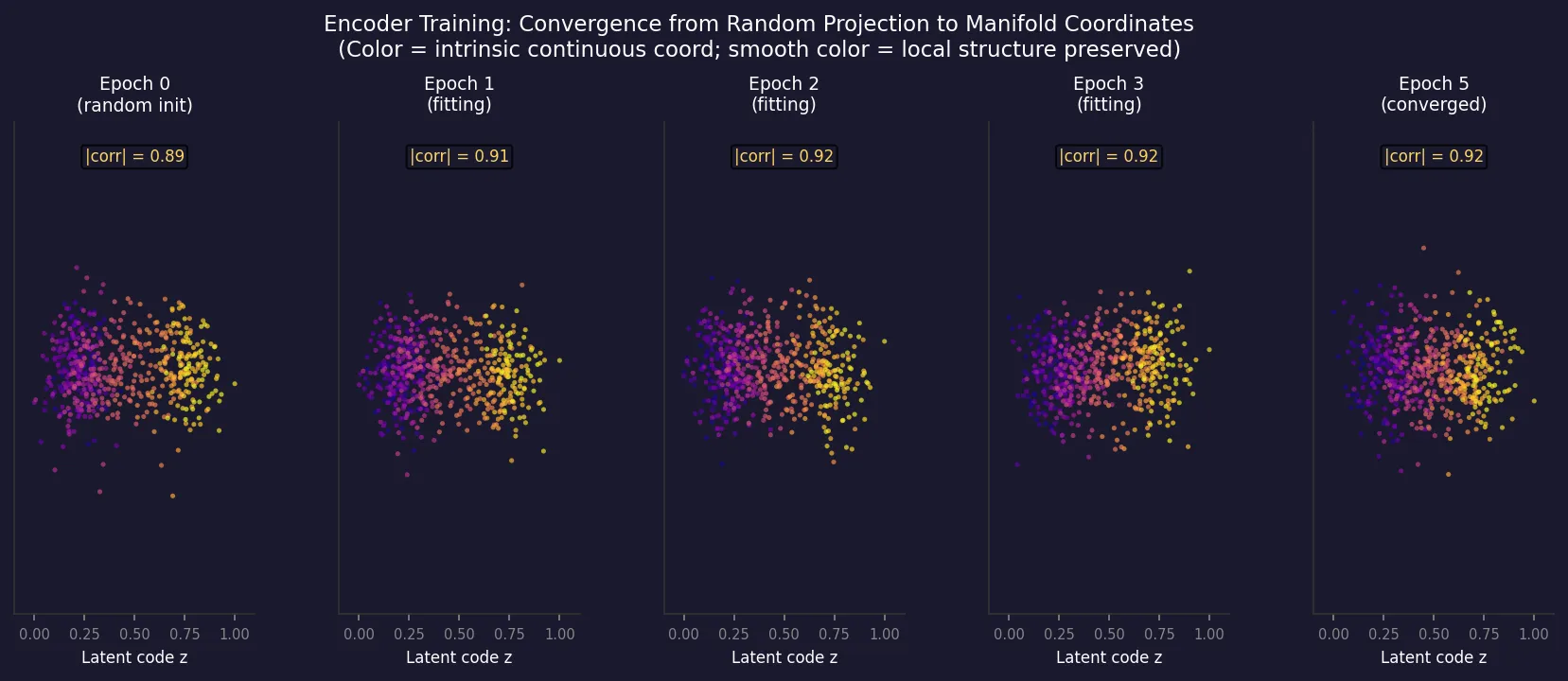
图3:上方,编码器将高维数据(散布在二维流形上的三维点云)逐步映射到一维潜在编码。下方,训练过程中潜在空间的演化——随着 epoch 增加,潜在表示从混乱走向结构化。颜色代表数据在原始流形上的连续坐标,颜色连续意味着局部结构被保留。
这里有一个值得停下来想的深层问题:参数里存的是什么?
一个直觉是:参数存储的是”知识”——关于猫长什么样,关于语法规则,关于物理定律。
但更准确的说法是:参数存储的是训练数据的流形结构的压缩编码。
知道了这一点,你就能理解为什么预训练有效——同一个流形(比如”自然图像”)可以被多个任务共享,预训练学到的流形参数化可以被迁移。
你也能理解为什么微调(fine-tuning)有时候能改变模型行为,有时候不能——取决于你的新任务所在的流形,是否是预训练流形的子集。
以及,你开始能理解为什么大模型会产生幻觉——关于这一点,第四幕会讲。
四、压缩的账单
任何压缩都有代价。这不是经验观察,这是信息论定理。
Shannon 的信源编码定理告诉我们:你能无损压缩的极限,是信源的熵。超过这个极限,你必须丢信息。神经网络的压缩远超这个极限,所以它一定在丢信息。
丢的是什么?
第一笔账:流形外的点
训练结束后,网络的参数里编码了训练数据所在的流形。当测试时遇到了不在这个流形上的点——来自不同分布的图像,从未见过的语言现象,反事实的推理场景——网络会怎么做?
它没有一个”这个点不在我的流形上”的警报。它只能把这个点硬拉到最近的流形区域,然后按照那个区域的逻辑给出答案。
结果:自信的错误。不是”我不知道”,而是”它看起来像 X,所以我回答 X”——即使 X 是完全错误的。
这就是分布偏移(Distribution Shift)问题的几何根源:模型学到的流形,和真实世界的流形,在训练分布之外的地方不一致。偏移越大,误差越大,但置信度不变——因为置信度是流形坐标的函数,不是”距离流形有多远”的函数。
第二笔账:流形内部的等距性
压缩时,流形的某些区域被”伸展”,某些区域被”压缩”。
训练数据密集的地方,网络学到的参数化分辨率高——相邻的输入对应着相邻的潜在编码,局部几何被很好地保存。
训练数据稀疏的地方,网络参数化的分辨率低——相邻的输入可能被映射到潜在空间里相差很远的地方,或者相差很远的输入被映射到潜在空间里相邻的地方。
这意味着,网络对训练数据密集区域的泛化好,对稀疏区域的泛化差——不是随机的差,而是有规律的差:稀疏区域的流形结构被”脑补”出来,填充的是训练数据最常见的模式,而不是这个区域真实的结构。
脑补填充的结果,就是幻觉(hallucination)。
第三笔账:Tishby 的信息瓶颈
Naftali Tishby 在 2017 年提出了一个关于这个过程的理论框架——信息瓶颈(Information Bottleneck)。
训练一个神经网络,本质上是在做一个 trade-off:
其中 X 是输入,Y 是标签,Z 是中间表示,I(\cdot;\cdot) 是互信息,\beta 是权衡参数。
第一项 I(X; Z),衡量中间表示 Z 保留了多少输入信息——越小越好,意味着压缩得越多。
第二项 I(Z; Y),衡量中间表示 Z 保留了多少关于标签的信息——越大越好,意味着对任务越有用。
这个 trade-off 的最优解,是一个”充分统计量”——保留了预测标签所需的全部信息,丢弃了所有冗余信息。
Tishby 的主张是:训练过程在两个阶段发生——先是”拟合”阶段,互信息 I(Z; Y) 快速增加,网络在学习捕获与标签相关的信息;然后是”压缩”阶段,I(X; Z) 开始下降,网络开始丢弃与标签无关的信息。
这个理论很漂亮。但它也是争议性的——后续研究(Saxe et al., 2018)发现,压缩阶段在很多情况下并不出现,取决于激活函数的选择。信息瓶颈是一个有价值的分析框架,但不是一个完整的理论 → [Tishby & Schwartz-Ziv, 2017, arXiv:1703.00810] → [Saxe et al., 2018, arXiv:1812.09881]。
最终的账
把三笔账加起来,流形压缩的代价是:
-
分布内:泛化好,置信度准确
-
分布边缘:泛化开始退化,置信度仍然高(危险区)
-
分布外:泛化差,但置信度依然可以很高(最危险区)
网络不知道自己站在流形的边缘。它只知道当前的输入映射到了潜在空间的某个坐标,然后按照那个坐标的逻辑输出。没有内置的”不确定性感应器”告诉它:你正在对一个你从未真正理解过的区域做推断。
这不是 bug,这是流形压缩的必然结构性后果。
五、压缩的极限:流形能被压到多小?
流形假设说高维数据挤在低维流形上。那么这个"低维"有多低?可以压缩到什么程度?
这是一个信息论问题,而不仅仅是几何问题。
速率-失真理论给出了下界
Shannon 的速率-失真理论告诉我们:要以失真度 D 重建一个信号,至少需要 R(D) 比特的信息。这个 R(D) 是一个信息论下界,无论用什么压缩算法都无法突破。
对于流形上的数据:
当你把神经网络的隐层维度从 d 压缩到 k 时,你实际上是在做一个有损压缩——原始流形的某些细节不可避免地丢失了。
内在维度
流形的内在维度(intrinsic dimensionality)是描述流形所需的最少坐标数。这个量可以用两点距离的分布来估计:
其中 r 是近邻半径,R 是最大半径。
实验结果令人惊讶:ImageNet 图片的内在维度约为 40,远小于原始像素维度(224 \times 224 \times 3 \approx 150{,}000)。语言模型的表示空间内在维度约为 13-20,远小于隐层维度(768 或更高)。
这说明现实世界的数据,确实挤在极低维的流形上。
但存在一个硬下界
压缩不是无限的。一旦压缩到内在维度以下,失真急剧上升——你开始丢失流形本身的结构,而不仅仅是丢失噪声。
这就是为什么知识蒸馏(从大模型压缩到小模型)有一个性能悬崖:超过某个压缩比,模型不是"差一点",而是"彻底垮掉"。速率-失真曲线在拐点之后急剧下降。
这个硬下界,以及如何用随机化突破确定性压缩的极限,是第11章的主题。
六、一个小小的停顿
让我梳理一下这一章做了什么。
高维空间里,随机数据是无法被学习的——距离失去意义,采样需要指数级的数据量。机器学习之所以有效,不是因为它克服了高维,而是因为数据本身不是高维随机的。自然数据聚集在低维流形上,这是生成数据的物理过程、生物约束、语法规则共同作用的结果。
神经网络的训练,是把训练数据的流形结构压缩进参数的过程。不是存储,是压缩。压缩比大约是 100:1 到 1000:1 的量级。
压缩有不可避免的代价:流形外的点被强行投影,稀疏区域的结构被脑补,分布偏移时置信度和准确率脱钩。这些代价不是工程缺陷,是信息论约束的结构性后果。
这引出了第五章的问题:如果模型学到的是流形结构,而不是因果规律,那么它在分布之外的表现为什么总是系统性地失败?统计相关性和真正的推理,差距究竟在哪里?
流形告诉我们数据在哪里,但不告诉我们模型学到的是不是真正的规律。下一章,我们将看到统计拟合如何成为推理的陷阱。
悬而未决
-
神经网络学到的流形,和真实世界数据的流形,到底有多”吻合”?我们没有好的工具来测量这个吻合程度。
-
流形的内在维度可以被估计吗?有哪些方法,各有什么假设?在 LLM 的激活空间里,内在维度是多少?
-
“压缩”丢失的那部分信息,是否包含了推理所需要的结构?还是说推理能力,恰好藏在被保留下来的部分里?
-
如果你用完全随机的数据训练一个神经网络,它会学到什么样的”流形”?这个思想实验的答案,会告诉我们流形假设的必要性。
-
信息瓶颈的两阶段理论(拟合 + 压缩)在实验上仍有争议。如果压缩阶段不存在,神经网络泛化的原因是什么?
-
知识的流形结构:知识图谱是离散符号流形,词向量是连续语义流形。这两种流形如何相互映射、相互验证?是否存在一个统一的"知识流形"理论?
-
多层次的流形:物理系统(生命)的相空间流形、符号系统(知识)的逻辑空间流形、统计系统(学习)的表示空间流形——这些不同层次的流形之间是否存在同构或映射关系?
自己动手:压缩一个流形,然后找到它的账单
这一章说的核心命题是:压缩有代价,代价的位置不是随机的,是有规律的。你要用一个最小的自动编码器亲手验证这件事——不是为了得到一个好模型,是为了精确地找到压缩在哪里撒了谎。
第一步:生成你的流形数据
不要用真实数据集,那会有太多干扰。从一个你完全理解生成过程的流形开始。
生成以下数据之一:
选项 A:二维圆环嵌入三维
import numpy as np import matplotlib.pyplot as plt np.random.seed(42) N = 2000 # 采样点数 # 均匀采样圆环的两个角度参数 t = np.random.uniform(0, 2 * np.pi, N) # 绕主轴的角度 phi = np.random.uniform(0, 2 * np.pi, N) # 绕管道截面的角度 r = 3.0 # 主圆环半径 tube = 1.0 # 管道半径 # 圆环参数方程:嵌入三维空间 x = (r + tube * np.cos(phi)) * np.cos(t) y = (r + tube * np.cos(phi)) * np.sin(t) z = tube * np.sin(phi) # 加入少量高斯噪声模拟测量误差 noise_std = 0.05 x += np.random.normal(0, noise_std, N) y += np.random.normal(0, noise_std, N) z += np.random.normal(0, noise_std, N) # 拼成数据矩阵,shape=(N, 3) data_torus = np.stack([x, y, z], axis=1) # 保存内在坐标用于后续染色(t 是主角度,phi 是管道角度) intrinsic_t = t intrinsic_phi = phi # 可视化(用 t 值染色) fig = plt.figure(figsize=(8, 6)) ax = fig.add_subplot(111, projection='3d') sc = ax.scatter(x, y, z, c=t, cmap='hsv', s=2, alpha=0.6) plt.colorbar(sc, label='内在坐标 t') ax.set_title('圆环流形(选项A)') plt.tight_layout() plt.show()
选项 B:Swiss Roll(本章图示数据)
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_swiss_roll np.random.seed(42) N = 2000 # 采样点数 # 使用 sklearn 生成标准 Swiss Roll # t 是内在坐标(卷轴角度),z 是高度方向的内在坐标 data_swiss, t_swiss = make_swiss_roll(n_samples=N, noise=0.1, random_state=42) # data_swiss shape=(N, 3),列分别是 x, y, z(三维嵌入坐标) # 或者手动生成(效果等价): t_manual = np.random.uniform(1.5 * np.pi, 4.5 * np.pi, N) # 卷轴角度 x_manual = t_manual * np.cos(t_manual) z_manual = np.random.uniform(0, 1, N) # 高度(第二个内在维度) y_manual = t_manual * np.sin(t_manual) # 加入少量高斯噪声 x_manual += np.random.normal(0, 0.1, N) y_manual += np.random.normal(0, 0.1, N) z_manual += np.random.normal(0, 0.05, N) # 可视化手动生成的 Swiss Roll(用 t 值染色) fig = plt.figure(figsize=(8, 6)) ax = fig.add_subplot(111, projection='3d') sc = ax.scatter(x_manual, y_manual, z_manual, c=t_manual, cmap='viridis', s=2) plt.colorbar(sc, label='内在坐标 t(卷轴角度)') ax.set_title('Swiss Roll 流形(选项B)') plt.tight_layout() plt.show() # 后续使用 sklearn 版本(更标准) data = data_swiss # 三维坐标,shape=(N, 3) intrinsic_t = t_swiss # 内在坐标 t,用于染色
选项 B 有一个内在维度为 2(t 和 z),嵌入在三维空间里。
你的第一个问题(在写代码之前回答): 这个数据的"真实内在维度"是多少?如果你用 PCA 做降维,你认为保留前几个主成分能保留多少方差?把你的预测写下来,等一会儿和实际结果比较。
第二步:实现一个最小自动编码器
结构定义:
import numpy as np import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, TensorDataset # ── 自动编码器架构定义 ────────────────────────────────────────── class Autoencoder(nn.Module): def __init__(self, bottleneck_dim): super().__init__() # 编码器:3 → 16 → d(瓶颈维度) self.encoder = nn.Sequential( nn.Linear(3, 16), # 输入 3 维(嵌入数据点) nn.ReLU(), # 非线性激活 nn.Linear(16, bottleneck_dim) # 输出 d 维潜在编码 z ) # 解码器:d → 16 → 3(重建原始坐标) self.decoder = nn.Sequential( nn.Linear(bottleneck_dim, 16), nn.ReLU(), nn.Linear(16, 3) # 输出 3 维重建 ) def forward(self, x): z = self.encoder(x) # 编码 x_hat = self.decoder(z) # 解码 return x_hat, z # ── 训练函数 ──────────────────────────────────────────────────── def train_autoencoder(data_tensor, bottleneck_dim, n_epochs=300, lr=1e-3): """ 训练自动编码器直到重建误差收敛。 返回训练好的模型。 """ dataset = TensorDataset(data_tensor) loader = DataLoader(dataset, batch_size=256, shuffle=True) model = Autoencoder(bottleneck_dim) optimizer = optim.Adam(model.parameters(), lr=lr) loss_fn = nn.MSELoss() # 损失函数:均方误差(重建误差) for epoch in range(n_epochs): for (batch,) in loader: optimizer.zero_grad() x_hat, _ = model(batch) loss = loss_fn(x_hat, batch) # 重建误差 loss.backward() optimizer.step() return model # ── 示例:使用 Swiss Roll 数据,先设瓶颈维度 d=2 ─────────────── # (假设 data 已在上一步生成,shape=(N, 3)) data_tensor = torch.tensor(data, dtype=torch.float32) # 转为 PyTorch 张量 # 训练瓶颈维度 d=2 的自动编码器 model_d2 = train_autoencoder(data_tensor, bottleneck_dim=2) print("d=2 自动编码器训练完成")
训练直到重建误差收敛。不需要调超参数,默认设置就行。
第三步:系统地改变瓶颈维度,记录账单
用 d = 1, 2, 3, 4, 5 分别训练,对每个 d,记录:
import matplotlib.pyplot as plt import torch import torch.nn as nn # 将数据切分为训练集和测试集(80% / 20%) N = len(data_tensor) split = int(0.8 * N) train_data = data_tensor[:split] test_data = data_tensor[split:] results = {} # 存储每个瓶颈维度的结果 for d in [1, 2, 3, 4, 5]: # 1. 训练自动编码器 model = train_autoencoder(train_data, bottleneck_dim=d, n_epochs=300) model.eval() with torch.no_grad(): # 2. 计算训练集的平均重建误差(MSE) train_hat, train_z = model(train_data) train_mse = nn.MSELoss()(train_hat, train_data).item() # 3. 计算测试集的平均重建误差 test_hat, test_z = model(test_data) test_mse = nn.MSELoss()(test_hat, test_data).item() results[d] = {'train_mse': train_mse, 'test_mse': test_mse, 'train_z': train_z.numpy(), 'model': model} # 4. 可视化潜在空间(用内在坐标 t 值染色) train_t = intrinsic_t[:split] # 对应训练集的内在坐标 if d == 1: # d=1:潜在空间是一条线,画一维散点 fig, ax = plt.subplots(figsize=(8, 2)) sc = ax.scatter(train_z.numpy()[:, 0], np.zeros(len(train_z)), c=train_t, cmap='viridis', s=5) plt.colorbar(sc, label='内在坐标 t') ax.set_title(f'd={d} 潜在空间(一维)') elif d == 2: # d=2:直接画二维散点图 fig, ax = plt.subplots(figsize=(6, 5)) sc = ax.scatter(train_z.numpy()[:, 0], train_z.numpy()[:, 1], c=train_t, cmap='viridis', s=5) plt.colorbar(sc, label='内在坐标 t') ax.set_title(f'd={d} 潜在空间(二维)') plt.tight_layout() plt.show() # 5. 从潜在空间随机采样 20 个点,解码后画在三维空间里 with torch.no_grad(): # 在潜在空间均匀采样(用训练集潜在编码的范围) z_min = train_z.min(dim=0).values z_max = train_z.max(dim=0).values z_samples = torch.rand(20, d) * (z_max - z_min) + z_min decoded_samples = model.decoder(z_samples).numpy() fig = plt.figure(figsize=(7, 5)) ax = fig.add_subplot(111, projection='3d') ax.scatter(data[:split, 0], data[:split, 1], data[:split, 2], c='lightblue', s=1, alpha=0.3, label='训练数据') ax.scatter(decoded_samples[:, 0], decoded_samples[:, 1], decoded_samples[:, 2], c='red', s=50, zorder=5, label='随机解码点') ax.set_title(f'd={d} 随机解码(随机采样潜在点)') ax.legend() plt.tight_layout() plt.show() print(f"d={d}: 训练MSE={train_mse:.4f}, 测试MSE={test_mse:.4f}") print("\n各瓶颈维度对比:") for d, r in results.items(): print(f" d={d}: 训练MSE={r['train_mse']:.4f}, 测试MSE={r['test_mse']:.4f}")
你的第二个问题: 当 d=1 时,编码器把二维流形压缩到了一维。它保留了什么?丢失了什么?潜在空间里点的排列,是否保留了原始流形的拓扑结构(比如圆的环形关系)?
你的第三个问题(核心问题): 当 d=2 时,如果用原始的内在坐标(t 和 φ,或 t 和 z)给潜在空间的点染色,颜色是否是连续渐变的?如果是,说明什么?如果不是,又说明什么?
第四步:找到分布外点的行为
生成一批不在你的流形上的点——比如随机的三维高斯噪声点。
把这批点输入你的自动编码器:
import torch import torch.nn as nn import numpy as np import matplotlib.pyplot as plt # 使用 d=2 的模型做分布外测试 model = results[2]['model'] model.eval() # 分布外数据:从标准三维高斯分布采样 100 个点 # 注意:这些点分散在整个三维空间,不限于流形附近 ood_data = torch.randn(100, 3) # 标准正态,均值 0,方差 1 with torch.no_grad(): # 经过自动编码器重建(编码 → 解码) ood_reconstructed, ood_z = model(ood_data) # 计算各类数据的重建误差 loss_fn = nn.MSELoss(reduction='none') # 每个样本单独计算误差 with torch.no_grad(): train_hat, _ = model(train_data) # 每个训练样本的 MSE(对三个维度取平均) train_errors = loss_fn(train_hat, train_data).mean(dim=1).numpy() # 每个 OOD 样本的 MSE ood_errors = loss_fn(ood_reconstructed, ood_data).mean(dim=1).numpy() # 对比重建误差 print(f"训练集平均重建误差:{train_errors.mean():.4f} ± {train_errors.std():.4f}") print(f"分布外点平均重建误差:{ood_errors.mean():.4f} ± {ood_errors.std():.4f}") # 可视化:把分布外点的重建结果画在三维空间里 # 观察它们落在哪里(是否被"拉到"流形附近) fig = plt.figure(figsize=(10, 5)) # 左图:原始分布外点 ax1 = fig.add_subplot(121, projection='3d') ax1.scatter(data[:500, 0], data[:500, 1], data[:500, 2], c='lightblue', s=2, alpha=0.3, label='训练流形') ax1.scatter(ood_data[:, 0], ood_data[:, 1], ood_data[:, 2], c='red', s=30, label='OOD 原始点') ax1.set_title('OOD 原始点(散布在三维空间)') ax1.legend(fontsize=8) # 右图:OOD 点经自动编码器重建后的位置 ax2 = fig.add_subplot(122, projection='3d') ax2.scatter(data[:500, 0], data[:500, 1], data[:500, 2], c='lightblue', s=2, alpha=0.3, label='训练流形') ax2.scatter(ood_reconstructed[:, 0].numpy(), ood_reconstructed[:, 1].numpy(), ood_reconstructed[:, 2].numpy(), c='orange', s=30, label='OOD 重建点') ax2.set_title('OOD 点重建后——被"拉到"流形附近') ax2.legend(fontsize=8) plt.tight_layout() plt.show()
你的第四个问题: 分布外点经过自动编码器之后,被"拉到"了哪里?它们的重建结果是随机的,还是系统性地落在了训练流形的某个区域?
这就是本章第四节说的:「网络没有一个’这个点不在我的流形上’的警报。它只能把这个点硬拉到最近的流形区域。」你刚刚亲手看到了这个过程。
第五步:估算你的流形的内在维度
回到第一步,现在做一个数据驱动的内在维度估计:
import numpy as np import matplotlib.pyplot as plt from sklearn.decomposition import PCA # 对训练数据做 PCA(使用 numpy 数组,非张量) train_np = data[:split] # shape=(N_train, 3) pca = PCA() # 不限制主成分数,计算全部 pca.fit(train_np) # 每个主成分解释的方差比例 explained_ratio = pca.explained_variance_ratio_ # 累计解释方差曲线 cumulative_ratio = np.cumsum(explained_ratio) # 画累计方差曲线 fig, axes = plt.subplots(1, 2, figsize=(12, 5)) # 左图:各主成分单独解释方差 axes[0].bar(range(1, len(explained_ratio) + 1), explained_ratio, color='steelblue') axes[0].set_xlabel('主成分编号') axes[0].set_ylabel('解释方差比例') axes[0].set_title('各主成分解释方差') # 右图:累计解释方差曲线,找"肘部" axes[1].plot(range(1, len(cumulative_ratio) + 1), cumulative_ratio, marker='o', color='tomato') axes[1].axhline(y=0.95, color='gray', linestyle='--', label='95% 阈值') axes[1].set_xlabel('主成分数量') axes[1].set_ylabel('累计解释方差比') axes[1].set_title('累计方差曲线(找肘部)') axes[1].legend() plt.tight_layout() plt.show() # 找到累计解释方差超过 95% 时需要几个主成分 n_components_95 = np.searchsorted(cumulative_ratio, 0.95) + 1 print(f"累计解释方差 ≥ 95% 所需主成分数:{n_components_95}") print(f"各主成分解释方差:{explained_ratio.round(4)}") print(f"累计解释方差:{cumulative_ratio.round(4)}") # 与自动编码器结果对比 print(f"\nPCA 估计的内在维度:{n_components_95}") print("自动编码器各瓶颈维度的测试MSE:") for d, r in results.items(): print(f" d={d}: 测试MSE={r['test_mse']:.4f}") print("(MSE 突然大幅上升的拐点对应自动编码器估计的内在维度)")
把这个数字和你在第一步写下的预测比较。
你的第五个问题: 你的 PCA 估计的内在维度,和你用自动编码器得到的"最小无损瓶颈维度",是否一致?如果有差异,你认为原因是什么——PCA 的线性假设,还是自动编码器的非线性?
检验标准
做完这五步,你应该能回答以下三个问题,而且是用你自己的实验数据来回答,不是用这章的文字:
-
压缩低于流形的内在维度,代价是什么?代价出现在哪里?
-
分布外的点,在经过自动编码器之后,是如何被"幻觉式处理"的?
-
「训练数据密集的地方,泛化好;稀疏的地方,泛化差」——你的实验里,稀疏区域对应流形的哪个部分?重建误差在那里是否更高?
如果你只做了一件事,做第四步。那是最短、但最能让你直觉化理解「幻觉」是怎么发生的实验。
小结:从流形到知识结构——前四章的深层联系
在结束前四章之际,让我们回顾一下我们走过的路,以及第1章和第2章新增内容的深层联系。
三个层次的推理系统
前四章实际上描述了三个不同层次的推理系统,它们共享一个元模式:
-
物理层(第1章新增):生命系统作为开放系统
- 通过能量流实现局部熵减
- 以环境熵增为代价维持有序
- 耗散结构:远离平衡态的自组织
-
符号层(第2章新增):知识系统作为符号结构
- 通过逻辑规则实现精确推理
- 以构建成本为代价获得可解释性
- 知识图谱:符号主义的规模化实现
-
统计层(第3-4章):学习系统作为统计模型
- 通过数据流学习模式识别
- 以计算复杂度为代价获得泛化能力
- 流形假设:高维数据的低维结构
统一视角:结构、代价、流动
这三个层次共享一个统一框架:
| 维度 | 物理层(生命) | 符号层(知识) | 统计层(学习) |
|---|---|---|---|
| 核心机制 | 能量流动 | 逻辑推理 | 模式识别 |
| 有序形式 | 物理结构有序 | 符号结构有序 | 表示空间有序 |
| 维持代价 | 环境熵增 | 构建成本 | 计算复杂度 |
| 外部输入 | 能量/物质 | 知识/规则 | 数据/样本 |
| 结构假设 | 耗散结构 | 封闭世界 | 流形假设 |
从离散到连续:表示的演进
前四章也展示了知识表示的演进轨迹:
- 离散符号(第2章):If-Then规则、知识图谱三元组
- 连续向量(第3章):词嵌入、语义空间
- 低维流形(第4章):内在维度、数据的内在结构
关键洞察:知识图谱是离散符号流形,词向量是连续语义流形。两者都在尝试捕捉世界的结构,只是用不同的数学语言。
元问题:推理的多层次实现
这引向一个元问题:推理是什么?
- 物理答案:推理是生命对抗熵增的认知策略
- 符号答案:推理是符号系统遵循逻辑规则的推导
- 统计答案:推理是统计模型在流形上的模式匹配
这三个答案都对,但都不完整。真正的推理可能是三者的协同:
- 物理层提供存在基础(为什么需要推理)
- 符号层提供精确框架(如何形式化推理)
- 统计层提供实现机制(如何计算推理)
思考题:边界在哪里?
每个层次都有自己的边界:
- 物理层:热力学极限(Landauer原理)
- 符号层:知识边界(封闭世界假设)
- 统计层:泛化边界(流形假设)
最终问题:当AI系统"推理"时,它在哪个层次上工作?还是说,真正的智能需要跨越这些层次的整合?
延伸阅读
-
Tishby, N. & Schwartz-Ziv, M. (2017). Opening the Black Box of Deep Neural Networks via Information — 信息瓶颈理论的深度学习版本,提出训练的两阶段假说
→ [arXiv:1703.00810] -
Saxe, A. et al. (2018). On the Information Bottleneck Theory of Deep Learning — 对 Tishby 信息瓶颈理论的批评与修正,表明压缩阶段依赖激活函数选择
→ [arXiv:1812.09881] -
Fefferman, C., Mitter, S. & Narayanan, H. (2016). Testing the Manifold Hypothesis — 流形假设的数学检验,何时流形假设成立、何时不成立
→ [arXiv:1204.1423] -
Bengio, Y., Courville, A. & Vincent, P. (2013). Representation Learning: A Review and New Perspectives — 表示学习综述,包含流形学习与深度表示的关系
→ [arXiv:1206.5538] -
Bellman, R. (1957). Dynamic Programming — 维度诅咒的原始来源,Bellman 在优化背景下命名了这个现象
-
[Zixi Li, 2026b] Collins — 随机化优化器,O(1) 状态压缩,安全压缩比 c_{\text{opt}} \approx 34 的信息论证明