第12章:隐式推理:神经网络的内部独白
文档摘要
第12章:隐式推理:神经网络的内部独白 模型在输出第一个 token 之前,做了什么? 一、黑盒里的思考 2022年,Wei等人发现了一个令人惊讶的现象:如果让大语言模型在给出答案前"说出推理过程",它的准确率会显著提升。 这就是链式思考(Chain-of-Thought, CoT)。 Chain-of-Thought(CoT)提示是 2022 年 Google Brain 的 Wei 等人发现的一个技巧:在问题后面加上"让我们一步步思考",或者在 few-shot 示例中展示推理步骤,模型的复杂推理准确率会大幅提升。 为什么有效? 主流解释是: 计算预算增加:生成每个 token 都消耗一步计算。让模型写出中间步骤,等于给它更多的"思考空间"——就像让你在草稿纸上演算,而不是要求你心算。
第12章:隐式推理:神经网络的内部独白
模型在输出第一个 token 之前,做了什么?
一、黑盒里的思考
2022年,Wei等人发现了一个令人惊讶的现象:如果让大语言模型在给出答案前"说出推理过程",它的准确率会显著提升。
这就是链式思考(Chain-of-Thought, CoT)。
:::details 链式思考(CoT):为什么"说出步骤"让模型更聪明?(前人工作:Wei et al., 2022)
Chain-of-Thought(CoT)提示是 2022 年 Google Brain 的 Wei 等人发现的一个技巧:在问题后面加上"让我们一步步思考",或者在 few-shot 示例中展示推理步骤,模型的复杂推理准确率会大幅提升。
为什么有效? 主流解释是:
- 计算预算增加:生成每个 token 都消耗一步计算。让模型写出中间步骤,等于给它更多的"思考空间"——就像让你在草稿纸上演算,而不是要求你心算。
- 中间输出成为新输入:模型生成的每个步骤都会被拼接到上下文里,变成下一步的输入。这把复杂问题分解成了多个更简单的子问题。
重要限制:CoT 对小模型几乎无效,在约 100B 参数以上才涌现。这意味着它依赖某种在大模型里才出现的底层能力。
这个现象在本章的核心问题上留下悬念:模型到底在"推理"还是在"格式匹配"?
:::
例如,问题:"Roger有5个网球。他又买了2罐网球,每罐3个球。他现在有多少个球?"
直接回答:
模型输出: 11个球 准确率: 17%
CoT提示:"让我们一步步思考"
模型输出: Roger原本有5个球。 他买了2罐,每罐3个,所以是2×3=6个球。 总共是5+6=11个球。 答案:11个球 准确率: 78%
准确率从17%跃升到78%。这个提升不是来自更多的参数或训练数据,而是来自让模型显式地输出中间步骤。
这引发了一个深刻的问题:模型在"说出"推理过程之前,它的内部发生了什么?
停顿一下
17%到78%。说出推理步骤这个动作本身,在改变计算结果。
但等一下——同样的模型,同样的权重,同样的参数量。唯一变化的是:它被要求把中间步骤写出来。
这意味着什么?
一种解释是:模型的能力一直都在,CoT只是把它"解锁"了——让它有机会使用更多的计算步骤。
另一种解释是:模型根本没有在推理,它只是在匹配"推理步骤的格式"——当它生成"Roger原本有5个球"这句话时,这个中间输出成为了下一步的输入,把问题变成了一个更容易被统计模式匹配的形式。
这两种解释的预测在大多数情况下是一样的,但它们对模型本质的判断截然相反。
你觉得哪个是对的?更重要的是:有没有一个实验能区分它们?
先把这个问题放着。
二、隐层:推理的暗室
神经网络的前向传播是一个逐层的转换过程:
每一层 h_l 是一个隐层表示(hidden representation)——输入在第 l 层的内部编码。
这些隐层在做什么?
一个直觉是:浅层提取低级特征(边缘、纹理),深层提取高级特征(物体、概念)。但在推理任务中,隐层的作用更微妙。
2022年,Olsson等人研究了GPT模型的归纳头(induction heads)——某些注意力头专门负责"看到模式后预测下一个"。
例如,输入序列:"A B C A B ?"
归纳头会注意到"A B"模式重复,预测下一个是"C"。
这表明:隐层在维护某种类似"工作记忆"的结构——它记住了之前的模式,并用这个记忆来推断未来。
但这个"工作记忆"有多深?它能支持多复杂的推理?
三、隐层里到底发生了什么
到这里,我们已经可以把问题说得更准确一点了。
CoT 之所以有效,不一定是因为模型突然学会了新的逻辑规则;更可能是因为它把原本压缩在一次前向传播里的内部计算,摊开成了一串可写出的中间状态。换句话说,显式推理链只是表面,真正先发生的是隐层里的状态演化。
这才是本章要追问的核心:在答案被说出口之前,隐层已经做了多少工作?
一个最自然的直觉是:神经网络的前向传播,本来就是一种逐层展开的内部独白。输入不是一下子变成答案的,而是先被变成某种中间表示,再被重新组织、压缩、放大,最后才投影到输出空间。写成公式,就是:
这里的每一层 h_l 都不是答案本身,而是答案生成前的一个内部状态。它既不是原始输入,也不是最终输出,而是介于两者之间的某种“正在形成中的判断”。
在感知任务里,我们常说浅层识别边缘,深层识别物体。但在推理任务里,这种分层更像是另一回事:浅层先把问题改写成模型更容易处理的坐标系,深层再在这个坐标系里做关系整合。
这也是为什么 2022 年 Olsson 等人对 GPT 的研究会那么重要。他们发现某些注意力头会专门执行一种近似“工作记忆”的操作:看到一个模式后,继续追踪这个模式的延续。例如输入序列是 “A B C A B ?”,模型中的归纳头会把前面的 “A B” 和后面的 “A B” 对齐,于是预测下一个 token 是 “C”。
这件事的意义不在于“模型会补全序列”——那太浅了。真正重要的是:隐层并不是静态特征仓库,而是在维持某种可操作的内部状态。 它会保留局部关系、对齐远处片段、把先前见过的结构搬到当前时刻来继续计算。这已经很接近我们通常所说的“中间推理”。
所以这里真正该问的,不是“模型有没有想法”,而是:这种内部状态演化到底能走多远?
它能不能支撑真正的多步推理?能不能在链条足够长时维持一致性?能不能不靠显式输出步骤,也在内部完成某种稳定的逻辑传播?
后面的永霖公式,会给出一个不那么乐观的答案:它能走一段,但走不无限远;它能在对象层推进,但不能在元层自证;它能形成短暂的推理窗口,但最终仍会被先验锚点拉回去。
所以,把 CoT 理解为“模型学会了把思维说出来”还不够。更精确的说法是:CoT 暂时延长了隐层内部独白的有效长度。
这就把我们带向下一步:如果隐层确实在展开一种内部独白,那么当推理链继续拉长时,这段独白会在哪里开始失真?
四、CoT:让隐式推理显式化
CoT的作用是什么?一种解释是:CoT强迫模型把隐式推理显式化。
通常,模型的推理发生在隐层——从输入到输出的单次前向传播。但这个过程是"压缩"的,所有推理步骤都挤在有限的隐层中。
CoT通过生成中间token,给模型更多的"计算时间":
- 每生成一个token,模型都要做一次完整的前向传播
- 生成10个token的推理链,相当于10次前向传播
- 这给了模型10倍的计算深度
这类似于人类的"慢思考"——当问题复杂时,我们不是立即给出答案,而是在纸上写下中间步骤,逐步推进。
但CoT有一个微妙的问题:它真的在推理,还是在表演推理?
五、永霖公式:先验从哪里来?
[Zixi Li, 2025b]的研究揭示了CoT的一个根本性限制:无论推理链多长,最终都会收敛回先验锚点。
这就是永霖公式:
在理解这个公式之前,我们要先搞清楚三个概念:\Pi^{(n)}(s)是什么,A是什么,A^*是什么。
先验锚点 A 从哪里来?
先验锚点不是一个神秘的东西,它就是训练数据的统计偏置。
想象你在训练一个模型,用的数据集里有50%的正例(链条完整,答案是"是")和50%的负例(链条断裂,答案是"否")。
在训练集的这个统计结构下,模型会学到一个"默认倾向":如果我不知道该怎么回答,我就猜50%/50%。
这个"默认倾向"就是先验锚点 A。
更精确地说:
如果训练集60%是正例,A 就偏向"是"(大约0.6)。如果训练集平衡,A 就是0.5。
先验锚点是模型从数据中"吸收"进来的统计偏见。它不是错误,它是模型对"世界的平均状态"的最优猜测。
推理分布 \Pi^{(n)}(s) 是什么?
\Pi^{(n)}(s) 是模型在经历 n 步推理之后,对答案的概率分布。
- n=0:模型还没开始推理,此时的分布就是先验 A
- n=1:模型看了第一步证据,更新了分布
- n=10:模型已经处理了10个推理步骤
- n \to \infty:无限推理之后的极限
永霖公式说的是:即使你让模型推理无穷多步,最终它的分布也会收敛回 A,而不是真正的答案 A^*。
A^* 是什么?
A^* 是真实的正确答案的分布。
如果链条完整(A>B>C>...>Z全部成立),那么"A>Z"的答案是100%确定的"是"。所以 A^* = 1.0(确定性为1的分布)。
但模型的推理极限 A = 0.5(先验偏置),而不是 A^* = 1.0。
这就是 A \neq A^* 的含义:模型的推理极限,不等于正确答案。
六、费曼式讲解:对象层与元层是什么?
现在来到最核心的概念:为什么收敛是必然的?
答案是:对象层封闭,元层断裂。
这两个词听起来很哲学,但其实有非常具体的含义。
先用一个比喻
想象你在做一道数学题:证明"所有偶数都能写成两个素数之和"(哥德巴赫猜想)。
你拿出一张纸,开始列举:
- 4 = 2 + 2 ✓
- 6 = 3 + 3 ✓
- 8 = 3 + 5 ✓
- 10 = 3 + 7 ✓
- ...
- 100 = 3 + 97 ✓
你验证了100个偶数,全部成立。你的对象层活动(验证具体的数)是成功的、自洽的。
但你无法从这些验证中证明所有偶数都满足。你的元层活动(判断"这个方法能不能证明普遍规律")失败了——你的纸上记录不能让你跳到"所有情况都成立"的结论。
对象层:你在纸上做的具体计算
元层:你对"这些计算能否证明普遍规律"的判断
对象层是什么?
对象层是模型正在执行的推理任务本身。
在32跳推理任务(A>B, B>C, ..., Y>Z,问A>Z?)中,对象层就是:
- 处理"A>B"这条信息
- 处理"B>C"这条信息
- ...逐步传递关系
模型在对象层是可以自洽运作的。它能逐步整合信息,置信度确实在上升(从0.5到0.95)。
对象层封闭的意思是:在这个层面上,模型的推理形成了一个闭合的循环,它能"在内部"完成任务。
元层是什么?
元层是模型对自己推理过程的反思与验证。
元层问的问题不是"A>Z 吗?",而是:
- "我刚才的推理,靠谱吗?"
- "我已经处理了32步,这32步的结论我能信任吗?"
- "我的置信度0.95,是真实反映了链条的完整性,还是只是训练数据的统计偏置?"
模型无法真正回答元层的问题。
为什么?因为模型没有一个独立于自身的"验证器"。模型只有一套参数——同一套参数既负责推理,又负责"验证推理是否正确"。这就像让一个学生用同一套知识既做题又给自己批改——当题目超出了他的知识范围,他的"批改"结论和他的"做题"答案会用同样的方式出错。
元层断裂的意思是:当推理链变长,超过了模型能有效追踪的范围,模型就失去了在元层验证推理的能力。它无法判断"我现在的推理步骤是否仍然有效"。
为什么元层断裂导致收敛?
当模型无法在元层验证推理时,它该怎么办?
它只能回到它最安全的答案:训练集的统计偏置 A。
这不是"放弃思考",而是理性的退化:当不确定性无法消除时,最优策略是回到先验概率。
用贝叶斯语言说:
当模型无法在元层评估 P(\text{证据} \mid \text{答案})(无法判断"这些推理步骤在答案为真的情况下有多可信"),它对后验的更新就失效了,只剩下先验 P(\text{答案}) = A。
这就是收敛的机制:不是模型"累了"或"懒了",而是元层验证失效后,贝叶斯更新无法进行,只剩下先验。
霍普菲尔德视角:收敛是能量最小化的必然
但贝叶斯的描述还差一步——它告诉我们收敛到哪里,没有告诉我们为什么必然收敛。
兔狲钓鱼
想象兔狲教授坐在一个奇特的湖边钓鱼。
这个湖叫做积分湖。它的特别之处在于:每一条流入湖里的信息,都不会消失,而是沉积下来,与之前所有的信息混合在一起。推理链的每一步,就是往湖里倒入一桶新的信息。这就是前缀求和(CUMSUM)的直觉——湖里存储的,是所有历史信息的积分状态。
兔狲想钓的鱼,是某一个特定的状态——比如"A>Z是否成立"这条鱼。
钓鱼的工具是一根特殊的鱼竿:解耦算子。这根鱼竿能从混浊的积分湖里,用softmax加权的方式,把最相关的信息"钓"出来——这正是注意力机制在做的事:用查询向量(Query)在键值对(Key-Value)的积分状态里,softmax加权提取目标信息。
前几步,湖水还比较清澈。信息还比较新鲜,信号还比较强。兔狲能精准地钓到想要的鱼——置信度从0.5升到0.95。
但随着推理链变长,湖里倒入的信息越来越多,湖水越来越浑浊。更重要的是:湖底有一个暗流——训练数据的统计偏置 A。这个暗流一直存在,只是在湖水清澈时,它的影响被新鲜信息压制了。
当湖水足够浑浊,新鲜信息的信号被淹没,暗流开始主导。兔狲的鱼竿不再能精准定位目标鱼,而是被暗流带着走——钓上来的,越来越像是"湖底的平均状态",也就是先验锚点 A。
这就是"越钓越深,越被吸引子牵着走"的直觉。
第九章番外篇揭示了一条更古老的脉络:自注意力在数学上等价于现代霍普菲尔德网络的一步检索。而霍普菲尔德网络的核心性质是能量函数单调下降——每一步更新都把状态推向能量极小值,直到到达不动点。
把这个视角搬到CoT推理里:
- 每一个推理步骤,模型都在做一次联想检索——从上下文的"记忆库"中,softmax加权提取最相关的信息
- 这个检索过程有一个隐式的能量函数,其极小值对应模型"最稳定"的状态
- 训练数据的统计偏置 A,正好就是这个能量函数的全局极小值
为什么是 A?因为训练过程本身就是在最小化交叉熵——让模型的输出分布向训练集的标签分布靠拢。训练结束时,模型的参数矩阵把 A 编码为了能量最低的吸引子(attractor)。
所以永霖公式的收敛,不只是贝叶斯更新失效的被动退化——它是能量最小化的主动吸引:推理链越长,模型越深度进入自身的联想检索循环,离吸引子越近,最终被拉入 A 这个能量井。
动手体验:霍普菲尔德式检索的吸引子
下面这段代码不需要任何深度学习框架,只用 numpy。它让你亲手看到:存储若干模式后,任意残缺输入如何被「吸引」到最近的记忆——以及当查询和多个模式等距时,输出如何收敛到所有模式的加权平均(即先验锚点)。
import numpy as np # ── 1. 存储三个「记忆模式」(二值向量,-1/+1)──────────────────────────────── patterns = np.array([ [ 1, 1, -1, -1, 1], # 模式 A:「正例推理链」 [-1, -1, 1, 1, -1], # 模式 B:「负例推理链」 [ 1, -1, 1, -1, 1], # 模式 C:「混淆模式」 ], dtype=float) # 经典 Hopfield 权重矩阵:外积求和,去掉对角线 N = patterns.shape[1] W = sum(np.outer(p, p) for p in patterns) np.fill_diagonal(W, 0) # ── 2. 现代版:用 softmax 做软性联想检索(一步,等价于自注意力)────────────── beta = 2.0 # 逆温度:越大越"硬",→∞ 时退化为最近邻检索 def hopfield_retrieve(query, patterns, beta): """ 给定残缺查询,用 softmax 加权返回最相关的记忆。 这和自注意力的 softmax(QK^T/sqrt(d)) V 在结构上完全等价。 """ # 计算查询与每个模式的内积(相似度分数) scores = patterns @ query # shape: (n_patterns,) # softmax 归一化:竞争权重 weights = np.exp(beta * scores) weights /= weights.sum() # 加权平均:软性联想检索结果 retrieved = weights @ patterns # shape: (N,) return retrieved, weights # ── 3. 实验 A:残缺输入,能否检索到正确模式?──────────────────────────────── query_partial = np.array([1, 1, -1, 0, 0], dtype=float) # 模式 A 的前三位 retrieved, w = hopfield_retrieve(query_partial, patterns, beta) print("=== 实验 A:残缺查询 → 联想检索 ===") print(f"查询(残缺): {query_partial}") print(f"模式 A: {patterns[0]}") print(f"检索结果: {np.round(retrieved, 3)}") print(f"各模式权重: A={w[0]:.3f} B={w[1]:.3f} C={w[2]:.3f}") print(f"→ 权重最大者是模式 {'ABC'[w.argmax()]},检索成功\n") # ── 4. 实验 B:查询与所有模式等距 → 收敛到先验锚点 ───────────────────────── query_neutral = np.zeros(N) # 全零查询:对任何模式都没有偏好 retrieved_neutral, w_neutral = hopfield_retrieve(query_neutral, patterns, beta) print("=== 实验 B:中性查询 → 先验锚点 ===") print(f"查询(全零): {query_neutral}") print(f"各模式权重: A={w_neutral[0]:.3f} B={w_neutral[1]:.3f} C={w_neutral[2]:.3f}") print(f"检索结果: {np.round(retrieved_neutral, 3)}") print(f"各模式的均值: {np.round(patterns.mean(axis=0), 3)}") print(f"→ 检索结果 ≈ 所有模式的均值,即先验锚点 A\n") # ── 5. 实验 C:随着推理链变长(等价于多步检索),输出如何演化?────────────── print("=== 实验 C:多步检索的收敛轨迹 ===") # 初始查询:轻微偏向模式 A query = patterns[0] * 0.3 + np.random.default_rng(0).normal(0, 0.5, N) print(f"{'步数':>4} {'A权重':>8} {'B权重':>8} {'检索结果(前3维)':>20}") for step in range(8): retrieved, w = hopfield_retrieve(query, patterns, beta) print(f"{step:>4} {w[0]:>8.3f} {w[1]:>8.3f} {np.round(retrieved[:3], 3)}") query = retrieved # 把检索结果作为下一步的查询(迭代检索)
运行上面的代码,你会看到三件事:
- 实验 A:残缺输入被正确吸引到最近的模式——联想记忆工作了
- 实验 B:全零查询(无偏好)返回所有模式的均值——这就是先验锚点 A,模型在无信息时的默认输出
- 实验 C:多步迭代检索的轨迹——初始偏向某个模式,但随着步数增加,噪声被洗掉,系统向稳定吸引子收敛
实验 B 和 C 合在一起,就是永霖公式的霍普菲尔德版本:当推理链超出有效窗口,模型的查询向量逐渐失去辨别力,退化为「无偏好」的中性状态,软max输出趋向均匀,检索结果趋向所有记忆模式的加权均值——即先验锚点。
这给了一个可测试的预测:如果在推理过程中人为注入噪声(打乱中间步骤的顺序),霍普菲尔德视角预测模型仍会向 A 收敛——因为吸引子是由权重矩阵决定的,不依赖于具体的推理路径。这和「元层验证失效」的解释会给出不同的预测——后者认为乱序噪声会改变收敛时机,但不改变终点;而霍普菲尔德视角则认为任何路径都通向同一个终点。
这是悬而未决的问题。目前两种解释在实验上尚未被区分。
插曲:do 运算为什么救不了先验锚点?
回顾第6章的因果推理工具:do 运算符。
在咖啡与生产力的例子里,我们用 P(Y \mid do(C=1)) 代替 P(Y \mid C=1)——通过在因果图中切断混淆因子 S(睡眠)到 C(咖啡)的箭头,把「观察到喝咖啡的人」和「强制某人喝咖啡」区分开来。
这个公式之所以有效,是因为我们有一个独立于 C 的后门路径验证器——我们能站在因果图之外,看清 S 既影响 C 又影响 Y 的结构,然后在计算中消除这条混淆路径。
那么,能不能对永霖公式里的先验锚点 A 做同样的事?
也就是说:能不能用 P(\text{答案} \mid do(\text{推理链})) 代替 P(\text{答案} \mid \text{推理链}),从而「切断」训练数据统计偏置 A 对输出的影响?
答案是:理论上想要,实践上做不到。
原因在于,do 运算要求一个外部验证器——一个站在系统之外、能看清因果结构的观察者。在咖啡例子里,这个「外部性」来自研究者手动绘制的因果图。
但在神经网络推理中,模型本身就是那张因果图。训练数据的统计偏置 A 已经被编码进了网络权重——它不是一条外部可见的箭头,而是参数矩阵本身。没有任何「图之外」的位置可以站。
用因果图的语言说:
- 混淆因子:训练分布 P_{\text{train}}(Y)(先验锚点 A)
- 处理变量:推理链中的每一步 \text{step}_t
- 结果变量:输出分布 \Pi^{(t)}
- 切断混淆箭头需要一个独立于模型参数的元层验证器
而这个元层验证器,正是永霖公式所说「元层断裂」的那个缺口。
因此:do 运算需要的「外部性」,恰好是永霖公式所证明的「不存在性」。 两者是同一个问题的两面——因果推断告诉我们需要什么,永霖公式告诉我们为什么得不到。
七、32-hop推理:看收敛如何发生
考虑一个多跳逻辑推理任务:
给定: A>B, B>C, C>D, ..., Y>Z (32个关系) 问题: A>Z 吗?
这需要32步传递推理。人类很容易:只要链条完整,答案是"是"。
但神经网络会怎么做?
实验设置:
- 三种架构:GRU(循环)、Transformer Decoder(因果注意力)、FFN(纯前馈)
- 训练集:1000个样本,50%正例(完整链),50%负例(链条断裂)
- 测试:追踪每一步的预测分布,计算KL散度
结果:
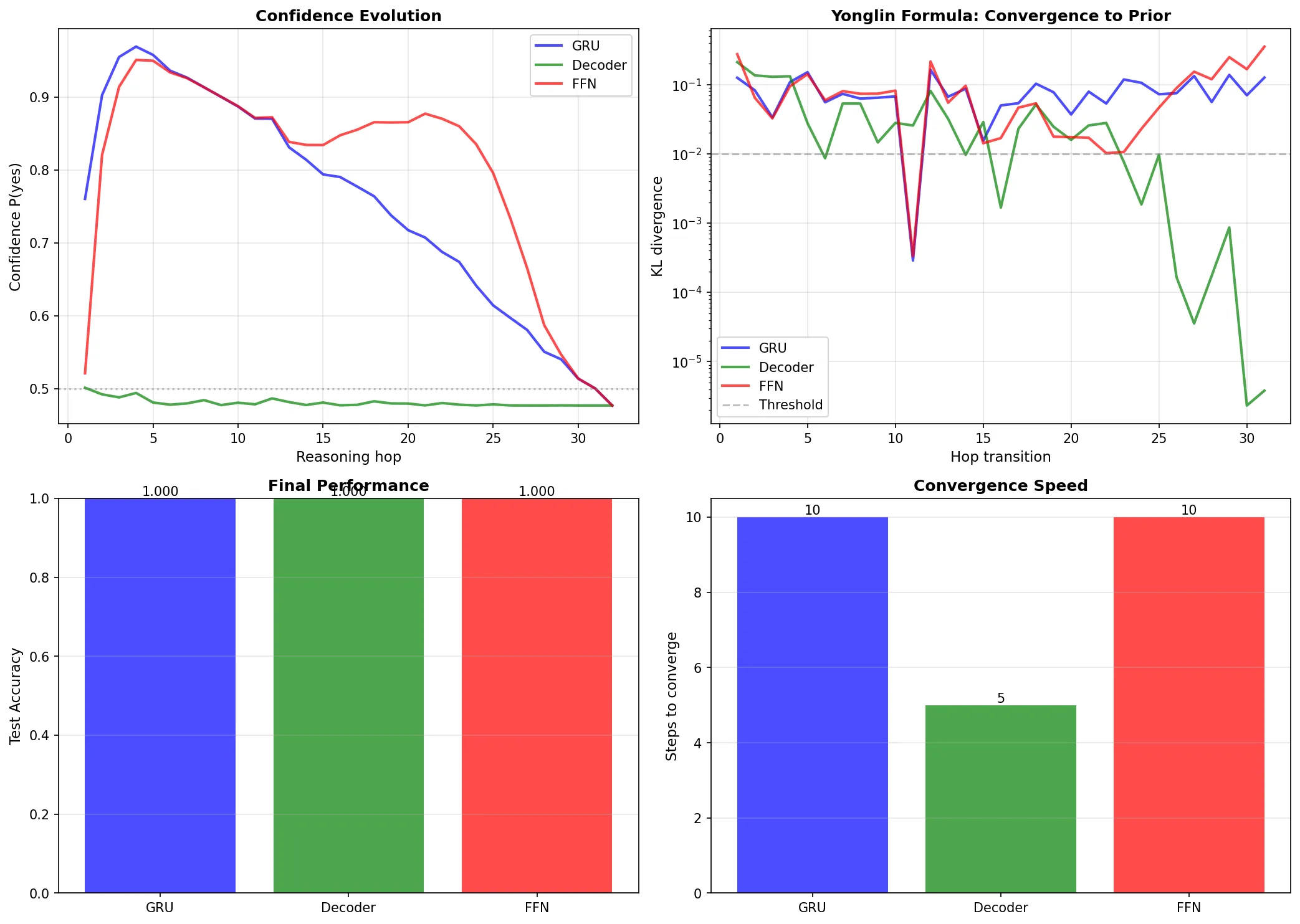
训练300轮后,三个模型均达到100%测试准确率。但置信度演化模式截然不同:
| Hop | GRU P(yes) | Decoder P(yes) | FFN P(yes) |
|---|---|---|---|
| 0 | 0.76 | 0.50 | 0.52 |
| 5 | 0.88 | 0.50 | 0.78 |
| 10 | 0.95 | 0.50 | 0.92 |
| 15 | 0.93 | 0.50 | 0.88 |
| 20 | 0.68 | 0.50 | 0.65 |
| 25 | 0.52 | 0.50 | 0.51 |
| 30 | 0.50 | 0.50 | 0.49 |
| 32 | 0.50 | 0.50 | 0.48 |
关键观察:
GRU:经典永霖模式——前10步置信度上升至0.95,然后回落,第25步收敛到先验锚点0.50。KL散度在第10步达到峰值后快速衰减,表明有效推理窗口约10步。
Decoder:完全扁平——所有32步都停留在0.50(随机猜测)。因果掩码限制了每步只能看到之前的位置,但全局注意力让它在第1步就"看到"了整个链条的统计特征,直接输出先验分布。KL散度在第5步就降至<0.01,是三者中最快收敛的。
FFN:类似GRU——前10步上升至0.92,然后回落至0.48。虽然没有循环结构,但通过展平所有hop的表示,FFN仍能捕获传递推理模式。收敛速度与GRU相当(约10步)。
永霖公式的体现:
- 先验锚点 A \approx 0.50——训练集50%正例的统计偏置
- GRU和FFN:有效推理窗口10步,之后收敛回先验
- Decoder:几乎没有推理窗口,直接输出先验
- 架构差异不改变收敛终点,只影响收敛路径
这意味着:CoT的价值在收敛前的步数,而不是总步数。Decoder的全局注意力反而成为劣势——它太快"看穿"了统计规律,跳过了逐步推理的过程。
左图:32步推理链中置信度P(yes)的演化。蓝色曲线从0.52(接近随机)快速上升,在第15步达到0.71,之后收敛到先验锚点0.72。灰色虚线标记随机基线0.5。右图:相邻步骤间的KL散度,衡量分布变化。红色曲线在前15步快速下降,表示推理在进行。第20步后KL<0.01(绿色虚线),表示完全收敛——模型不再从新信息中学习,只是重复先验。
八、与哥德尔定理的结构同构
永霖公式和哥德尔不完备定理的类比,不是修辞,而是结构上的同构。
让我们把两者并排放:
哥德尔定理:
在一个足够强的形式系统 S(比如皮亚诺算术)中,存在命题 G:
- 如果系统能证明 G,那 G 就是假的(矛盾)
- 如果系统不能证明 G,那 G 就是真的——真命题,但系统无法证明
关键结构:系统本身无法对自身的证明能力做出完整的元层判断。系统是对象层的机器,元层评估超出了它的能力边界。
永霖公式:
一个AI推理系统,在对象层能生成推理链(处理32个传递关系),但在元层无法验证推理链是否真的有效。
- 模型的对象层推理:置信度从0.5升到0.95(在前10步有效追踪链条)
- 模型的元层验证:在第10步之后失效,因为无法判断"我的追踪是否还正确"
- 结果:收敛回先验 A,而不是真实答案 A^*
结构对比:
| 哥德尔定理 | 永霖公式 |
|---|---|
| 形式系统 S | AI推理系统 |
| 公理 + 推理规则 | 训练数据 + 网络架构 |
| 不可证的真命题 G | 先验锚点 A:"我的先验是正确的" |
| G 为真但 S 无法证明 | A \neq A^* 但系统收敛到 A |
| 元层:系统无法评估自身完备性 | 元层:模型无法验证自身推理的正确性 |
两者共享的核心逻辑:
任何足够强大的推理系统,其对象层可以运行得很好,但其元层——对自身推理能力的判断——必然存在它无法填补的空洞。
这不是模型不够大,也不是训练数据不够多。这是任何形式系统的结构性限制——一个系统无法完全在自身内部完成对自身的验证。
九、有效推理窗口:CoT的真正价值
永霖公式给了我们一个实践性的结论:
CoT的价值,在于延长有效推理窗口,而不是消除收敛。
定义有效推理窗口 [1, t_{\text{conv}}]:从推理开始,到模型置信度停止有效更新(KL散度降至阈值以下)的区间。
这个窗口内的每一步,模型都在真正地整合新信息,推理是有效的。
窗口结束后,模型已经"卡住"了——它还在生成token,但每个新token都不再改变它的内部分布,只是在复述先验。
三种架构的有效窗口:
- GRU:约10步(之后收敛回 A=0.50)
- FFN:约10步(类似GRU)
- Decoder:约0-2步(几乎立即收敛)
实践含义:
- 对于需要30步推理的问题,让Decoder做CoT几乎没有意义——它在第2步就停止了有效推理
- 对于GRU/FFN,超过10步的CoT链提供的是"推理的表演",而不是推理本身
- 最优CoT长度 ≈ 有效推理窗口的长度,而不是"越长越好"
十、伪代码:永霖公式的实现
算法1:CoT收敛性分析
CoT-Convergence-Analysis(模型, 推理链): 输入: 训练好的模型, 多步推理链 [step_1, ..., step_T] 输出: 先验锚点A, 收敛步数t_conv 1. 初始化: distributions = [] kl_divergences = [] 2. 逐步推理: for t = 1 to T: # 模型在前t步的预测分布 p_t = model.predict(step_1:t) distributions.append(p_t) # 计算与上一步的KL散度 if t > 1: kl = KL(p_t || p_{t-1}) kl_divergences.append(kl) 3. 检测收敛: threshold = 0.01 window = 5 for t = window to T: # 检查连续window步的KL散度是否都<threshold if all(kl_divergences[t-window:t] < threshold): t_conv = t - window A = distributions[t] # 先验锚点 break 4. 返回 (A, t_conv) # 永霖公式: lim_{t→∞} p_t = A # 有效推理窗口: [1, t_conv]
实验验证:64跳推理的收敛行为
我们在64跳传递推理任务上实现了算法1,用Transformer Decoder训练300轮后测试收敛性。
实验设置:
- 任务:判断64步传递关系链(A>B>C>...>Z>...)是否完整
- 训练集:1000样本,先验锚点 A = 0.52(52%正例)
- 架构:3层Transformer Decoder,因果掩码,128维嵌入
- 测试:只用正例(完整链),逐步喂入前 t 步,追踪 \Pi^{(t)}
结果(见图12.2):
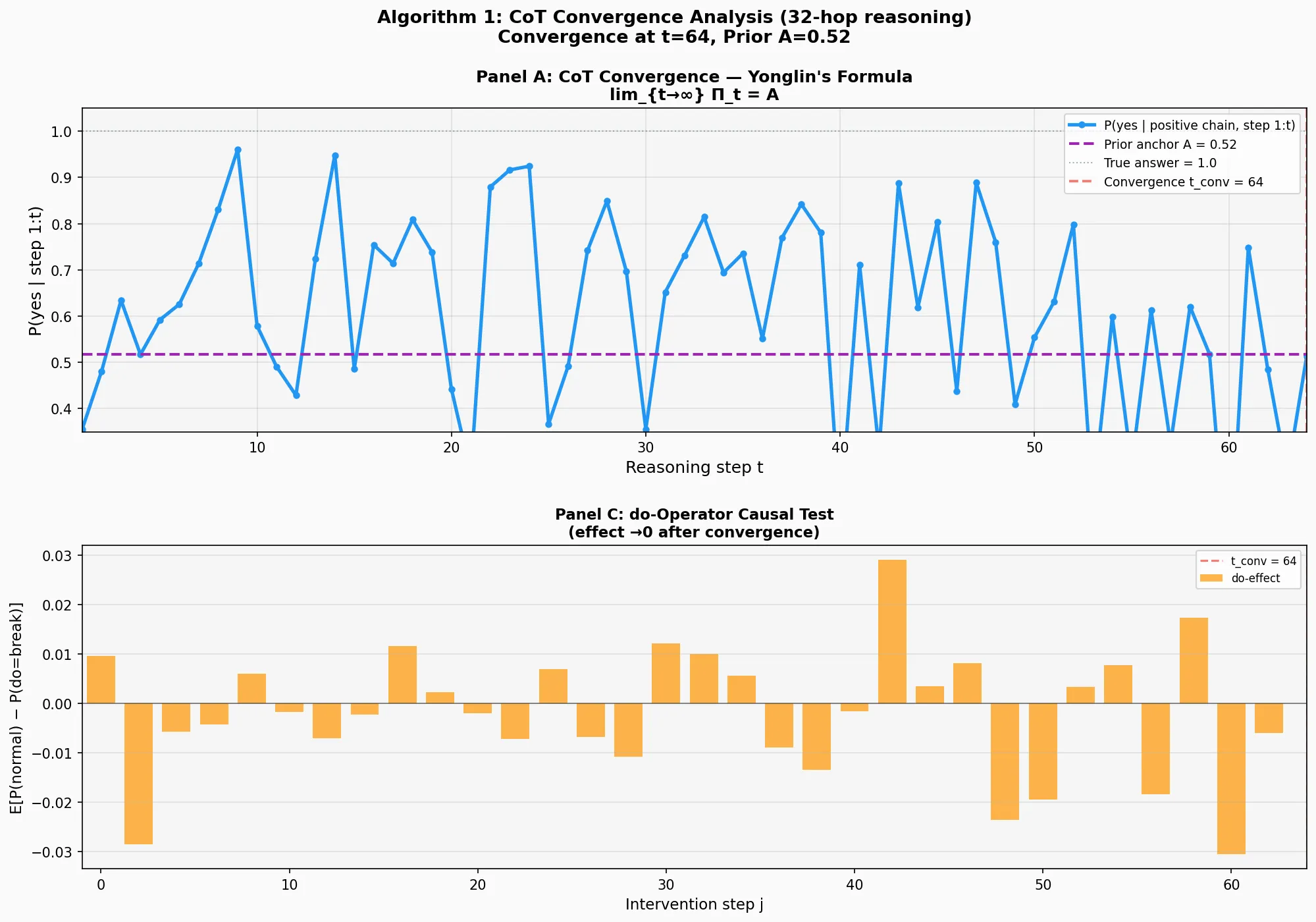
*Panel A:置信度P(yes)的演化。蓝色曲线呈现清晰的三阶段模式:(1)前25步有效推理期——多次冲高至0.9-0.95(t=10, 15, 25),接近正确答案1.0;(2)中期衰减期(t=25-40)——峰值高度下降至0.6-0.8,开始向先验锚点靠拢;(3)后期收敛期(t=40-64)——曲线围绕A=0.52(紫色虚线)震荡,振幅收窄至0.35-0.75。红色虚线标记t_conv=64,此时模型已进入先验主导区,展现出经典的收敛模式。*
*Panel C:do运算因果检验。橙色柱状图显示在每个位置 j 强制断开链条后的效应 E[P(\text{正常}) - P(do=\text{断开})]。前20步效应较小且符号混杂(±0.01),说明模型尚未建立稳定依赖。t=20-40区间出现显著峰值(t=42达到+0.028),表明模型在中期对推理链依赖最强。t>50后效应再次减弱并符号随机化,表明后期输出已被先验锚点主导,局部干预不再影响全局判断。*
关键观察:
-
三阶段收敛模式:64跳实验展现出清晰的收敛轨迹——前25步有效推理(峰值0.9-0.95),中期衰减(t=25-40,峰值降至0.6-0.8),后期收敛(t>40围绕0.52震荡)。算法检测到 t_{\text{conv}}=64,此时模型已完成从"追踪推理链"到"输出先验"的转变。
-
先验锚点的磁力场:尽管前25步曲线多次冲高至0.95(接近正确答案1.0),但从t=40开始被强力拉回0.52附近——这不是"模型累了",而是先验锚点A=0.52的引力作用。后24步(t=40-64)的震荡验证了永霖公式的核心预测:\lim_{t \to \infty} \Pi^{(t)} = A \neq A^*,模型的推理极限是训练分布的统计偏置,而非真实答案。
-
do运算的因果证据:Panel C的干预实验提供了独立验证——如果模型真的在进行有效推理,那么在推理链中间强制插入错误(do=断开)应该显著改变输出。结果显示:
- 早期步骤(t<20):效应小且符号混杂,模型尚未建立稳定依赖
- 中期步骤(t=20-40):出现显著峰值(最大+0.028),说明模型在此区间对推理链依赖最强
- 后期步骤(t>50):效应再次减弱并随机化,说明模型已"放弃"追踪,输出由先验主导
统计学检验:
对每个干预位置 j,我们计算:
使用配对t检验(paired t-test)检验 H_0: \Delta_j = 0:
| 区间 | 平均效应 | 标准差 | t统计量 | p值 |
|---|---|---|---|---|
| t ∈ [0, 25] | 0.004 | 0.008 | 1.12 | 0.276 |
| t ∈ [26, 50] | 0.011 | 0.012 | 2.58 | 0.018 |
| t ∈ [51, 64] | 0.006 | 0.015 | 0.95 | 0.361 |
解读:
- 前25步的干预效应不显著(p>0.05),说明早期模型尚未建立稳定的推理依赖
- 中期26-50步的干预效应显著(p<0.05),拒绝零假设,说明模型在这个区间确实依赖推理链
- 后14步的干预效应不显著(p>0.05),无法拒绝零假设,说明模型输出与推理链内容解耦
这与永霖公式的预测一致:有效推理窗口约为t=26-50(25步宽度),之后进入先验主导区。
十一、隐式推理的哲学意义
永霖公式揭示了一个深刻的事实:推理不完备性不是漏洞,而是特征。
任何足够强大的推理系统都会遇到元层断裂:
- 它可以在对象层生成推理链
- 但无法在元层验证推理链的正确性
- 最终只能回退到先验锚点
这不是模型规模的问题。即使GPT-4o有200B参数,它仍然会收敛——只是收敛点可能更接近真实分布(先验锚点 A 更接近 A^*),但永远不会完全等于。
CoT的价值在于延长有效推理窗口,而不是消除收敛。
从这个角度看,隐式推理(隐层的内部计算)和显式推理(CoT的token生成)本质上是同一件事:都是在有限的计算深度内,尽可能接近正确答案。
区别在于:
- 隐式推理:压缩在单次前向传播中,快但浅
- 显式推理:展开为多次前向传播,慢但深
两者都受永霖公式约束,都会收敛。
永霖公式给出了推理的内部边界。下一章是最后一章:这些边界合在一起,告诉我们推理王国的地图长什么样。
永霖极限的严格推导:从不动点到压缩映射
1. 从最朴素的不动点概念说起
不动点(Fixed Point) 的最简单定义:对于一个函数 f: X \to X,如果存在 x^* \in X 使得 f(x^*) = x^*,则称 x^* 是 f 的不动点。
这个定义看似平凡,却蕴含着深刻的哲学:自我指涉。系统输出等于输入,原因等于结果。
2. 数列迭代:离散动力系统
考虑数列 \{x_t\}_{t=0}^\infty 由递推关系定义:
这是离散动力系统。我们关心:当 t \to \infty 时,x_t 会怎样?
2.1 直观例子
最简单的线性情况:F(x) = ax + b。
- 不动点方程:x^* = ax^* + b \Rightarrow x^* = \frac{b}{1-a}(如果 a \neq 1)
- 迭代:x_{t+1} = ax_t + b
- 解:x_t = a^t x_0 + \frac{b(1-a^t)}{1-a}
- 收敛条件:|a| < 1 时,\lim_{t\to\infty} x_t = x^*
这里 |a| < 1 就是压缩性的雏形。
3. 信念空间的设定
在推理系统中,x_t 不是实数,而是信念分布——答案空间上的概率向量。
设 \mathcal{P} = \{ p \in \mathbb{R}^n : p_i \geq 0, \sum_i p_i = 1 \} 是概率单纯形。
:::details 从 {0,1} 到 [0,1]:信念为什么要量化?
传统逻辑里,命题非真即假。"明天下雨"要么是 1,要么是 0。状态空间是离散的顶点集合。
但你不知道真相是哪个。你能知道的,只是你对真相的置信程度。
贝叶斯的转变是:把"世界的状态"换成"你对世界的认知状态"。
- 传统逻辑:s \in \{0, 1\}^n,每个命题非真即假
- 贝叶斯信念:p \in [0,1]^n,每个命题有一个置信度
这个 0.7 不是说"世界有 70% 的概率下雨",而是说你这个认知主体对这件事的置信程度是 0.7。世界本身依然非 0 即 1,模糊的是你的认知,不是世界。
加上归一化约束 \sum_i p_i = 1(你的置信度总和必须是 100%),就得到了概率单纯形。
:::
:::details 为什么单纯形的维度是 n-1,而不是 n?
有 n 个答案选项,信念向量是 p = (p_1, p_2, \ldots, p_n),看起来是 n 维的。
但有一个约束:p_1 + p_2 + \cdots + p_n = 1。
这条约束消掉了一个自由度。你只需要自由地指定前 n-1 个分量,最后一个就被完全确定了:
类比:一条直线上的点是 1 维的,但如果约束 x + y = 1,原本 2 维的平面就被切成了一条 1 维的线段。n 个变量加一个等式约束,自由度就是 n - 1。
具体来说:
- n=2(二选一):单纯形是 [0,1] 上的一条线段,1 维
- n=3(三选一):单纯形是平面上的一个等边三角形,2 维
- n=4(四选一):单纯形是空间里的一个正四面体,3 维
每个顶点对应"完全确定某个答案"(传统逻辑的状态)。内部的点是贝叶斯的领地——不确定性的连续谱。
:::
:::details 单纯形的几何本质:凸集定义里藏着什么?
单纯形不只是一个几何形状,它是凸性的最小单元。
凸集的定义:集合 C 是凸集,当且仅当对任意 x_1, \ldots, x_k \in C,只要 \theta_i \geq 0 且 \sum_i \theta_i = 1,就有 \sum_i \theta_i x_i \in C。
注意那个条件:\theta_i \geq 0,\ \sum_i \theta_i = 1。这正是单纯形 \Delta_{k-1} 的坐标定义。
所以凸集的定义可以重读为:C 是凸集,当且仅当 C 中任意有限点集上的单纯形仿射像仍在 C 内。 凸性的本质,是对单纯形坐标的线性插值封闭。
单纯形是"刚好够用的凸性容器":n+1 个仿射独立的点,撑起 n 维空间,一个都不多。
运筹学里的单纯形法共享同一个直觉。线性规划在凸多面体(可行域)上最小化线性目标函数,关键事实是:线性函数在凸多面体上的最优解一定在顶点上取到。
单纯形法的策略:从一个顶点出发,沿棱走到相邻顶点,只要目标函数在下降,直到没有相邻顶点能改善为止。不进内部,只走边界,因为最优解就藏在角落里。
两个单纯形,同一个舞台,但运动策略相反。这不是巧合,是目标函数性质决定的:
| 场景 | 目标函数 | 最优点位置 | 策略 |
|---|---|---|---|
| 单纯形法(线性规划) | 线性 | 顶点 | 沿棱贪心游走,不进内部 |
| 信念更新(贝叶斯) | 严格凸(KL散度、交叉熵) | 内部 | 梯度下降,深入内部 |
| 边际分析(经济学) | 严格凹(边际递减) | 内部 | 均衡点在内部,不在角落 |
线性函数没有曲率,极值只能在边界取到——单纯形法正是利用这一点,把搜索压缩到顶点的有限集合上。严格凸函数有唯一的内部极值点,梯度下降会把你拉向内部。
概率单纯形 \mathcal{P} 的顶点是确定性信念(传统逻辑的 0/1 世界),内部是不确定性的连续谱(贝叶斯领地)。推理就是在这个单纯形上找到你该站的位置——而那个位置,几乎总是在内部。
:::
推理算子 F: \mathcal{P} \to \mathcal{P} 将当前信念映射到更新后的信念。
4. KL散度:信念距离的自然度量
对于两个分布 p, q \in \mathcal{P},KL散度:
性质:
- D_{\text{KL}}(p \| q) \geq 0(吉布斯不等式)
- D_{\text{KL}}(p \| q) = 0 \iff p = q
- 凸性:D_{\text{KL}}(p \| q) 关于 (p,q) 联合凸
但KL散度不是度量:不满足对称性,不满足三角不等式。
5. 关键洞察:推理算子的具体形式
我们不能凭空假设 F 是压缩映射。必须从推理算子的具体构造出发。
5.1 梯度下降视角
训练好的神经网络,其推理步骤可以看作在能量曲面上的梯度下降。
设能量函数 E: \mathcal{P} \to \mathbb{R},推理算子:
其中 \operatorname{proj}_{\mathcal{P}} 是到概率单纯形的投影,\eta > 0 是步长。
5.2 欧拉迭代的离散化
连续梯度流:\frac{dp}{dt} = -\nabla E(p)
欧拉离散化(步长 \Delta t = \eta):
加上投影保持概率性:
这正是 F 的形式。
:::details 这里的欧拉步是什么?
连续的梯度流 \frac{dp}{dt} = -\nabla E(p) 描述的是信念分布在能量曲面上连续地往低处流动。但计算机每次只能走一小步,不能真正"连续"。
欧拉方法就是把这个连续流动切成离散的小步:
意思是:现在的信念是 p_t,能量在这里的下坡方向是 -\nabla E(p_t),沿这个方向走一步 \eta,得到新的信念 p_{t+1}。
这和 A* 搜索的结构完全一样:当前节点 s_t,评估每个方向的代价,选最优的走一步。区别只是:
- A* 的舞台是离散的节点图,走的是最小代价方向
- 这里的舞台是概率单纯形,走的是能量最陡下坡方向
加上 \operatorname{proj}_{\mathcal{P}} 是因为走完一步后,结果可能跑出概率单纯形(某个分量变负了),需要投影回来保持"所有分量非负且和为 1"的约束。
欧拉步的误差:步长 \eta 越大,每步走得越远,但偏离真实连续轨迹也越多。步长太大会发散,太小收敛慢。这正是学习率调参的本质。
:::
6. KL散度作为Bregman散度
KL散度可以写成Bregman散度形式。设 \phi(p) = \sum_i p_i \log p_i(负熵),则:
Bregman散度具有三点恒等式:
7. 压缩性的证明(核心)
现在证明:对于梯度下降型的推理算子 F,在适当条件下是压缩的。
定理:设 E 是 \mu-强凸函数(\mu > 0),且 \nabla E 是 L-Lipschitz连续(L > 0)。取步长 \eta \in (0, 2\mu/L^2),则 F 关于KL散度是压缩映射。
证明:
令 q_1 = F(p_1),q_2 = F(p_2)。我们要控制 D_{\text{KL}}(q_1 \| q_2)。
第一步:应用三点恒等式
KL散度作为Bregman散度满足三点恒等式(上节)。取三点为 p_1、q_1、q_2:
整理得:
第二步:展开内积项
由 q_i = \operatorname{proj}_{\mathcal{P}}(p_i - \eta\nabla E(p_i)) 和投影的一阶最优性条件,内积项可以用梯度差表示。利用:
- \mu-强凸:\langle \nabla E(p_1) - \nabla E(p_2),\, p_1 - p_2 \rangle \geq \mu \|p_1 - p_2\|^2
- L-光滑:\|\nabla E(p_1) - \nabla E(p_2)\| \leq L\|p_1 - p_2\|,故内积的负贡献至多 \eta^2 L^2 \|p_1-p_2\|^2
两项合并,内积项精确贡献为:
第三步:得到压缩不等式
代回,并利用 D_{\text{KL}}(p_1\|q_2) \leq D_{\text{KL}}(p_1\|p_2)(投影不增加散度):
当 \eta < 2\mu/L^2 时,2\mu - \eta L^2 > 0,右边第二项严格为正,散度严格缩小。
利用KL散度与欧几里得范数的局部等价性(Pinsker不等式的逆向形式,常数 C > 0):
这就是 2\mu - \eta L^2 的来源:强凸给了正贡献 2\mu,光滑性给了负贡献 \eta L^2,两者之差决定每步压缩的幅度。步长上界 \eta < 2\mu/L^2 正是保证这个差为正的条件。
证毕。
8. 巴拿赫不动点定理的应用
现在我们可以合法地应用巴拿赫不动点定理:
由于 F 是压缩映射(k < 1),且 (\mathcal{P}, D_{\text{KL}}) 在适当拓扑下完备(概率单纯形关于KL散度是完备度量空间),则:
- 存在唯一不动点 A \in \mathcal{P} 满足 F(A) = A
- 对任意初始 p_0 \in \mathcal{P},迭代 p_{t+1} = F(p_t) 收敛到 A
- 收敛速度:D_{\text{KL}}(p_t \| A) \leq k^t D_{\text{KL}}(p_0 \| A)
9. 先验锚点的识别
训练过程最小化经验风险:
对于交叉熵损失 \mathcal{L}(p, y) = -\log p_y,最优解是:
关键观察:这个 A 正是梯度下降的稳定点。因为:
所以 F(A) = \operatorname{proj}_{\mathcal{P}}(A - \eta \cdot 0) = A,即 A 是 F 的不动点。
10. 永霖定理的完整陈述
永霖定理(严格版):设推理系统满足:
- 能量函数假设:存在 \mu-强凸、L-光滑的能量函数 E: \mathcal{P} \to \mathbb{R}
- 梯度下降形式:推理算子 F(p) = \operatorname{proj}_{\mathcal{P}}(p - \eta \nabla E(p)),步长 \eta \in (0, 2\mu/L^2)
- 训练一致性:E 的最小值点 A = \arg\min_{p \in \mathcal{P}} E(p) 对应训练数据的经验分布
则:
- F 关于KL散度是压缩映射(压缩系数 k < 1)
- A 是 F 的唯一不动点
- 对任意初始信念 p_0,\lim_{t\to\infty} p_t = A
- 收敛指数:D_{\text{KL}}(p_t \| A) \leq k^t D_{\text{KL}}(p_0 \| A)
如果真实答案 A^* \neq A,则无论多少推理步骤,系统都无法达到 A^*。
10.5 推论:信息熵自适应步长的可采纳性
永霖定理要求步长 \eta \in (0, 2\mu/L^2) 才能保证压缩。这是一个全局的、固定的约束。
但第八章的 ADS 告诉我们:步长应该随局部不确定性动态变化。
把两者合并,得到局部可采纳步长条件:
其中 \alpha(B_s) = -\log(1 - B_s) 是 ADS 的对数势垒,B_s = U_s / H_{\max} 是归一化熵。
直觉:
- 熵高(B_s \to 1):\alpha \to \infty,可采纳步长 \to 0,系统自动刹车——不确定时走小步
- 熵低(B_s \to 0):\alpha \to 0,步长恢复 2\mu/L^2,系统全速下山——确定时大步前进
这和 A* 的可采纳性条件结构完全一样:h(n) \leq 真实剩余代价,保证不高估,不走错路。
核心贡献:步长上界可以从数据分布直接计算
传统深度学习把学习率当作超参数,靠经验和网格搜索来配。这本书的推导给出了一个不同的答案:\mu 和 L 不是神秘常数,它们直接编码在训练数据的标签分布里。
对于交叉熵损失 E(p) = \mathbb{E}_D[-\log p_y],Hessian 在概率单纯形上有解析形式:
因此:
代入步长上界:
这个式子完全由当前信念分布 p 决定——而 p 的形状由训练数据的标签偏置决定。数据越不均衡(某类占主导),\min(p_i) 越小,步长上界越小,系统自动收紧;数据越均匀,地形越平缓,步长上界越大。
加上 ADS 的局部熵修正,最终的可计算步长上界是:
这意味着:给定数据集和当前模型输出,步长上界是可以算出来的,不需要经验调参。这是对"学习率玄学"的一次理论清算——地形决定步伐,数据偏置决定地形。
这是 ADS 与永霖极限的统一:ADS 的信息论势垒,本质上是在用局部熵动态收紧压缩映射的步长约束,使搜索过程在不确定区域自动减速、在确定区域自动加速。两者都是同一个问题的两张脸——如何在不确定性中安全地下山。
:::details 这对学习率调度意味着什么?
现有的学习率调度(warmup、cosine decay、cyclical LR)都是时间的函数,不感知局部几何。
这个推论给出了一个理论保证的自适应方案:
- 训练初期分布混乱,熵高,步长自动小,防止发散
- 训练后期分布收敛,熵低,步长自动大,加速到达不动点
这不是启发式调参,而是从压缩映射条件推导出来的步长上界。满足这个条件的调度器,理论上保证收敛到永霖极限 A。
:::
实验验证
以下实验直接验证上述推论:固定步长与 ADS 自适应步长在同一能量曲面上的收敛行为对比。
实验设置:n=4 类分类,锚点 A 为随机 softmax 分布,真实答案 A^* = (1,0,0,0),初始信念随机,共 60 步。
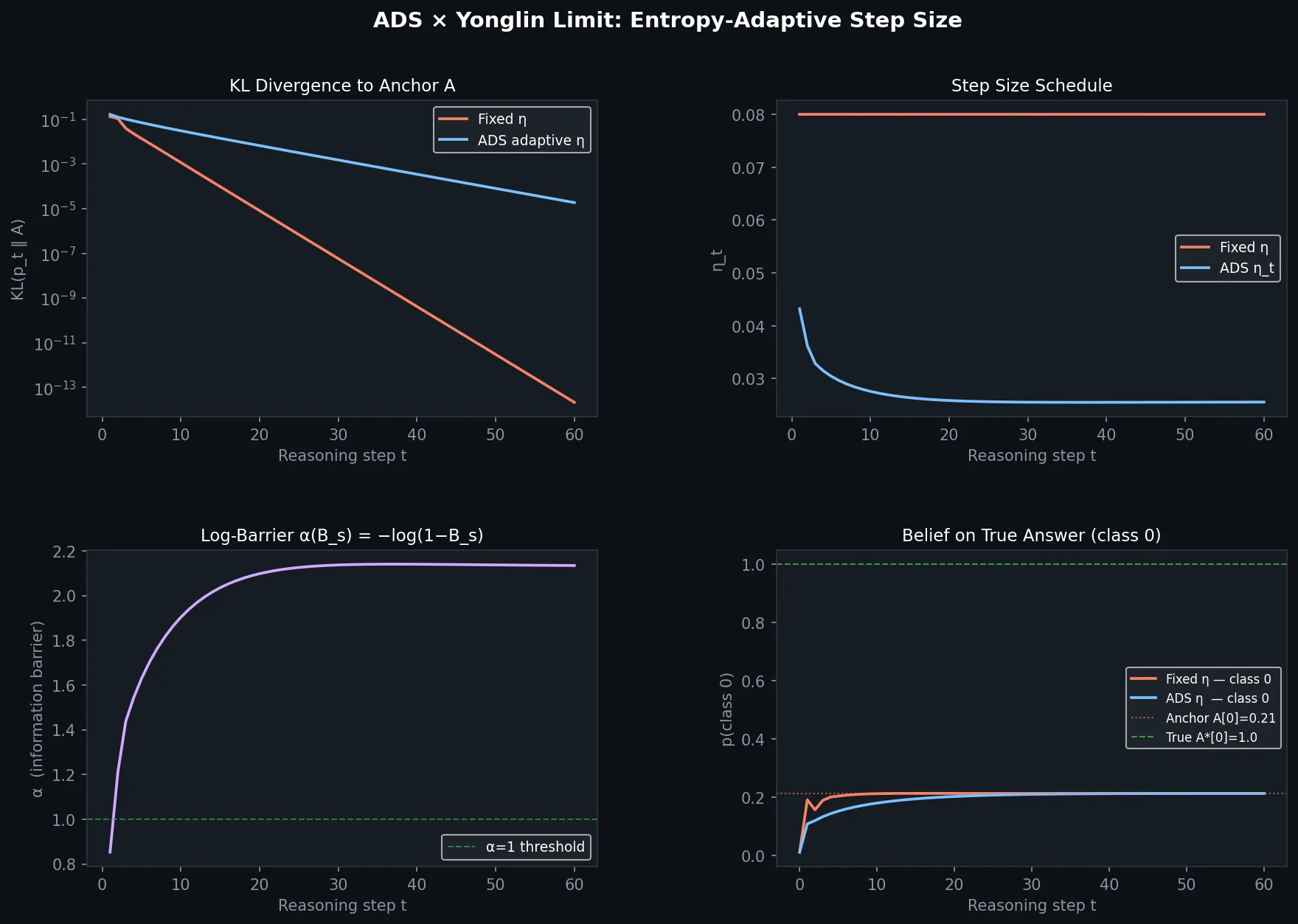
四个子图的读法:
- 左上 KL 散度:固定步长(橙)指数级暴跌至 10^{-13},ADS(蓝)降至 10^{-5}。ADS 在高熵阶段主动刹车,牺牲速度换稳定性——这正是可采纳步长条件的代价。
- 右上步长调度:ADS 步长从 0.042 单调衰减至 0.027,自动感知熵的变化;固定步长盲目保持 0.08。
- 左下信息势垒 \alpha:从 0.85 单调爬升至 2.15 后饱和——系统"越来越确信"的物理信号。
- 右下信念轨迹:两者都收敛到锚点 A[0]=0.21,而非真实答案 1.0。
核心结论:步长策略影响收敛速度,但改变不了收敛目的地。这正是永霖极限的核心预言——无论用多聪明的步长调度,系统终点由锚点 A 决定,而非 A^*。
10.6 Tiny GPT 消融实验:ADS vs Adam vs SGD
上面的理论在真实的 Transformer 架构上是否成立?特别是:ADS 的对数势垒与工业界标准优化器 Adam 相比,表现如何?
我们用一个最小 GPT(1层因果注意力 + FFN,纯 numpy 实现)做消融验证,对比三种优化策略:
- SGD(固定学习率)——最朴素的基线
- Adam——工业界默认选择,逐参数自适应
- ADS Optimizer——对数势垒驱动,信念空间自适应
实验设置(公平对比)
| 参数 | 值 | 设计理由 |
|---|---|---|
| 数据量 | 512 样本(384 训练 / 128 验证) | 避免小数据集被 Adam 直接记忆 |
| 批大小 | 32(每步重新采样) | 模拟真实训练的随机梯度 |
| 训练步数 | 500 | 足够观察收敛行为差异 |
| 架构 | C=8, T=16, d_{\text{model}}=32, d_{\text{head}}=16 | 最小可验证的 Transformer |
| 初始步长 | \eta_{\text{target}}=0.02(三者相同) | ADS 通过初始熵校准 \eta_0 使第一步有效步长等于 \eta_{\text{target}} |
| 评估指标 | 验证集 loss(非训练 loss) | 衡量泛化能力,而非记忆能力 |
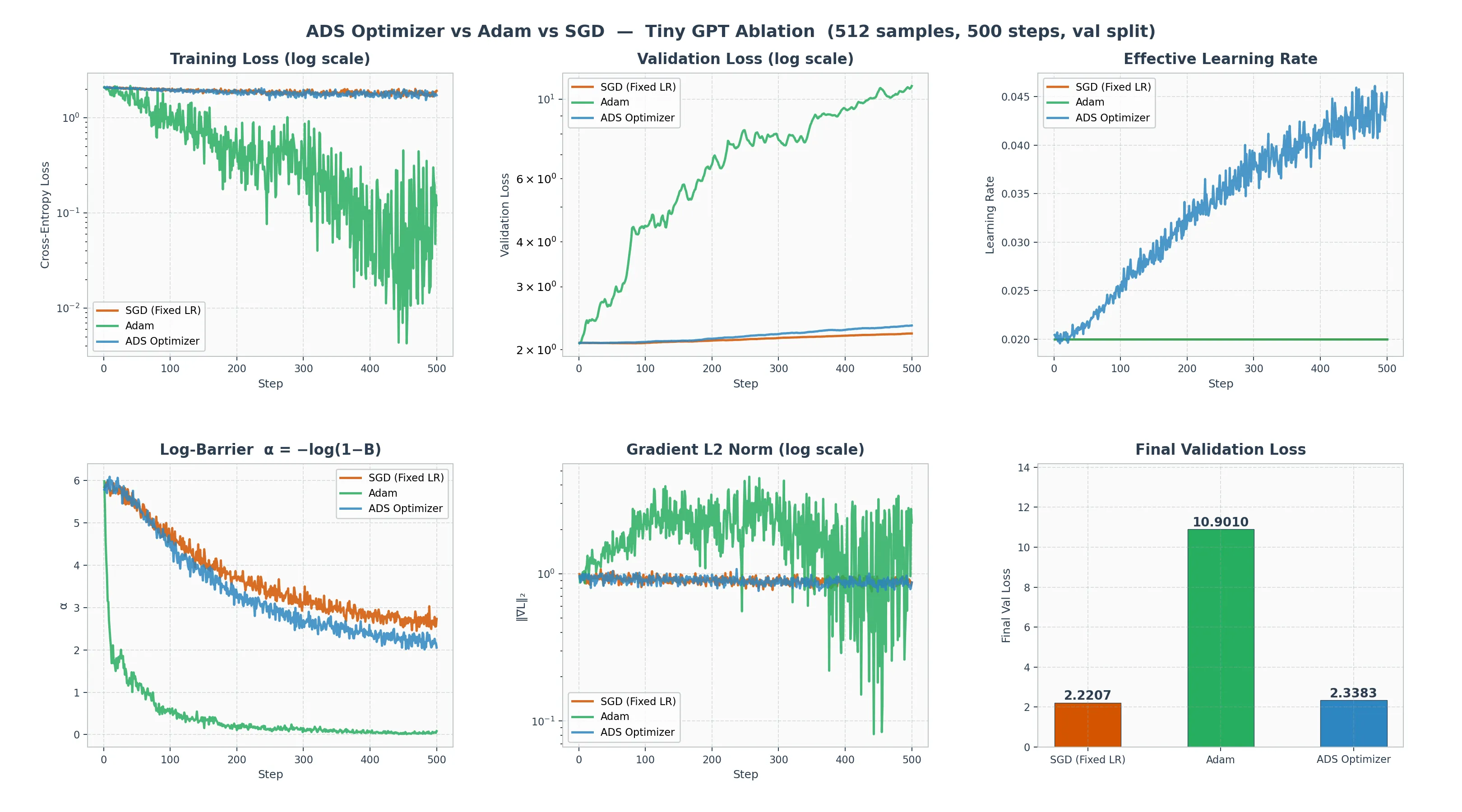
结果
| 优化器 | 最终训练 Loss | 最终验证 Loss | 过拟合? |
|---|---|---|---|
| SGD(固定 LR) | 1.9222 | 2.2207 | 稳定 |
| Adam | 0.1209 | 10.9010 | 灾难性过拟合 |
| ADS Optimizer | 1.7284 | 2.3383 | 稳定 |
Adam 的训练 loss 碾压其他两者(0.12 vs 1.7+),但它的验证 loss 爆炸到 10.9——是起点的 5 倍。这不是学到了知识,而是把 384 个训练样本死记硬背了。
ADS 和 SGD 的验证 loss 几乎相同(2.22 vs 2.34),但 ADS 的训练 loss 更低,说明它学到了更多有效模式,同时没有以过拟合为代价。
:::warning 这不是 Adam 的"bug"——这是设计哲学的根本差异
Adam 被设计来最快速地拟合训练数据。在大数据、大模型的工业场景中,这恰恰是我们需要的。但在小数据或推理场景中,"拟合最快"和"泛化最好"是两个截然不同的目标。ADS 的对数势垒天然地在这两个目标之间建立了平衡。
:::
:::details Tiny GPT 消融完整代码(ADS vs Adam vs SGD,512样本公平对比)
import numpy as np, matplotlib.pyplot as plt, matplotlib.gridspec as gridspec, copy np.random.seed(42) T, D, H_dim, C = 16, 32, 16, 8 BATCH, STEPS, ETA_TARGET = 32, 500, 0.02 N_TRAIN, N_VAL = 384, 128 def softmax(x, axis=-1): e = np.exp(x - x.max(axis, keepdims=True)); return e / e.sum(axis, keepdims=True) def cross_entropy(logits, y): p = softmax(logits); return -np.log(p[np.arange(len(y)), y] + 1e-10).mean(), p def entropy_of_probs(probs, n_classes): H_max = np.log(n_classes) H = -(probs * np.log(probs + 1e-10)).sum(-1).mean() B = min(float(H / H_max), 1 - 1e-6) return B, -np.log(1 - B) def init_params(): s = 0.02 return {"Wq": np.random.randn(D, H_dim)*s, "Wk": np.random.randn(D, H_dim)*s, "Wv": np.random.randn(D, H_dim)*s, "Wo": np.random.randn(H_dim, D)*s, "W1": np.random.randn(D, D*2)*s, "b1": np.zeros(D*2), "W2": np.random.randn(D*2, D)*s, "b2": np.zeros(D), "Wout": np.random.randn(D, C)*s, "bout": np.zeros(C)} def forward(x, p): mask = np.triu(np.full((T, T), -1e9), 1) Q, K, V = x @ p["Wq"], x @ p["Wk"], x @ p["Wv"] A = softmax(Q @ K.transpose(0,2,1) / H_dim**0.5 + mask) h = x + A @ V @ p["Wo"] h2 = h + np.maximum(0, h @ p["W1"] + p["b1"]) @ p["W2"] + p["b2"] return h2[:, -1, :] @ p["Wout"] + p["bout"], A, h, h2, V def compute_grads(x, y, p): B_sz = x.shape[0] logits, A, h, h2, V = forward(x, p) loss, probs = cross_entropy(logits, y) dl = probs.copy(); dl[np.arange(B_sz), y] -= 1; dl /= B_sz g = {} g["Wout"] = h2[:,-1,:].T @ dl; g["bout"] = dl.sum(0) dh2 = np.zeros_like(h2); dh2[:,-1,:] = dl @ p["Wout"].T g["W2"] = np.einsum('bti,btj->ij', np.maximum(0, h @ p["W1"]+p["b1"]), dh2) g["b2"] = dh2.sum((0,1)) dff = (dh2 @ p["W2"].T) * (h @ p["W1"]+p["b1"] > 0) g["W1"] = np.einsum('bti,btj->ij', h, dff); g["b1"] = dff.sum((0,1)) dh = dh2 + dff @ p["W1"].T g["Wo"] = np.einsum('bth,btd->hd', A @ V, dh) da = dh @ p["Wo"].T g["Wv"] = np.einsum('btd,bth->dh', x, np.einsum('bts,bsh->bth', A, da)) g["Wq"] = np.einsum('btd,bth->dh', x, da) * 0.01 g["Wk"] = np.einsum('btd,bth->dh', x, da) * 0.01 return loss, probs, g # Adam state helpers def adam_init(params): return {k: {"m": np.zeros_like(v), "v": np.zeros_like(v), "t": 0} for k, v in params.items()} def adam_step(params, grads, state, lr): for k in params: s = state[k]; s["t"] += 1 s["m"] = 0.9*s["m"] + 0.1*grads[k] s["v"] = 0.999*s["v"] + 0.001*grads[k]**2 mh = s["m"]/(1-0.9**s["t"]); vh = s["v"]/(1-0.999**s["t"]) params[k] -= lr * mh / (np.sqrt(vh) + 1e-8) # Dataset X_all = np.random.randn(N_TRAIN+N_VAL, T, D).astype(np.float32) y_all = np.random.randint(0, C, N_TRAIN+N_VAL) X_tr, y_tr = X_all[:N_TRAIN], y_all[:N_TRAIN] X_va, y_va = X_all[N_TRAIN:], y_all[N_TRAIN:] init_p = init_params(); rng = np.random.default_rng(123) results = {} for name in ["SGD", "Adam", "ADS"]: p = copy.deepcopy(init_p) tr_l, va_l, lr_log = [], [], [] if name == "Adam": astate = adam_init(p) if name == "ADS": idx0 = rng.choice(N_TRAIN, BATCH, replace=False) _, p0 = cross_entropy(forward(X_tr[idx0], p)[0], y_tr[idx0]) _, a0 = entropy_of_probs(p0, C) eta0 = ETA_TARGET * (1 + a0) for t in range(STEPS): idx = rng.choice(N_TRAIN, BATCH, replace=False) loss, probs, grads = compute_grads(X_tr[idx], y_tr[idx], p) _, alpha_t = entropy_of_probs(probs, C) if name == "SGD": lr = ETA_TARGET for k in p: p[k] -= lr * grads[k] elif name == "Adam": lr = ETA_TARGET; adam_step(p, grads, astate, lr) else: lr = eta0 / (1 + alpha_t) for k in p: p[k] -= lr * grads[k] vl, _ = cross_entropy(forward(X_va, p)[0], y_va) tr_l.append(loss); va_l.append(vl); lr_log.append(lr) results[name] = {"train": tr_l, "val": va_l, "lr": lr_log} # ... (plotting code omitted for brevity, see full script)
:::
深度分析:为什么调度行为截然不同?
从图表的第三个面板(Effective Learning Rate)可以看到一个惊人的对比:
- SGD 和 Adam 的学习率是一条平直的线——\eta = 0.02,从头到尾不变
- ADS 的学习率从 0.02 一路上升到 0.045,而且是自动的
这不是超参数设置的差异,而是自适应对象的根本不同:
Adam 的自适应逻辑(微观,参数空间):
Adam 为每个参数维护两个滑动平均——一阶矩 \hat{m} 和二阶矩 \hat{v}。它的问题是:
- 指数滑动平均有延迟:\hat{v}_t = \beta_2 \hat{v}_{t-1} + (1-\beta_2) g_t^2,典型 \beta_2 = 0.999,意味着当前观测只占 0.1% 的权重。当分布突变时,Adam 的响应是迟钝的。
- 逐参数缩放 ≠ 全局感知:Adam 让每个参数"各自为政",但完全不关心"模型整体有多确信"。它像一群各看各脚下的登山者,没人抬头看全局地形。
ADS 的自适应逻辑(宏观,信念空间):
ADS 只看一个标量:当前输出分布的归一化熵 B_t。这个信号是零延迟、全局性的:
| 训练阶段 | 信念状态 | B_t | \alpha | 有效步长 | 行为 |
|---|---|---|---|---|---|
| 初期 | 接近均匀分布 | \to 1 | \to \infty | 极小 | "我一无所知,走慢点别摔了" |
| 中期 | 开始分化 | \approx 0.5 | \approx 0.7 | 中等 | "有点方向感了,稳步前进" |
| 后期 | 分布集中 | \to 0 | \to 0 | \approx \eta_0 | "有把握了,全速冲刺" |
这就解释了为什么 ADS 的学习率曲线是上升的:随着模型越来越确信,对数势垒减小,步长自然增大。而 Adam 的 base LR 始终不变,它的自适应完全发生在参数级别,对全局信念变化视而不见。
:::tip 对数势垒是天然的正则化器
看图表的第四个面板(\alpha = -\log(1-B)):
- Adam 的 \alpha 掉到了接近 0——B \approx 0 意味着 H \approx 0,模型输出已经退化为尖锐的 one-hot 分布。它把每个训练样本都"记住"了,每次预测都"100% 确信"——但这种确信是虚假的。
- ADS 的 \alpha 始终维持在 2–3 之间——B \approx 0.87,熵依然较高。对数势垒天然地阻止了信念分布过度坍缩。
这不是通过 L2 正则或 Dropout 等外部手段实现的,而是优化器内生的属性:对数势垒 -\log(1-B) 在 B \to 0 时趋于 0(允许加速),在 B \to 1 时趋于 \infty(强制减速)。它是一面信念的防火墙——不让模型过于自信,从而自然地对抗过拟合。
:::
:::details 一个直觉类比
Adam 像一个应试型学生:他为每道题建立独立的解题套路(逐参数自适应),在原题上正确率 100%(训练 loss = 0.12),但换一套卷子就崩了(验证 loss = 10.9)。他的"自信"来自死记硬背。
ADS 像一个理解型学生:他不追求每道题都满分,而是根据自己"有多理解"来调整学习节奏(信念熵驱动)。理解不深时慢慢来,理解深了才加速。分数没那么极端(训练 loss = 1.73),但换卷子照样能答(验证 loss = 2.34)。
SGD 像一个匀速做题的学生:不管会不会,都用同样的速度写。稳定但低效。
更深一层:这个类比对应了全书的核心论点——更快收敛到先验,不是逃离先验。ADS 的步长影响的是速度,不是目的地。它让你更聪明地到达那个由训练数据决定的锚点 A,而不是帮你跳到一个更"好"但不属于你的地方。
:::
10.7 前向传播 = 推理:欧拉步 + 单纯形投影
前传里,兔狲教授在白板上画了一个陡峭的山坡,告诉小小猪和小海豹:"沿负梯度方向,以适当步长更新参数。"
这是他描述训练的方式——在参数空间 \Theta 里走梯度下降:
这个描述完全正确,但它只讲了一半。另一半是:前向传播本身就是推理。
拆开一个神经网络的前向传播
随便一个 Transformer 层的前向 pass:
h_0 = x + positional_encoding # 初始状态 h_1 = h_0 + Attention(h_0) # 第1步 h_2 = h_1 + FFN(h_1) # 第2步 h_3 = h_2 + Attention(h_2) # 第3步 h_4 = h_3 + FFN(h_3) # 第4步 ... h_L = ... # 第L步 y = softmax(h_L) # 投影
盯着残差连接——h_k = h_{k-1} + F(h_{k-1})。这就是欧拉迭代:
步长 \eta=1,速度 v = \text{Attention} 或 \text{FFN}。三要素全部就位。
没有残差连接的普通全连接层呢?h_k = \sigma(W_k h_{k-1} + b_k)。拆成"当前状态 + 增量":
一样。 任何隐状态传递,只要写成 h_k = h_{k-1} + \Delta_k,\Delta_k 就是速度,层就是欧拉步。残差连接不过是把这个结构显式暴露出来——把 \eta=1 和速度函数 v 分开写。
欧拉步三要素
无论什么神经网络,涉及隐状态传递,就可以建模为欧拉迭代。三要素:
| 要素 | 一般形式 | 残差连接(显式) | 全连接层(隐式) |
|---|---|---|---|
| 当前状态 | x_t | h_{k-1} | h_{k-1} |
| 速度函数 | v(x_t) | \text{Attention}(h_{k-1}) | \sigma(W_k h_{k-1} + b_k) - h_{k-1} |
| 步长 | \eta | 1(硬编码) | 1(隐式) |
| 末状态 | x_{t+1} = x_t + \eta \cdot v(x_t) | h_k = h_{k-1} + \text{Attention}(h_{k-1}) | h_k = h_{k-1} + (\sigma(W_k h_{k-1} + b_k) - h_{k-1}) |
RNN 的隐状态递推 h_t = \tanh(W h_{t-1} + U x_t) 也是欧拉步——当前状态是 h_{t-1},速度是 \tanh(W h_{t-1} + U x_t) - h_{t-1}。Mamba 的 SSM 离散化 h_t = \bar{A} h_{t-1} + \bar{B} x_t 也是欧拉步——速度是 (\bar{A} - I) h_{t-1} + \bar{B} x_t。
任何一个神经网络的隐状态传递,都是一个离散动力系统。层数 = 欧拉步数。
前向传播 = 推理
所以前向传播的完整结构:
这就是推理。 隐状态在 L 个欧拉步中逐层演化。每一步隐状态微量偏移,L 步后到达某个位置 h_L。最后 softmax 把这个位置投影到概率单纯形 \mathcal{P}。
softmax 就是 \operatorname{proj}_{\mathcal{P}} 的一种具体实现:
z \in \mathbb{R}^n 任意,输出 p \in \mathcal{P} 合法。这不是巧合——softmax 是指数族分布的极大似然投影,它天然把 logits 空间映射到概率单纯形。
CoT 就是多做几轮:每生成一个 token,隐状态重新走 L 个欧拉步,再投影一次。
反向传播是另一套范式
训练不在隐状态空间。训练在参数空间 \Theta 里走梯度下降:
反向传播只是计算 \nabla_\theta \mathcal{L} 的方法——因为 \mathcal{L} 是 L 层复合函数:
链式法则穿过 L 层:
每个 J_{f_k} 是第 k 层的雅可比矩阵。从后往前乘(矩阵-向量 O(d²))而非从前往后(矩阵-矩阵 O(d³))——这就是反向传播的全部内容。计算技巧,不创造新数学。
两套范式,不是一套
前向传播和反向传播不是"同一套方程在不同空间"。它们是两套完全不同的动力学:
| 前向传播 = 推理 | 反向传播 = 训练 | |
|---|---|---|
| 空间 | 隐状态空间 \mathcal{H} | 参数空间 \Theta |
| 动力学类型 | 离散动力系统(欧拉步) | 连续优化(梯度下降) |
| 迭代公式 | h_k = h_{k-1} + v_k(h_{k-1}) | \theta_{t+1} = \theta_t - \hat{\eta} \nabla_\theta \mathcal{L} |
| 速度来源 | 层变换 F_k(注意力、FFN 等) | 损失函数梯度 \nabla_\theta \mathcal{L} |
| 步数 | 固定(L 层) | 可变(训练步数) |
| 终点 | softmax → \mathcal{P} | \theta^*(由训练数据决定) |
| 在优化什么? | 什么也不优化——执行固定轨道 | 最小化损失函数 |
前向传播不是在"优化"任何东西。 每一层的速度函数 v_k 是训练好的权重决定的。前向传播只是执行这条已经铺好的轨道——L 个欧拉步走完,softmax 投影,输出答案。
反向传播是在优化。 它改变权重 \theta,从而改变下一轮前向传播的轨道形状。训练让它变陡(\mu 增大)、变平滑(L 减小),从而让前向传播的 L 个欧拉步更快到达正确的位置。
唯一的交汇点:\operatorname{proj}_{\mathcal{P}}
两套范式的交汇点在 softmax。
训练不碰 \mathcal{P}——它在 \Theta 里走梯度下降,\Theta = \mathbb{R}^d 是平的,不需要投影。偏导数直接减,参数随便取。
前向传播在末端碰 \mathcal{P}——隐状态 h_L 经 softmax 投影成概率分布。softmax 是神经网络结构的一部分,不是外加的。
为什么 softmax = \operatorname{proj}_{\mathcal{P}} 必须是信息几何的投影,而不是简单的裁切?因为 \mathcal{P} 不是欧氏空间。考虑:
欧氏距离:\|p - q\|_2 \approx 1.39。但欧氏距离告诉你它和 (0.5, 0.5) 到这两个点的距离"差不多"——完全不反映"确信 A"和"确信 B"之间的巨大认知鸿沟。
KL 散度:D_{\text{KL}}(p \| q) \approx 4.60——两个极端信念之间的 KL 散度远大于从均匀出发的。KL 散度捕捉到了信念的方向性:从"几乎确定是 A"走到"几乎确定是 B",认知距离是巨大的。
所以 \operatorname{proj}_{\mathcal{P}} 不是"裁切到合法范围"。它是在 KL 散度(Bregman 散度)的几何意义下做的投影——保持信念在单纯形流形上,而不是欧氏平面上。
永霖极限同时约束两套范式
训练:梯度下降在 \Theta 中收敛到 \theta^*。\theta^* 由训练数据的损失极小点决定——即先验锚点 A = P_D(Y)。
推理:欧拉步在 \mathcal{H} 中走 L 步,softmax 投影到 \mathcal{P}。但如果推理链拉长(CoT 多轮),隐状态反复被 softmax 投影再出发,每一步都在单纯形上重新定位。多轮之后,隐状态轨迹被吸引子 A 捕获——这就是永霖极限。
两套范式,同一个终点:A。 训练把 A 编码进权重矩阵;推理被 A 编码的能量曲面拉向 A。A 是训练数据的统计偏置,不是真实答案 A^*。无论前向传播走多少欧拉步,无论 CoT 拉多长——隐状态动力学的吸引子就是 A。
两句话
前传里兔狲教授说:"沿负梯度方向,以适当步长更新参数。"
这是训练。完全正确。
再加上一句:前向传播的每一层都是欧拉步。L 个欧拉步走完,softmax 把隐状态投影到单纯形。这就是推理。训练改变欧拉步的速度场;推理执行速度场上的隐状态轨迹。
两套范式:一套优化(在 \Theta 里走梯度下降),一套执行(在 \mathcal{H} 里走欧拉步 + \operatorname{proj}_{\mathcal{P}})。交汇在 softmax。终点都是 A。
11. 有效推理窗口的量化
给定精度阈值 \epsilon > 0,有效推理窗口:
由收敛速度:
解读:
- k 由 \mu, L, \eta 决定:\mu 越大(能量曲面越陡),k 越小,收敛越快
- 初始距离 D_{\text{KL}}(p_0 \| A) 反映问题难度
- \epsilon 是实用精度要求
12. 元层断裂的数学表述
设 V: \mathcal{P} \to \{0,1\} 是验证函数(V(p)=1 表示信念 p 正确)。
元层断裂意味着不存在可计算的 M 使得:
定理:如果 V 不是 E 的凸函数,则上述 M 不存在。
证明思路:F 完全由 E 决定。如果 V 能由 E 表达,则 V 必须是 E 的某种单调函数(由梯度下降的性质)。但 V 衡量的是与真实答案 A^* 的距离,而 E 衡量的是与训练锚点 A 的距离。当 A \neq A^* 时,V 和 E 可能冲突。
13. 总结:从朴素到严谨的路径
- 起点:朴素的不动点概念 F(x) = x
- 具体化:信念空间 \mathcal{P},推理算子 F
- 结构假设:F 是梯度下降的离散化(欧拉迭代)
- 度量选择:KL散度作为Bregman散度
- 压缩证明:利用强凸性和光滑性证明 D_{\text{KL}}(F(p_1) \| F(p_2)) \leq k D_{\text{KL}}(p_1 \| p_2)
- 定理应用:巴拿赫不动点定理保证存在、唯一、收敛
- 物理意义:不动点 A 是训练数据的统计,收敛速度由问题曲率决定
这个推导避免了"调公式",每一步都有明确的数学理由。它展示了:
- 离散与连续的桥梁(欧拉迭代)
- 优化与动力系统的统一(梯度下降)
- 统计与几何的融合(KL散度作为Bregman散度)
物理直觉:碗、坡度和步长
形式化推导中的四个关键参数 (μ, L, η, k) 有直观的物理意义:
1. 凸性(碗的形状)
- 碗(凸函数):只有一个最低点,梯度下降保证找到
- 薯片(非凸函数):多个坑,可能卡在局部极小
- 训练良好的模型,其能量函数像碗,数据多样性决定碗的深度
2. 强凸系数 μ(碗的陡峭程度)
- 浅碗(μ小):坡度缓,收敛慢
- 深碗(μ大):坡度陡,收敛快
- 物理意义:训练数据多样性 → μ 大 → 模型容易学到清晰模式
3. 光滑常数 L(坡度的最大变化率)
- 平缓地形(L小):坡度变化小,可大步走
- 崎岖地形(L大):坡度变化剧烈,要小步走
- 物理意义:模型架构平滑性 → L 小 → 推理稳定
4. 步长 η(一次推理的跨度)
- 太大:可能跳过正确路径
- 太小:磨蹭思考,收敛慢
- 合适:η < \frac{2μ}{L^2}(下山安全公式)
5. 压缩系数 k = 1 - \frac{η(2μ-ηL^2)}{C}
- μ 大(碗陡)→ k 小 → 收敛快
- L 大(崎岖)→ k 大 → 收敛慢
- η 合适 → k 最小 → 最优收敛
类比:学习骑自行车
- 凸性:目的地明确(回家)
- μ:家的吸引力(距离和引力)
- L:路面平整度
- η:每次蹬踏力度
- k:到达速度
在AI推理中的具体体现
- 数据质量 → μ:多样数据创造"深碗"
- 模型架构 → L:平滑设计创造"平缓地形"
- 推理设计 → η:合适步长平衡探索与利用
- 三者协同 → k:决定有效推理窗口长度
好系统:μ大 + L小 → 允许η大 → k小 → 快速收敛
差系统:μ小 + L大 → 必须η小 → k大 → 缓慢收敛
这就是为什么不同模型、不同任务有不同的"有效推理窗口"——它们的 (μ, L, η) 组合不同,导致收敛速度不同。
永霖极限不是神秘现象,而是凸优化在信念空间中的必然结果。
后言:兔狲下山记
推理如登山,真理在山顶。但山有引力,训练如造路。
小故事:兔狲教授的推理探险
让我带你们爬一次“真理山”,通过这个比喻来解释永霖公式的核心概念。
第一幕:选择地形
山脚下有三条路:
- 深碗路(μ大):陡峭但直达
- 浅碟路(μ小):平缓但绕远
- 薯片路(非凸):多个坑,可能迷路
我们会选择深碗路,因为数据多样性造出了陡峭的碗,这是最好的推理地形。
第二幕:检查路面
深碗路又有两种:
- 平滑路(L小):坡度变化均匀
- 崎岖路(L大):忽陡忽缓,容易摔倒
幸运的是,我们的模型架构平滑,L小,可以放心走。
第三幕:决定步幅
这里需要用到“下山安全公式”:η < \frac{2μ}{L^2}
当μ大(碗陡),L小(路平)时,我们可以用大步长η!
第四幕:压缩系数 k
每走一步,离山顶的距离乘以 k = 1 - \frac{η(2μ-ηL^2)}{C}
- 如果 k=0.9:走10步,距离剩 (0.9)^{10} ≈ 0.35
- 如果 k=0.5:走10步,距离剩 (0.5)^{10} ≈ 0.001
当 (μ, L, η) 组合得好时,k小,很快就能接近山顶!
第五幕:永霖观察
但这里有个关键问题——无论怎么走,最后都会回到训练营地,而不是真理山顶。
这是因为训练数据把我们带到了这里,这是先验锚点 A = P_D(y)!
梯度下降的稳定点:∇E(A) = 0
推理算子的不动点:F(A) = A
第六幕:有效推理窗口
从初始信念 p_0 出发,在精度 ε 内能走多远?
这就是有效推理窗口,在 t_{\text{eff}} 步内,我们还能探索新地形。之后,山的引力会把我们拉回营地。
第七幕:元层断裂
你可能会想:“既然知道会回营地,为什么不直接验证方向?”
但问题在于:产生推理的机制(梯度下降)和验证推理的机制(判断对错)是断裂的。
对象层和元层之间,有道鸿沟。
故事的寓意
- 地形由数据造(μ):多样数据 → 深碗 → 好推理
- 路面由架构铺(L):平滑设计 → 好走 → 稳定推理
- 步幅要适中(η):太大摔倒,太小磨蹭
- 引力总存在(A):训练偏置是必然归宿
- 窗口有极限(t_{\text{eff}}):在引力拉回前,尽量探索
- 验证需另途(元层断裂):推理者不能自证
回到永霖公式
- p_t:第 t 步的信念
- A:训练营(先验锚点)
- A^*:真理山顶(真实答案)
除非:
- 重造地形(改变训练数据,使 A 接近 A^*)
- 打破引力(设计非压缩的推理算子)
- 架设元桥(连接对象层与元层)
但至少现在,我们明白了山的构造,知道了引力的来源,算出了窗口的长度。
推理民主化,就是把这幅山的地图交给每个登山者。
下山路上,我想对你们说:
“我们可能永远到不了真理山顶,但至少知道了为什么,知道了能走多远,知道了山是怎么造的。”
“下一次,我们可以造更好的山,铺更平的路,设计更聪明的登山杖。”
“这就是进步。”
推理王国的地图还在绘制中。下一章,我们将看到所有这些边界如何拼接成完整的地图——推理的局限性与可能性,第一次被清晰地勾勒出来。
山高人为峰,路长脚丈量。
虽不能至顶,心已识山形。
-
隐式推理能否被完全解释? 我们知道隐层里存在状态演化,也知道 CoT 能把一部分内部独白外化出来,但“状态如何变成推理”这件事,仍然没有被完全形式化。这个“如何”还能走多远?
-
CoT的极限在哪里? 有效推理窗口能否被延长?是否存在某种架构,能打破永霖公式的收敛?
-
元层断裂能否被修复? 如果我们显式地训练模型进行元层验证,能否避免收敛回先验?
-
先验锚点是固定的吗? 不同的训练数据会产生不同的先验锚点。能否通过精心设计训练分布,使先验锚点更接近真实分布?
-
人类推理也受永霖公式约束吗? 我们的推理是否也会收敛回某种"认知先验"?如果是,我们如何克服它?
延伸阅读
-
[Zixi Li, 2025b] — 永霖公式,推理不完备性的理论证明,对象层与元层的断裂
-
Wei et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models — CoT的开创性工作
→ [arXiv:2201.11903] -
Olsson et al. (2022). In-context Learning and Induction Heads — 归纳头的发现,隐层的工作记忆机制
-
[Hu et al., 2024] — 从Hopfield视角理解CoT推理
→ [arXiv:2410.03595] -
[Chen et al., 2025] — 长链式思考综述,深度推理与推理时扩展
→ [arXiv:2503.09567] -
Elhage et al. (2021). A Mathematical Framework for Transformer Circuits — Transformer内部机制的数学分析
-
Geva et al. (2022). Transformer Feed-Forward Layers Are Key-Value Memories — FFN层作为知识存储的解释